1、实时数仓ODS设计
实时数仓分层介绍
普通实时计算与实时数仓比较
普通实时
普通的实时计算优先考虑时效性,所以从数据源采集经过实时计算直接得到结果。如此做时效性更好,但是弊端是由于计算过程中的中间结果没有沉淀下来,所以当面对大量实时需求的时候,计算的复用性较差,开发成本随着需求增加直线上升。

什么意思呢:就是从数据源获取的数据,如果有几条计算流程,那么就分几次计算,但是有个问题,这几条计算流程中,可能存在很多的重复计算,这也是传统的实时计算存在的缺点,因为考虑了实时性,必然需要牺牲复用性,中间没有保存计算结果。
实时数仓
实时数仓基于一定的数据仓库理念,对数据处理流程进行规划、分层,目的是提高数据的复用性。
下面这张图是实时数仓,最重要的一个概念是分层,不仅是数据的分层,那么在计算层面,也进行分层操作,提取出共有的计算操作,然后独立出不同的计算部分,这样可以减少很多的重复计算量。
最大的好处是提高复用性。但是随之带来的缺点是影响时效性。因为需要存储中间的计算结果,可能为了保证数据的安全,出现错误可以恢复,还要进行落盘处理。
为什么会影响时效性,因为在a计算完成后,需要把结果进行保存,然后供计算流程b和c共同使用,之所以需要缓存数据,所以时效性不好。而在实时计算中就不需要考虑保存中间结果。
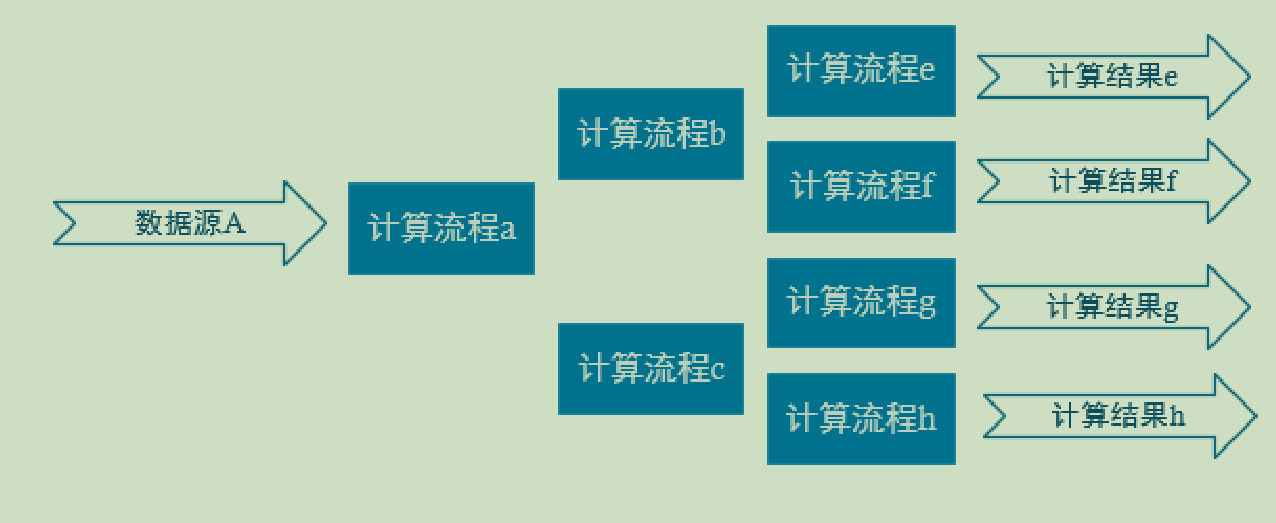
实时数仓分层介绍
ODS
原始数据,日志和业务数据,这些数据是存放在kafka中,因为实时数据需要低延迟,应对实时的业务。
在离线数仓中,我们的数据元数据信息存在mysql中,而真实的数据存储在hdfs上面,因为不需要保证实时性。
在ods层:
行为数据存储在ods_base.log文件中
业务数据存储在ods_base_db中
DWD
我们一般将业务数据的实时表存放在DWD层,这个数据我们是存放在kafka中,而将维度数据存放在dim层,维度数据一般存放在hbase中。
dwd和dim是同一层,只不过存储的位置不一样
根据数据对象为单位进行分流,比如订单、页面访问等等,在Flink中,我们是根据测输出流进行分流处理。我们把事实表存放在DWD层。
我们为什么没有把维度数据存放在kafka中,有两个原因:
- 因为当一条数据来了之后,我们需要使用实时表中的数据去关联维度表,然后在补充实时表,但是kafka中的数据存放时间有时限,是7天,会定期进行删除,但是我们的维度表数据不能进行删除,所以我们选择将维度表数据存放在Hbase中,一般对于维度表,我们需要长期存储。
- 第二个原因是根据ID去kafka中查找数据,很困难,所以并不能将数据存放在kafka中。
DIM
维度数据
dwd和dim是属于同一层的,只是存储的位置和内容不一样
dwd层存储的是事实表,存储在kafka,dim层存储维度表数据,存储在Hbase。
DWM
对于部分数据对象进行进一步加工,比如独立访问、跳出行为,也可以和维度进行关联,形成宽表,依旧是明细数据。
对dwd和DIM过程中形成的通用的数据抽取出来,形成DWM层。
存储在Kafka中。因为其还要进行加工形成dws层,有些dwd,dim数据也可以直接形成dws层数据。
之所以抽象处dwm层,是为了抽象出一张明细宽表数据,位置后的即席查询做准备。
DWS
根据某个主题将多个事实数据轻度聚合,形成主题宽表。这部分数据是需要最终的查询,所以放在ClickHouse数据库中。
这一部分的数据可以存放到mysql数据库中么?
