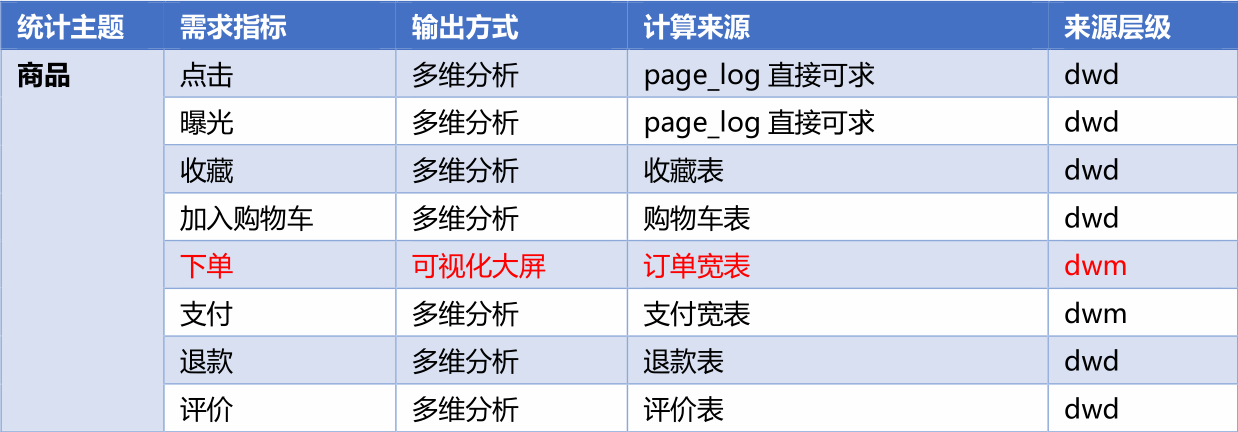
3、实时数仓DWS层业务实现
实时数仓DWS 层业务实现
DWS 层与 DWM 层的设计
访客主题宽表计算
要不要把多个明细的同样的维度统计在一起?
因为单位时间内 mid 的操作数据非常有限不能明显的压缩数据量(如果是数据量够大,或者单位时间够长可以)
所以用常用统计的四个维度进行聚合 渠道、新老用户、app 版本、省市区域。
度量值包括 :
- 启动
- 日活(当日首次启动)
- 访问页面数
- 新增用户数
- 跳出数
- 平均页面停留时长
- 总访问时长
各个数据在维度聚合前不具备关联性,所以先进行维度聚合
- 进行关联 这是一个 fulljoin
- 可以考虑使用 flinksql 完成
设计思路
我们在之前通过分流等手段,把数据分拆成了独立的 Kafka Topic。那么接下来如何处理数据,就要思考一下我们到底要通过实时计算出哪些指标项。
因为实时计算与离线不同,实时计算的开发和运维成本都是非常高的,要结合实际情况考虑是否有必要象离线数仓一样,建一个大而全的中间层。如果没有必要大而全,这时候就需要大体规划一下要实时计算出的指标需求了。把这些指标以主题宽表的形式输出就是我们的 DWS 层。
在DWM层,我们形成了四张宽表:
- 访客主题宽表(离线数仓按照user_id,实时按照mid(设备id)来)
- 跳出明细主题宽表
- 订单主题宽表
- 支付宽表
在Dws层,我们要形成下面四个宽表:
- 访客主题宽表计算
- 商品主题宽表计算
- 地区主题宽表计算
- 关键词主题宽表
前两个需求,我们使用DataStream Api完成,后两个主题,我们使用Flink sql完成。
需求梳理


横向看,是我们的维度,也就是形成的宽表,通常是维度表字段,可以看出有四个主题:
- 访客
- 商品
- 地区
- 关键词
纵向看是我们的具体需求指标。我们具体在计算某一个指标的时候,我们需要看一下是否需要对我们的dwd层数据进行加工,如果需要做加工,我们的数据来源就是dwm层数据,如果不需要,我们直接从dwd层数据获取。
DWS 层的定位是什么
- 轻度聚合,因为 DWS 层要应对很多实时查询,如果是完全的明细那么查询的压力是非常大的。
- 将更多的实时数据以主题的方式组合起来便于管理,同时也能减少维度查询的次数。
DWS层访客主题宽表的计算

设计一张 DWS 层的表其实就两件事:维度和度量(事实数据)
- 度量包括 PV、UV、跳出次数、进入页面数(session_count)、连续访问时长,度量也就是我们需要求的指标。
- 维度包括在分析中比较重要的几个字段:渠道、地区、版本、新老用户进行聚合,维度可以理解为围绕我们的主题的几个比较重要的字段。
PV:page_view,页面的访问,每一条页面访问日志,就是一个页面访问,所以直接对页面访问日志累加即可。
UV:用户访问页面,也就是日活跃量,我们需要对数据首先进行去重,因为一个用户一天可能多次访问页面,所以需要先去重操作,去重的数据可以从dwm层直接获取。