ADS
把ClickHouse中的数据根据可视化需进行筛选聚合,这一部分是实时数据,不进行落盘,主要是对数据进行聚合操作。
离线计算与实时计算的比较
离线计算
就是在计算开始前已知所有输入数据,输入数据不会产生变化,一般计算量级较大,计算时间也较长。例如今天早上一点,把昨天累积的日志,计算出所需结果。最经典的就是 Hadoop 的 MapReduce 方式;
一般是根据前一日的数据生成报表,虽然统计指标、报表繁多,但是对时效性不敏感。
从技术操作的角度,这部分属于批处理的操作。即根据确定范围的数据一次性计算,计算的中间结果不会保存,有新数据到来,会从头开始计算。
实时计算
输入数据是可以以序列化的方式一个个输入并进行处理的,也就是说在开始的时候并不需要知道所有的输入数据,而是随着数据流的到来,随时都可以进行计算,之所以可以这样计算,是因为保存可中间的计算结果,与离线计算相比,运行时间短,计算量级相对较小。
强调计算过程的时间要短,即所查当下给出结果,离线计算强调批量,大数据的计算,运行时间长。
主要侧重于对当日数据的实时监控,通常业务逻辑相对离线需求简单一下,统计指标也少一些,但是更注重数据的时效性,以及用户的交互性。
从技术操作的角度,这部分属于流处理的操作。根据数据源源不断地到达进行实时的运算。
即席查询
强调查询的临时性,需求的临时性。
presto:当场计算,基于内存速度快。
kylin:预计算,提前计算好。做多维度分析(hive with cube),数据有多种维度,那么kylin会把所有的维度组合全部计算好。需要的时候直接拿去即可。
架构分析
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic ods_base_log离线架构
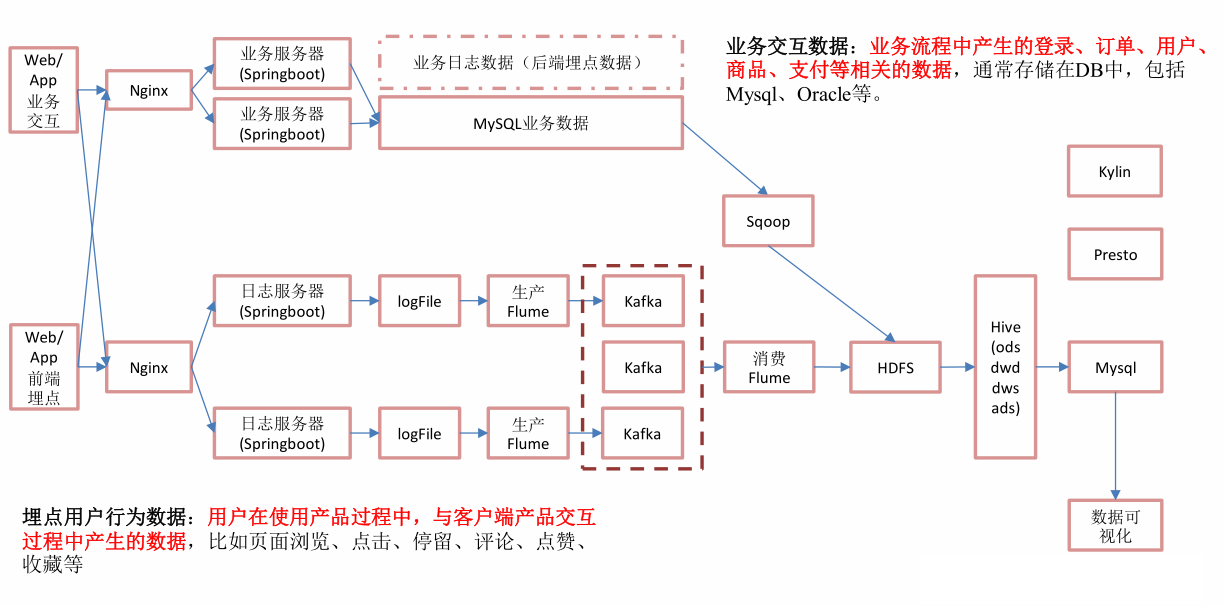
在这里为什么在收集日志的时候,使用了2=flume—>kafka—》flume,因为通常公司内实时数仓可离线数仓都是使用同一套采集系统,但是在读取数据处理的时候,实时数仓使用的是flink cdc,而离线数仓使用的是flume,所以相当于讲日志传输到kafka中,统一了接口。
如果离线数仓需要数据,就使用flume进行采集,如果实时数仓需要,就用flink cdc进行采集。
Niginx可以将我们的web页面产生的数据进行负载均衡,如果是日志数据,那么就传输到日志服务器,如果是埋点数据,那么就存储到业务服务器。
对于日志数据,日志服务器会进行落盘处理,然后由kafka读取到Flink中进行实时处理,.
那么对于业务数据,我们一般会写在mysql数据库中,然后使用flink cdc对数据库进行监控,查询到变化后就会传输到kafka中。
在离线数仓中,mysql数据借助sqoop导入到HDFS上面,sqoop是基于mr原理,延迟很高,一般有增量,全量,新增及变化和特殊等同步方式。我们一般是通过where条件后面添加日期来判断数据的类型,然后进行数据的导入。
四种数据的导入方式
- 增量,创建时间==今天时间
- 全量数据:where 1==1
- 新增以及变化:data==今天 or 修改时间 == 今天
- 对于特殊数据,一般导入一次即可,后续不需要导入。
使用flume在导入日志数据的时候,有source、channel,没有使用sink,因为我们直接将数据传输到kafka中。
flume:
- TailDirSource:
- 优点:断点续传,监控多目录,多文件,实时监控
- 缺点:当文件更换名字之后,可能会重新读取文件,所以会造成数据的重复,是整个数据文件的重复。因为是按照inode+文件全路径名判断是否是新的文件,所以文件名变化,会认为是一个新的文件。
- 解决方法:
- 所以在使用的时候,需要使用不更名的打印日志框架(logback)
- 修改源码:让TailDirSource判断文件的时候,只看inode值。
- kafkachannel:将数据直接传入kafka,省了一层sink。
- 在kafka中即相当于生产者,有相当于消费者。
- 用法:
- Source-kafkaChannel
- Source-kafkaChannel
- kafkaChannel-Sink
第二个Flume
- kafkaSource
- FileChannle
- HdfsSink
hdfs如何防止小文件的产生:
滚动文件,按照时间,事件和文件大小这三个参数,还可以启动压缩。
实时架构
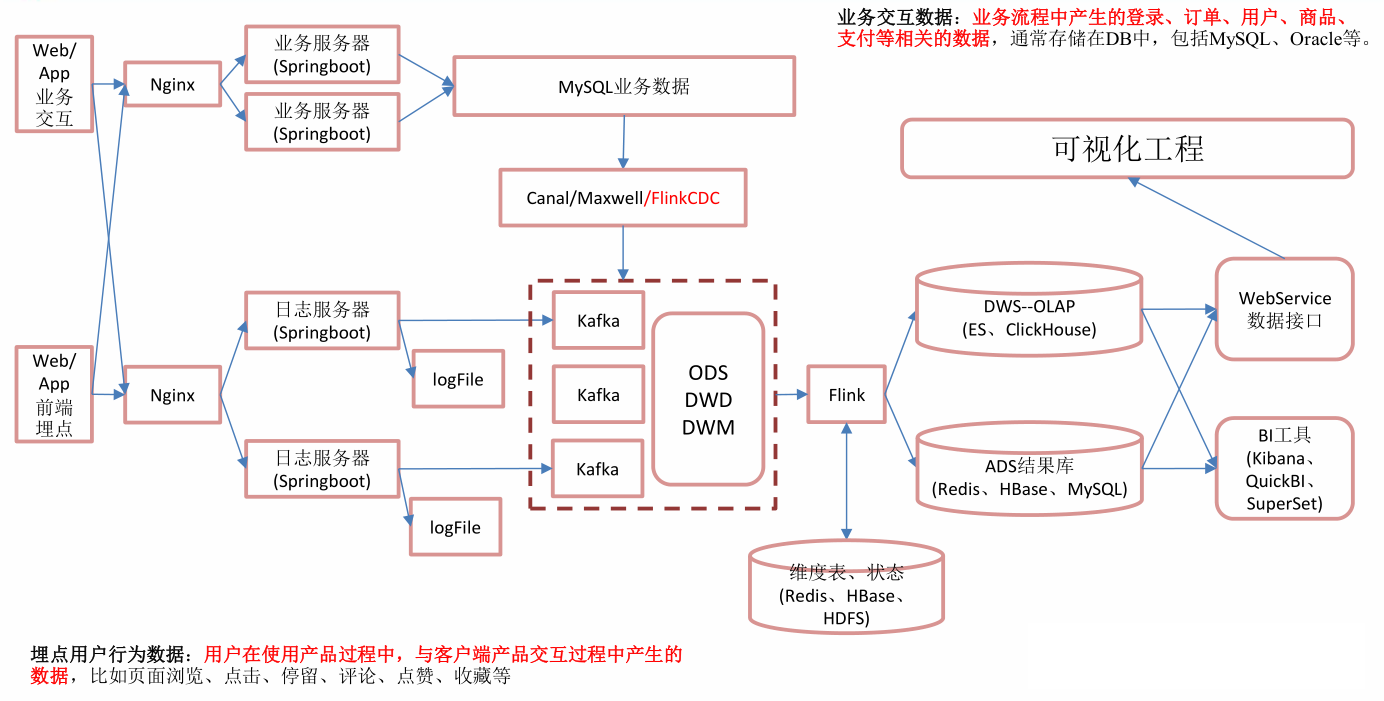
mysql业务数据导入kafka不能使用sqoop,因为sqoop原理是mr,延迟很高,不适合实时计算,所以我们使用Flink CDC实时读取数据。
Flink cdc会监控我们指定的数据库,只要监控到数据库中某一张表数据发生变化,flink cdc就会将变化的数据传输到kafak中供flink消费计算。
离线数仓中将日志文件通过Flume导入kafka中,但是在实时数仓中我们从日志服务器直接发送数据到kafka,这样做时效性很高,减少磁盘io,很快,但是也有缺点,耦合性高,两个系统相互影响,日志服务器出现问题,会影响后面大数据部分kafak的数据读取,不能够对数据进行过滤。
在离线数仓中,有flume拦截器,直接去掉不合法的json字符串。
数据先发送给flume source,source讲数据发送给channel,channel讲数据发送给拦截器进行过滤,然后转发给sink即可。
在离线数仓中,可以过滤掉非json数据,但是在实时数仓中,传输数据时候不能进行过滤。
ods层:
此时,业务数据,日志数据全部存储在kafka中,也就是ods层,在ods层只有两个主题的数据,行为数据,也就是日志数据,业务主题,也就是业务数据。
行为数据存储在ods_base.log文件中,直接讲数据写入String sourceTopic = "ods_base_log"主题当中。
业务数据存储在ods_base_db中,直接写入String sinkTopic="ods_base_db";主题当中,分区数是默认的3个分区
这两个在kafka中就是一个主题,将数存储在kafka主题当中。
dwd层
对于业务数据,事实表我们存放在kafka中,而维度表存放在HBASE中。
对于日志数据,我们进行分流处理:启动日志,页面日志,曝光日志
startDS.addSink(MyKafkaUtils.getKafkaProducer("dwd_start_log"));
pageDS.addSink(MyKafkaUtils.getKafkaProducer("dwd_page_log"));
displayDS.addSink(MyKafkaUtils.getKafkaProducer("dwd_display_log"));在这一部分中,因为日志数据会有很多种,所以会使用Flink中的测输出流,将日志数据分到不同的主题当中。
对于业务数据,因为从ods_base_db主题来的数据,既有事实表数据,又有维度表数据,所以我们需要对这两类数据进行分类。事实表数据输出到kafka的默认private static String default_topic = "DWD_DEFAULT_TOPIC";主题当中。
而对于维度表数据,输出到hbase数据库中。Phoenix 支持通过编写JDBC代码来操作HBase,比原生API更方便。
思考一下为什么需要配置表?