跳出率:跳出总数除以PV。这一层实际在ods层计算,所以在dws层,我们先计算跳出页面的数量。因为我们已经算出了跳出明细,所以可以直接对dwm层数据进行加工即可。
进入页面数:我们可以直接判断上一层页面id的值是否是空,如果是空,计算进入页面。
连续访问时间:我们需要使用dwd层数据,里面有一个字段是duration_time,可以在此基础上做聚合操作。
上面五个需求,涉及到三个主题,而且每一个主题数据都是不一样的:
- dwd_page_log
- dwm_unique_visit
- dwm_user_jump_detail
需求分析与思路
- 接收各个明细数据,变为数据流,我们有五个需求,那么数据源有三个主题,也就是三条数据的来源。
- 把数据流合并在一起,成为一个相同格式对象的数据流,使用的是union方法。
- 对合并的流进行聚合,聚合的时间窗口决定了数据的时效性,在离线数仓中,我们是按照天进行轻度的汇总,但是在实时数据仓库中,我们一般按照小时进行汇总。
- 把聚合结果写在数据库中(ck数据库).
功能实现
封装 VisitorStatsApp,读取 Kafka 各个流数据
/**
* Desc: 访客主题宽表计算
* <p>
* ?要不要把多个明细的同样的维度统计在一起?
* 因为单位时间内 mid 的操作数据非常有限不能明显的压缩数据量(如果是数据量够大,
或者单位时间够长可以)
* 所以用常用统计的四个维度进行聚合 渠道、新老用户、app 版本、省市区域
* 度量值包括 启动、日活(当日首次启动)、访问页面数、新增用户数、跳出数、平均页
面停留时长、总访问时长
* 聚合窗口: 10 秒
* <p>
* 各个数据在维度聚合前不具备关联性,所以先进行维度聚合
* 进行关联 这是一个 fulljoin
* 可以考虑使用 flinksql 完成
*/
//TODO 2.读取Kafka数据创建流
String groupId = "visitor_stats_app";
String uniqueVisitSourceTopic = "dwm_unique_visit";
String userJumpDetailSourceTopic = "dwm_user_jump_detail";
String pageViewSourceTopic = "dwd_page_log";
DataStreamSource<String> uvDS = env.addSource(MyKafkaUtils.getKafkaConsumer(uniqueVisitSourceTopic, groupId));
DataStreamSource<String> ujDS = env.addSource(MyKafkaUtils.getKafkaConsumer(userJumpDetailSourceTopic, groupId));
DataStreamSource<String> pvDS = env.addSource(MyKafkaUtils.getKafkaConsumer(pageViewSourceTopic, groupId));合并数据流
把数据流合并在一起,成为一个相同格式对象的数据.
合并数据流的核心算子是 union。但是 union 算子,要求所有的数据流结构必须一致。所以 union 前要调整数据结构。
封装主题宽表实体类 VisitorStats
/**
* Desc: 访客统计实体类 包括各个维度和度量
*/
@Data
@AllArgsConstructor
public class VisitorStats {
//统计开始时间
private String stt;
//统计结束时间
private String edt;
// 上面两个是窗口的开始和结束时间
//维度:版本
private String vc;
//维度:渠道
private String ch;
//维度:地区
private String ar;
//维度:新老用户标识
private String is_new;
// 上面是统计的四个维度
//下面是统计的5个度量
// 度量:独立访客数
private Long uv_ct = 0L;
//度量:页面访问数
private Long pv_ct = 0L;
//度量: 进入次数
private Long sv_ct = 0L;
//度量: 跳出次数
private Long uj_ct = 0L;
//度量: 持续访问时间
private Long dur_sum = 0L;
// 需要使用窗口聚合,所以需要时间戳
//统计时间
private Long ts;
}对读取的各个数据流进行结构的转换
//TODO 3.将每个流处理成相同的数据类型
//3.1 处理UV数据,转换uv数据流,用户活跃度
SingleOutputStreamOperator<VisitorStats> visitorStatsWithUvDS = uvDS.map(line -> {
// 传输进来的是json字符串,首先转换为json对象
JSONObject jsonObject = JSON.parseObject(line);
//提取公共字段
JSONObject common = jsonObject.getJSONObject("common");
// 封装的对象里面,有的字段可以填充那么就填充,不可以填充的就补默认值
return new VisitorStats("", "",
common.getString("vc"),
common.getString("ch"),
common.getString("ar"),
common.getString("is_new"),
1L, 0L, 0L, 0L, 0L,
jsonObject.getLong("ts"));
// uv字段填写1,是因为每一条记录都算一盒用户,因为这里面的数据已经是去重后的数据
});
//3.2 处理UJ数据 跳转数据
SingleOutputStreamOperator<VisitorStats> visitorStatsWithUjDS = ujDS.map(line -> {
JSONObject jsonObject = JSON.parseObject(line);
//提取公共字段
// uj字段设置1,每一条数据都算一个跳出,是从dwm层读取的数据,经过处理的数据
JSONObject common = jsonObject.getJSONObject("common");
return new VisitorStats("", "",
common.getString("vc"),
common.getString("ch"),
common.getString("ar"),
common.getString("is_new"),
0L, 0L, 0L, 1L, 0L,
jsonObject.getLong("ts"));
});
// 进入页面数,只有上一条为null的时候,才算进入页面
//3.3 处理PV数据
SingleOutputStreamOperator<VisitorStats> visitorStatsWithPvDS = pvDS.map(line -> {
JSONObject jsonObject = JSON.parseObject(line);
//获取公共字段
JSONObject common = jsonObject.getJSONObject("common");
//获取页面信息
JSONObject page = jsonObject.getJSONObject("page");
// 获取上一条页面id,如果为空,那么就是进入页面
String last_page_id = page.getString("last_page_id");
long sv = 0L;
if (last_page_id == null || last_page_id.length() <= 0) {
sv = 1L;
}
return new VisitorStats("", "",
common.getString("vc"),
common.getString("ch"),
common.getString("ar"),
common.getString("is_new"),
0L, 1L, sv, 0L, page.getLong("during_time"),
jsonObject.getLong("ts"));
});四条流合并起来
//TODO 4.Union几个流,这里一共花合并三个流
DataStream<VisitorStats> unionDS = visitorStatsWithUvDS.union(
visitorStatsWithUjDS,
visitorStatsWithPvDS);根据维度进行聚合
设置时间标记及水位线。
因为涉及开窗聚合,所以要设定事件时间及水位线
//TODO 5.提取时间戳生成WaterMark
SingleOutputStreamOperator<VisitorStats> visitorStatsWithWMDS = unionDS.assignTimestampsAndWatermarks(WatermarkStrategy
// 因为需要做开窗,所以数据有延迟,设置一个延迟时间
// 这里延迟时间太短的话,可能会发生数据的丢,与uj相关的指标,没有办法不保证精确的时效性,,因为需要等到跳到吓一跳的时候,数据才能传输,因为数据延迟很高,所以延迟时间设置的比较大
// 也就无法保障时效性
.<VisitorStats>forBoundedOutOfOrderness(Duration.ofSeconds(11))
.withTimestampAssigner(new SerializableTimestampAssigner<VisitorStats>() {
@Override
public long extractTimestamp(VisitorStats element, long recordTimestamp) {
return element.getTs();
}
}));分组
使用四个维度的组合作为主键进行分组操作, 使用 Tuple4 组合