因为我们使用的是flink cdc对数据库中的某些表进行监控,只要数据库中的数据有变化,flink cdc就会监控到这种变化然后传输到kafka中,但是具体是哪一种变化,我们就需要使用一个配置表告诉,比如对某一张表进行监控,如果这张表中插入,删除,或者是更新数据,这三种操作都需要进行监控,然后传输,但是对于有些表,可能只需要监控删除数据和插入数据这种变化即可,所以我们需要配置表。
然后把配置流作为一个广播流广播出去,在配置表中,表明+操作类型是主键
小结:离线架构和实时架构是一套,只不过在实时架构中,采集日志数据部分没有使用flume,在采集业务数据的时候,没有使用flink cdc。
架构对比
离线架构
优点:耦合性低,解耦,稳定性高。
缺点:时效性差。
说明:考虑到需求的数据量很大,所以优先的考虑系统的稳定性,耦合性方面原因,考虑未来的发展,数据零肯定变大,所以选定离线架构。
实时架构
优点:时效性高。
缺点:耦合高,稳定性低。
说明:kafka是高可用集群,很不容易挂掉,挂少数机器没有问题。目前数据量小,所有机器在一个机房,数据传输没有问题,挂掉可能性小。
Flink CDC
CDC种类
CDC 主要分为基于查询和基于 Binlog两种方式,我们主要了解一下这两种之间的区别:
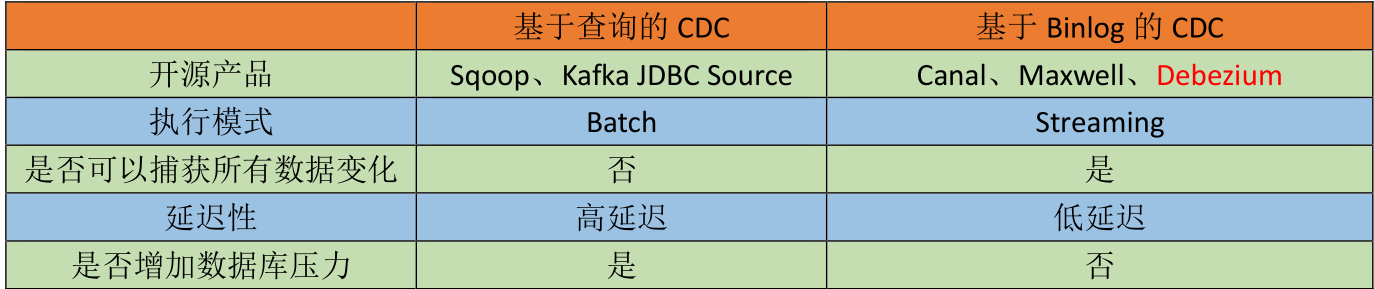
基于查询的Sqoop,我们是通过where查询语句实现不同数据的导入。而基于BinLgog cdc是不需要读取数据,他读取的是mysql的操作日志,典型的产品如上图所示。
是否捕获所有变化:
基于sqoop导入数据的时候,是每一天某个时间进行集中的数据导入。而基于Binlog方式,是基于流的模式,每一次发生变化,都可以监控到数据的变化。
延迟性
基于查询的方式,可能会丢失数据,查询的是快照,最后的结果,也就是导入的是最终的数据,中间的过程数据是无法导入的。一条数据发生多次变化,只能拿到最后一次的数据,Binlog可以捕获所有数据,每变化一次,就加载一次,因为里面记录的是数据的操作日志。
是否产生压力
是否增加数据库压力,基于查询使用的是select语句,所以是一次查询,但是基于Binliog,读取的是一个磁盘文件,不会堆服务器产生太大压力。
Flink 社区开发了 flink-cdc-connectors 组件,这是一个可以直接从 MySQL、PostgreSQL等数据库直接读取全量数据和增量变更数据的 source 组件
Flink cdc在读取数据时候,参数说明:
initial参数
- 先做全量数据的快照保存,这个阶段会对数据进行加锁处理,防止修改。
- 第二个阶段是从最新的binlog中读取数据更新操作,读取增量数据。
会打印全部数据
earliest
- 不做初始化操作,仅仅从日志开始处读取数据。但是需要包括创建库,表的语句,也就是必须包含完整的binlog日志。
latest
- 不会做快照,只会获取最新的数据,也就是链接之后,更新的数据。
打印最新的数据
指定时间戳
- 读取指定时间戳的数据,读取的数据时间戳是大于等于我们指定的时间戳数据。
Flink cdc读取数据代码DataStream
public class FlinkCDC {
public static void main(String[] args) throws Exception {
//1.创建执行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//2.Flink-CDC 将读取 binlog 的位置信息以状态的方式保存在 CK,如果想要做到断点
续传,需要从 Checkpoint 或者 Savepoint 启动程序
//2.1 开启 Checkpoint,每隔 5 秒钟做一次 CK
env.enableCheckpointing(5000L);
//2.2 指定 CK 的一致性语义
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//2.3 设置任务关闭的时候保留最后一次 CK 数据
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckp
ointCleanup.RETAIN_ON_CANCELLATION);
//2.4 指定从 CK 自动重启策略
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 2000L));
//2.5 设置状态后端
env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/flinkCDC"));
//2.6 设置访问 HDFS 的用户名
System.setProperty("HADOOP_USER_NAME", "atguigu");
//3.创建 Flink-MySQL-CDC 的 Source
//initial (default): Performs an initial snapshot on the monitored database tables upon
first startup, and continue to read the latest binlog.