//TODO 6.按照维度信息分组,需要拿四个字段作为key,按照这四个字段组成的主键进行分组操作
KeyedStream<VisitorStats, Tuple4<String, String, String, String>> keyedStream = visitorStatsWithWMDS.keyBy(new KeySelector<VisitorStats, Tuple4<String, String, String, String>>() {
@Override
public Tuple4<String, String, String, String> getKey(VisitorStats value) throws Exception {
return new Tuple4<String, String, String, String>(
value.getAr(),//地区
value.getCh(),
value.getIs_new(),
value.getVc());
}
});开窗
//TODO 7.开窗聚合 10s的滚动窗口
// 这里使用的是滚动窗口,10秒钟滚动一次
WindowedStream<VisitorStats, Tuple4<String, String, String, String>, TimeWindow> windowedStream = keyedStream.window(TumblingEventTimeWindows.of(Time.seconds(10)));
// 对窗口中的数据做聚合,在这里需要补充开窗的时间信息,所以使用Rich函数,在这里使用Reduce增量聚合x+windowFunction,节省空间并且直到窗口信息
// 如果使用全量聚合,那么会收集所有数据到集合中,然后一次计算做聚合,这样有窗口信息,可以做top n
// reduceFun+WindowFun:来一条数据就做一次聚合操作,随着数据到来,全部处理或者聚合完数据后,就把聚合结果放入winDowFUN中,但是此时迭代器中
// 只有一条数据,就是聚合的结果数据窗口内聚合及补充时间字段
因为我们需要保证写入ck数据库的幂等性操作,所以需要直到窗口的开始和结束时间,所以我们使用全量聚合函数,获取窗口的开始和结束时间封装到对象中。
SingleOutputStreamOperator<VisitorStats> result = windowedStream.reduce(new ReduceFunction<VisitorStats>() {
@Override
public VisitorStats reduce(VisitorStats value1, VisitorStats value2) throws Exception {
value1.setUv_ct(value1.getUv_ct() + value2.getUv_ct());
value1.setPv_ct(value1.getPv_ct() + value2.getPv_ct());
value1.setSv_ct(value1.getSv_ct() + value2.getSv_ct());
value1.setUj_ct(value1.getUj_ct() + value2.getUj_ct());
value1.setDur_sum(value1.getDur_sum() + value2.getDur_sum());
return value1;
}
}, new WindowFunction<VisitorStats, VisitorStats, Tuple4<String, String, String, String>, TimeWindow>() {
@Override
public void apply(Tuple4<String, String, String, String> stringStringStringStringTuple4, TimeWindow window, Iterable<VisitorStats> input, Collector<VisitorStats> out) throws Exception {
// 获取窗口的开始和结束时间
long start = window.getStart();
long end = window.getEnd();
// 此时win中只有一条数据,直接获取即可
VisitorStats visitorStats = input.iterator().next();
//补充窗口信息,也就是设置窗口的时间
visitorStats.setStt(DateTimeUtil.toYMDhms(new Date(start)));
visitorStats.setEdt(DateTimeUtil.toYMDhms(new Date(end)));
// 输出数据
out.collect(visitorStats);
}
});写入 OLAP 数据库
为何要写入 ClickHouse 数据库,ClickHouse 数据库作为专门解决大量数据统计分析的数据库,在保证了海量数据存储的能力,同时又兼顾了响应速度。而且还支持标准 SQL,即灵活又易上手。
ClickHouse 数据表准备
create table visitor_stats (
stt DateTime,
edt DateTime,
vc String,
ch String,
ar String,
is_new String,
uv_ct UInt64,
pv_ct UInt64,
sv_ct UInt64,
uj_ct UInt64,
dur_sum UInt64,
ts UInt64
) engine =ReplacingMergeTree(ts)
partition by toYYYYMMDD(stt)
order by (stt,edt,is_new,vc,ch,ar);数据库中的字段和前面VisitorStats实体类的字段相互对应。
之所以选用 ReplacingMergeTree 引擎主要是靠它来保证数据表的幂等性。
paritition by 把日期变为数字类型(如:20201126),用于分区。所以尽量保证查询条件尽量包含 stt 字段。是按照天进行分区
order by 后面字段数据在同一分区下,出现重复会被去重,重复数据保留 ts 最大的数据。
其中 flink-connector-jdbc 是官方通用的 jdbcSink 包。只要引入对应的 jdbc 驱动,flink可以用它应对各种支持 jdbc 的数据库,比如 phoenix 也可以用它。但是这个 jdbc-sink 只支持数据流对应一张数据表。如果是一流对多表,就必须通过自定义的方式实现了,比如之前的维度数据。
虽然这种 jdbc-sink 只能一流对一表,但是由于内部使用了预编译器,所以可以实现批量提交以优化写入速度。
增加 ClickhouseUtil
/**
* Create a JDBC sink with the default {@link JdbcExecutionOptions}.
*
* @see #sink(String, JdbcStatementBuilder, JdbcExecutionOptions, JdbcConnectionOptions)
*/
public static <T> SinkFunction<T> sink(
String sql,
JdbcStatementBuilder<T> statementBuilder,
JdbcConnectionOptions connectionOptions
) {
return sink(sql, statementBuilder, JdbcExecutionOptions.defaults(), connectionOptions);
}JdbcSink.<T>sink( )的四个参数说明:
- 参数 1: 传入 Sql,格式如:insert into xxx values(?,?,?,?)
- 参数 2: 可以用 lambda 表达实现(jdbcPreparedStatement, t) -> t 为数据对象,要装配到语句预编译器的参数中。
- 参数 3:设定一些执行参数,比如重试次数,批次大小。
- 参数 4:设定连接参数,比如地址,端口,驱动名。
ClickhouseUtil 中获取 JdbcSink 函数的实现
//obj.getField() => field.get(obj)
//obj.method(args) => method.invoke(obj,args)
//自定义sink
public class ClickHouseUtil {
public static <T> SinkFunction<T> getSink(String sql) {
return JdbcSink.<T>sink(sql,
new JdbcStatementBuilder<T>() {
@Override
public void accept(PreparedStatement preparedStatement, T t) throws SQLException {
try {
//获取所有的属性信息,
Field[] fields = t.getClass().getDeclaredFields();
//遍历字段,获取每一个字段的值
int offset = 0;
for (int i = 0; i < fields.length; i++) {
//获取字段
Field field = fields[i];
//设置私有属性可访问
field.setAccessible(true);
// 我们未来在ck中建的表的字段个数和java bean对象中字段个数是一样的
//获取字段上注解,也急速hi这个字段不用序列化操作
TransientSink annotation = field.getAnnotation(TransientSink.class);
// 表明存在该注解
if (annotation != null) {
//存在该注解
offset++;
continue;
}
//获取值
Object value = field.get(t);
//给预编译SQL对象赋值,也就是给sql语句中的?赋值
preparedStatement.setObject(i + 1 - offset, value);
}
} catch (IllegalAccessException e) {
e.printStackTrace();
}
}
},
new JdbcExecutionOptions.Builder()
.withBatchSize(5)//批量执行,5条数据就执行一次
.build(),
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()//配置信息
.withDriverName(GmallConfig.CLICKHOUSE_DRIVER)
.withUrl(GmallConfig.CLICKHOUSE_URL)
.build());
}
}创建 TransientSink 注解,该注解标记不需要保存的字段
@Target(ElementType.FIELD)//表示作用的对象,是属性
@Retention(RUNTIME)//表示作用的范围,运行时都要保留
public @interface TransientSink {
}向 ClickHouse 写入数据的时候,如果有字段数据不需要传输,可以用该注解标记.