//latest-offset: Never to perform snapshot on the monitored database tables upon first
startup, just read from the end of the binlog which means only have the changes since the
connector was started.
//timestamp: Never to perform snapshot on the monitored database tables upon first
startup, and directly read binlog from the specified timestamp. The consumer will traverse the
binlog from the beginning and ignore change events whose timestamp is smaller than the
specified timestamp.
//specific-offset: Never to perform snapshot on the monitored database tables upon
first startup, and directly read binlog from the specified offset.
DebeziumSourceFunction<String> mysqlSource = MySQLSource.<String>builder()
.hostname("hadoop102")
.port(3306)
.username("root")
.password("000000")
.databaseList("gmall-flink")
.tableList("gmall-flink.z_user_info") //可选配置项,如果不指定该参数,则会读取上一个配置下的所有表的数据,注意:指定的时候需要使用"db.table"的方式
.startupOptions(StartupOptions.initial())
.deserializer(new StringDebeziumDeserializationSchema())
.build();
//4.使用 CDC Source 从 MySQL 读取数据
DataStreamSource<String> mysqlDS = env.addSource(mysqlSource);
//5.打印数据
mysqlDS.print();
//6.执行任务
env.execute();
}
}在Flink cdc中可以做到断点续传,但是需要依赖savepoint或者checkpoint才可以。那么会根据我们的binlog日志,去执行日志中的每一条记录对数据的操作。
还可以初始化数据,也就是读取全量数据,就是上面我们写的initial参数,还可以读取最新数据,使用latest参数即可。
上面是使用Flink DataStream的方式读取数据,那么在Flink中还提供了Flink Sql的方式读取数据。
Flink Sql读取数据
public class FlinkSQL_CDC {
public static void main(String[] args) throws Exception {
//1.创建执行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//2.创建 Flink-MySQL-CDC 的 Source
tableEnv.executeSql("CREATE TABLE user_info (" +
" id INT," +
" name STRING," +
" phone_num STRING" +
") WITH (" +
" 'connector' = 'mysql-cdc'," +
" 'hostname' = 'hadoop102'," +
" 'port' = '3306'," +
" 'username' = 'root'," +
" 'password' = '000000'," +
" 'database-name' = 'gmall-flink'," +
" 'table-name' = 'z_user_info'" +
")");
tableEnv.executeSql("select * from user_info").print();
env.execute();
}
}对比
DataStream可以监控多个数据库,多张表。
但是Flink sql每一次只能监控一个库,一张表。
Flink sql默认参数是initial。
在flink cdc传输处数据之后,上面的做法只是简单的显示的控制台,使用默认序列化,但是实际中,需要传输到下游进行处理,所以需要进行反序列化操作。一般我们使用json工具将上面的数据进行解析,转换位标准的json字符串输出到下游系统处理。
public class Flink_CDCWithCustomerSchema {
public static void main(String[] args) throws Exception {
//1.创建执行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//2.创建 Flink-MySQL-CDC 的 Source
Properties properties = new Properties();
//initial (default): Performs an initial snapshot on the monitored database tables upon
first startup, and continue to read the latest binlog.
//latest-offset: Never to perform snapshot on the monitored database tables upon first
startup, just read from the end of the binlog which means only have the changes since the
connector was started.
//timestamp: Never to perform snapshot on the monitored database tables upon first
startup, and directly read binlog from the specified timestamp. The consumer will traverse the
binlog from the beginning and ignore change events whose timestamp is smaller than the