由于之前的 ClickhouseUtil工具类的写入机制就是把该实体类的所有字段按次序一次写入数据表。但是实体类有时会用到一些临时字段,计算中有用但是并不需要最终保存在临时表中。我们可以把这些字段做一些标识,然后再写入的时候判断标识来过滤掉这些字段。
为字段打标识通常的办法就是给字段加个注解,这里我们就增加一个自定义注解@TransientSink 来标识该字段不需要保存到数据表中。
在 GmallConfig 中配置 ClickHouse 的连接地址
/**
* Desc: 项目常用配置
*/
public class GmallConfig {
public static final String HBASE_SCHEMA="GMALL2021_REALTIME";
public static final String
PHOENIX_SERVER="jdbc:phoenix:hadoop102,hadoop103,hadoop104:2181";
public static final String
CLICKHOUSE_URL="jdbc:clickhouse://hadoop102:8123/default";
public static final String CLICKHOUSE_DRIVER =
"ru.yandex.clickhouse.ClickHouseDriver";
}为主程序增加写入 ClickHouse 的 Sink
/**
*
* 这里需要学习一点,就是在做窗口聚合的时候,可以增量聚合和全量聚合一起使用
*
* 在之前向hbase中写入数据的时候,并没有使用jdbc sink,因为在之前访问的表都不一样,并且每一个表中的字段都不一样
* 在这里写入ck中使用jdbc sink,因为这里写入ck中的数据属于同一张表中的数据,我们可以使用sql语句直接写入
// 现在封装为一个工具类
*/
//TODO 8.将数据写入ClickHouse
result.print(">>>>>>>>>>>");
// 使用jdbc的好处就是直接可以使用sql语句
result.addSink(ClickHouseUtil.getSink("insert into visitor_stats_210325 values(?,?,?,?,?,?,?,?,?,?,?,?)"));common模块里面的数据

DWS 层商品主题宽表的计算
需求分析与思路
- 从 Kafka 主题中获得数据流
- 把 Json 字符串数据流转换为统一数据对象的数据流
- 把统一的数据结构流合并为一个流
- 设定事件时间与水位线
- 分组、开窗、聚合
- 关联维度补充数据
- 写入 ClickHouse
如何分析:
- 首先分析关于商品我们要计算哪一些指标。
- 然后找到每一个指标对应的主题。也就是数据源。
- 然后同时消费多个主题中的数据。
- 将多个主题中的数据变为统一的流,也就是我们需要对每一个主题中的数据做统一的处理,变成相同格式的java bean对象。
- 之后将所有的数据流进行union。
- 然后提取时间戳,分组,开窗聚合,聚合的时候,使用增量聚合和全量聚合的方式。因为我们需要拿到窗口的时间,因为我们需要使用窗口的开始和结束时间来实现幂等性的操作,所以需要用到全量窗口。
spu:可以理解为款式
sku:可以理解为具体的商品
商品有很多的维度信息:spu,sku,trademark,category等等。我们把维度信息组合起来作为主键。
那么组合起来的宽表字段有:spu_id,spu_name,sku_id,sku_name,tradeMark,category,时间戳,窗口开始和结束时间,还有8个需求指标,金额,下单次数,商品个数等等字段。
在这里字段比较多,如果一个一个字段赋值默认值,很麻烦,所以我们使用构造者设计模式。
在这里需要注意一点:在我们计算的八个指标中下单和支付有完整的商品信息,其他6个指标都没有商品的完整信息,所以我们需要去hbase中查询商品信息,针对每一条数据,都去hbase中查询一次,然后补充信息,但是这样效率很低,那么我们能否把其他6张表数据全部unuin起来,然后查询,这样的话查询次数并没有减少,但是从代码角度,代码少写很多。
所以我们采取首先对所有数据按照sku_id进行分组聚合,然后再去查询,这样代码量少了,查询次数也少了。
这样的话,dwm层订单和支付宽表也没必要首先聚合一次啊,在这里直接去dwd层查询也可以啊,那么为什么先要在dwm层做一次处理,为什么?
需要给ads层使用。
之前在离线数仓中,dws和dwt层只能应对我们生产环境中绝大多数需求和指标,不可能意义应对,有的指标还要从dwd层提取计算,所以在离线数仓中也一样,dwm层并不多余,而是给处理dws层之