specified timestamp.
//specific-offset: Never to perform snapshot on the monitored database tables upon
first startup, and directly read binlog from the specified offset.
DebeziumSourceFunction<String> mysqlSource = MySQLSource.<String>builder()
.hostname("hadoop102")
.port(3306)
.username("root")
.password("000000")
.databaseList("gmall-flink")
.tableList("gmall-flink.z_user_info") //可选配置项,如果不指定该参数,则会读取上一个配置下的所有表的数据,注意:指定的时候需要使用"db.table"的方式
.startupOptions(StartupOptions.initial())
.deserializer(new DebeziumDeserializationSchema<String>() { //自定义数据解析器
@Override
public void deserialize(SourceRecord sourceRecord, Collector<String>
collector) throws Exception {
//获取主题信息,包含着数据库和表名
mysql_binlog_source.gmall-flink.z_user_info
//获取topic字段,包含数据路名字和表名字
String topic = sourceRecord.topic();
String[] arr = topic.split("\\.");
String db = arr[1];
String tableName = arr[2];
//获取操作类型 READ DELETE UPDATE CREATE
Envelope.Operation operation =
Envelope.operationFor(sourceRecord);
//获取值信息并转换为 Struct 类型
Struct value = (Struct) sourceRecord.value();
//获取变化后的数据
Struct after = value.getStruct("after");
//创建 JSON 对象用于存储数据信息
JSONObject data = new JSONObject();
for (Field field : after.schema().fields()) {
Object o = after.get(field);
data.put(field.name(), o);
}
//创建 JSON 对象用于封装最终返回值数据信息
JSONObject result = new JSONObject();
result.put("operation", operation.toString().toLowerCase());
result.put("data", data);
result.put("database", db);
result.put("table", tableName);
//发送数据至下游
collector.collect(result.toJSONString());
}
@Override
public TypeInformation<String> getProducedType() {
return TypeInformation.of(String.class);
}
})
.build();
//3.使用 CDC Source 从 MySQL 读取数据
DataStreamSource<String> mysqlDS = env.addSource(mysqlSource);
//4.打印数据
mysqlDS.print();
//5.执行任务
env.execute();
}
}数据格式
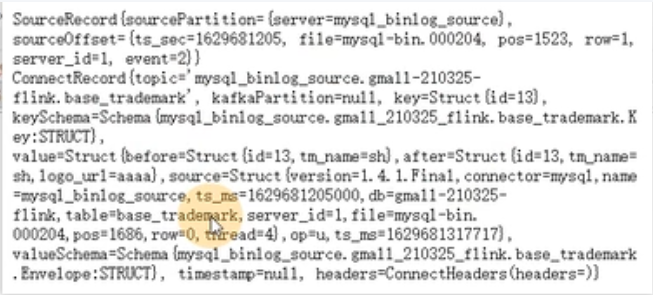
输出数据格式

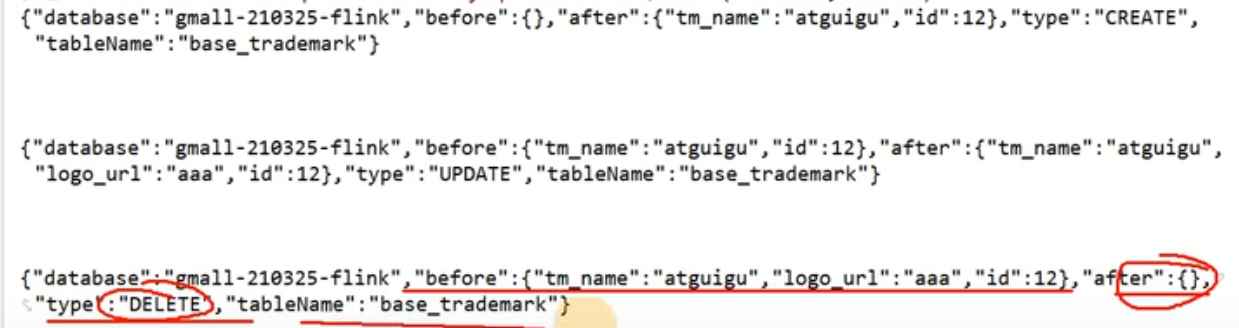
增删改之后数据展示
小结
DataStream
优点:
- 可以监控多库多表
缺点:
- 需要自定义反序列化器。自定义也有好处,就是灵活。
FlinkSql
优点:
- 不需要自定义反序列化器,可以使用java bean进行接收。
缺点:
- 只能单库单表查询。
Maxwell
Maxwell 是由美国 Zendesk 开源,用 Java 编写的 MySQL 实时抓取软件。 实时读取MySQL 二进制日志 Binlog,并生成 JSON 格式的消息,作为生产者发送给 Kafka,Kinesis、RabbitMQ、Redis、Google Cloud Pub/Sub、文件或其它平台的应用程序。
Mysql主从复制过程
- Master 主库将改变记录,写到二进制日志(binary log)中
- Slave 从库向 mysql master 发送 dump 协议,将 master 主库的 binary log events拷贝到它的中继日志(relay log);
- 拷贝到它的中继日志(relay log);
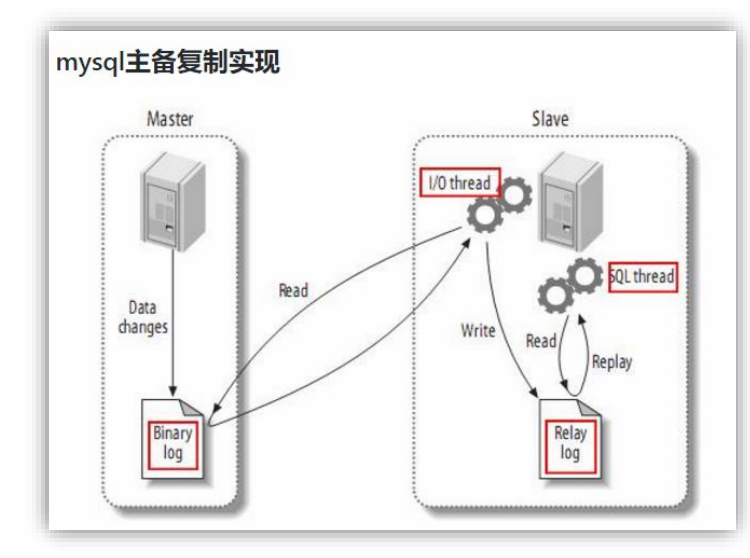
Maxwell 的工作原理
很简单,就是把自己伪装成 slave,假装从 master 复制数据.
MySQL的binlog
什么是 binlog
MySQL 的二进制日志可以说 MySQL 最重要的日志了,它记录了所有的DDL和DML(除了数据查询语句)语句,以事件形式记录,还包含语句所执行的消耗的时间,MySQL的二进制日志是事务安全型的。
一般来说开启二进制日志大概会有 1%的性能损耗。二进制有两个最重要的使用场景:
- 其一:MySQL Replication 在 Master 端开启 binlog,Master 把它的二进制日志传递给 slaves 来达到master-slave 数据一致的目的。
- 其二:自然就是数据恢复了,通过使用 mysqlbinlog 工具来使恢复数据。
二进制日志包括两类文件:二进制日志索引文件(文件名后缀为.index)用于记录所有的二进制文件.
二进制日志文件(文件名后缀为.00000*)记录数据库所有的 DDL 和 DML(除了数据查询语句)语句事件。
binlog的开启
找到 MySQL 配置文件的位置
Linux: /etc/my.cnf,如果/etc 目录下没有,可以通过 locate my.cnf 查找位置.Windows: \my.ini.
在 mysql 的配置文件下,修改配置
在[mysqld] 区块,设置/添加 log-bin=mysql-bin
这个表示 binlog 日志的前缀是 mysql-bin,以后生成的日志文件就是mysql-bin.123456 的文件后面的数字按顺序生成,每次 mysql 重启或者到达单个文件大小的阈值时,新生一个文件,按顺序编号。
binlog 的分类设置
mysql binlog 的格式有三种,分别是 STATEMENT,MIXED,ROW。
在配置文件中可以选择配置 binlog_format= statement|mixed|row
statement格式
语句级,binlog 会记录每次执行写操作的语句。
相对 row 模式节省空间,但是可能产生不一致性,比如
update tt set create_date=now()
如果用 binlog 日志进行恢复,由于执行时间不同可能产生的数据就不同。
优点: 节省空间
缺点: 有可能造成数据不一致。
row行级
行级, binlog 会记录每次操作后每行记录的变化。
优点:保持数据的绝对一致性。因为不管 sql 是什么,引用了什么函数,他只记录执行后的效果。
缺点:占用较大空间。
mixed
mixed式statement 的升级版,一定程度上解决了,因为一些情况而造成的 statement 模式不一致问题.
默认还是 statement,在某些情况下譬如:
当函数中包含 UUID() 时;
包含 AUTO_INCREMENT 字段的表被更新时;
执行 INSERT DELAYED 语句时;
用 UDF 时;
会按照 ROW 的方式进行处理
优点:节省空间,同时兼顾了一定的一致性。
缺点:还有些极个别情况依旧会造成不一致,另外 statement 和 mixed 对于需要对 binlog 的监控的情况都不方便。
综合上面对比,Maxwell 想做监控分析,选择 row 格式比较合适
Canal
什么式Canal
Canal 是用 java 开发的基于数据库增量日志解析,提供增量数据订阅&消费的中间件。目前,Canal 主要支持了 MySQL 的Binlog 解析,解析完成后才利用 Canal Client 来处理获得的相关数据。(数据库同步需要阿里的 Otter 中间件,基于 Canal)。
Canal 的工作原理
很简单,就是把自己伪装成 Slave,假装从 Master 复制数据
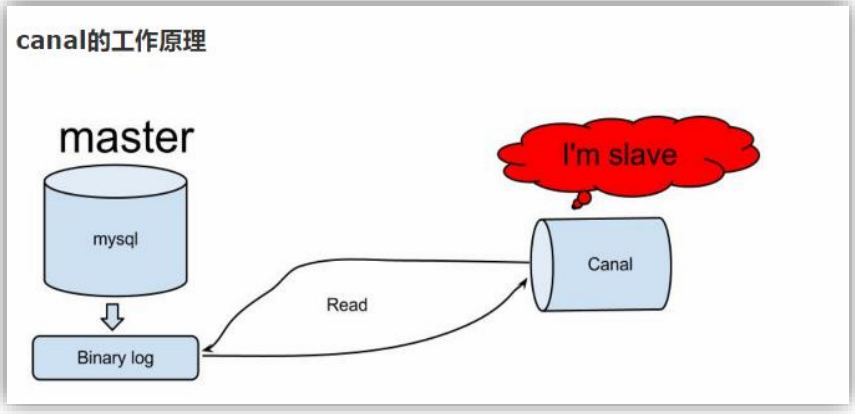
Maxwell与Canal工具对比
- Maxwell 没有 Canal 那种 server+client 模式,只有一个 server 把数据发送到消息队列或 redis。
- Maxwell 有一个亮点功能,就是 Canal 只能抓取最新数据,对已存在的历史数据没有办法处理。而 Maxwell 有一个 bootstrap 功能,可以直接引导出完整的历史数据用于初始化,非常好用。
- Maxwell 不能直接支持 HA,但是它支持断点还原,即错误解决后重启继续上次点儿读取数据。
- Maxwell 只支持 json 格式,而 Canal 如果用 Server+client 模式的话,可以自定义格式。
- Maxwell 比 Canal 更加轻量级。
三个工具对比
对于插入数据
如果新增好几条数据,Flink cdc和maxWell会单独输出多条数据,但是canal会将多条数据封装在一个data数组中,如果后续解析数据,需要使用炸裂函数,不方便。
canal 每一条 SQL 会产生一条日志,如果该条 Sql 影响了多行数据,则已经会通过集合(data数组)的方式归集在这条日志中。(即使是一条数据也会是数组结构)
maxwell 以影响的数据为单位产生日志,即每影响一条数据就会产生一条日志。如果想知道这些日志是否是通过某一条 sql 产生的可以通过 xid 进行判断,相同的 xid 的日志来自同一 sql。
更新数据
maxwell会将更新的数据输出,然后更新的字段会单独显示,flink cdc会把全部整条数据拿过来,方便后续操作,canal更新后数据还是一个数组形式,不方便操作.
删除数据
Flink cdc会将整个数据拿过来,只显示操作是删除即可,方便后续处理,maxwell也返回多条删除的操作,但是只是显示字段,而canal返回一个数组,里面是对应多条数据操作.
从上面对比来看,使用最方便的是Flink cdc .
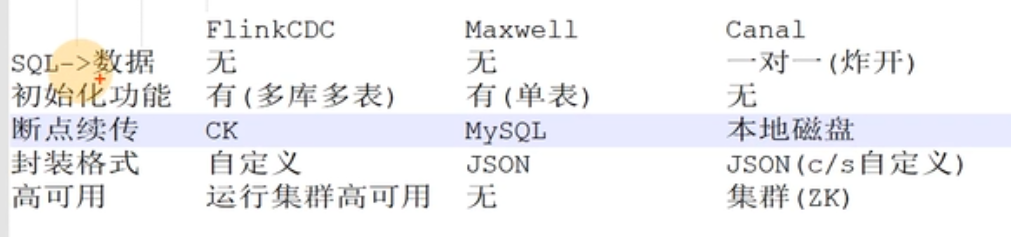
sql ->数据
执行一条sql会影响多少条数据,在canal中只是一对一,如果需要影响多条数据,需要使用炸裂函数,但是在Flink sql和maxwell中没有限制,可以一对多.
初始化
flink cdc可以做初始化,也就是读取mysql中的历史数据,maxwell也可以做初始化,但是只能对单表做初始化,canal不可以, 如果希望可以做,需要额外处理写脚本.
断点续传:
Flink cdc有,并且是ck来保存断点续传位置,maxwell也有断点续传功能,是mysql保存断点位置,acnal也可以做断点续传,保存在磁盘上面.
数据封装格式
Flink cdc可以自定义,maxwell使用json封装,canal使用json格式,也可以自定义.
高可用
Flink cdc因为是代码形式,所以只要运行的集群式高可用那么就支持,maxwell不支持,而canal支持zk部署高可用.
数据采集小结
业务数据采集
在业务数据采集阶段,首先使用Flink cdc监控mysql中某一个库中的所有表,只要某一张表中的数据有变化,那么Flink cdc就会将数据输出到kafka中。
在Flink cdc中有以下几点需要注意:
- 就是自定义反序列化器,因为我们需要把数据输出到kafka中,所以需要把数据的格式进行反序列化,然后输出到kafka中。
- 第二个需要注意的是,在生产环境中,我们一般需要使用检查点,精确一致性等等语义,但是本项目只是在测试中使用验证了一下,并没有真正的使用。
- 在本项目中,需要监控的是业务数据库中的所有数据,所以在监控的时候,没有指定具体监控的是那一张表,而是监控整个数据库,这样所有表的变化,都可以监控并且输出到kafak.
- 在把Flink cdc中的数据输出到kafka阶段,使用的是Flink sink,在sink中添加自定义FlinkKafkaProducer组件,因为在本项目中多次使用到kafka,所以为了解耦,把创建FlinkKafkaProducer组件封装为一个工具类,使用的时候,直接从工具类中获取组件即可。
数据读取两个类:
Flink CDC:监控业务数据库中的所有表,如果有变化,就输出到kafka中。
自定义CustomerDeserialization类首先反序列化操作。
MyKafkaUtils类:封装了生成FlinkKafkaProducer工具类,这样做可以解耦。
经过上面所有操作,那么业务数据库中的所有表中的数据都可以被读取到ods层中,其中kafka1相当于业务数据的ods层,所有的业务数据都会发送到kafka1的ods_base_db主题当中。
行为数据采集方法(日志数据)
对kafka2和kafka3两台服务器上生成的日志数据,开启kafka读取日志数据,消费的数据在ods_base_log主题当中。
业务数据对应的表:ods_base_db
行为数据对应的表:ods_base_log
项目目录说明
gmall-realtime模块下包说明:
app:产生各层数据的 flink 任务
bean:数据对象
common:公共常量
utils:工具类
实现类说明
CustomerDeserialization
实现从业务数据库读取数据自定义反序列化的操作。
Flink CDC
实现监控业务数据库的操作。
MyKafkaUtils
封装写入kafka的操作。
数据格式说明
日志数据格式
曝光日志
{
"common": { -- 公共信息
"ar": "230000", -- 地区编码
"ba": "iPhone", -- 手机品牌
"ch": "Appstore", -- 渠道
"md": "iPhone 8", -- 手机型号
"mid": "YXfhjAYH6As2z9Iq", -- 设备id
"os": "iOS 13.2.9", -- 操作系统
"uid": "485", -- 会员id
"vc": "v2.1.134" -- app版本号
},
"actions": [ --动作(事件)
{
"action_id": "favor_add", --动作id
"item": "3", --目标id
"item_type": "sku_id", --目标类型
"ts": 1585744376605 --动作时间戳
}
],
"displays": [
{
"displayType": "query", -- 曝光类型
"item": "3", -- 曝光对象id
"item_type": "sku_id", -- 曝光对象类型
"order": 1 --出现顺序
},
{
"displayType": "promotion",
"item": "6",
"item_type": "sku_id",
"order": 2
},
{
"displayType": "promotion",
"item": "9",
"item_type": "sku_id",
"order": 3
},
{
"displayType": "recommend",
"item": "6",
"item_type": "sku_id",
"order": 4
},
{
"displayType": "query ",
"item": "6",
"item_type": "sku_id",
"order": 5
}
],
"page": { --页面信息
"during_time": 7648, -- 持续时间毫秒
"item": "3", -- 目标id
"item_type": "sku_id", -- 目标类型
"last_page_id": "login", -- 上页类型
"page_id": "good_detail", -- 页面ID
"sourceType": "promotion" -- 来源类型
},
"err":{ --错误
"error_code": "1234", --错误码
"msg": "***********" --错误信息
},
"ts": 1585744374423 --跳入时间戳
}page日志
{"common":{
"ar":"110000",
"ba":"iPhone",
"ch":"Appstore",
"is_new":"0",
"md":"iPhone8",
"mid":"mid_20",
"os":"ios13.2.3",
"uid":"2",
"vc":"v2.1.134"
},
"page":{
"during_time":8714,
"1ast_page_id":"home",
"page_id":"search"
},
"ts":16827995909
}启动日志
{
"common": {
"ar": "370000",
"ba": "Honor",
"ch": "wandoujia",
"md": "Honor 20s",
"mid": "eQF5boERMJFOujcp",
"os": "Android 11.0",
"uid": "76",
"vc": "v2.1.134"
},
"start": {
"entry": "icon", --icon手机图标 notice 通知 install 安装后启动
"loading_time": 18803, --启动加载时间
"open_ad_id": 7, --广告页ID
"open_ad_ms": 3449, -- 广告总共播放时间
"open_ad_skip_ms": 1989 -- 用户跳过广告时点
},
"err":{ --错误
"error_code": "1234", --错误码
"msg": "***********" --错误信息
},
"ts": 1585744304000
}业务数据封装格式
{
"database":"",
"tableName":"",
"before":{
"id":"",
"tm_name":""
},
"after":{
"id":"",
"tm_name":""
},
"type":"c_u_d",
"ts":156456135615
}业务数据封装
贡献者
 codingLab
codingLab版权所有
版权归属:
许可证: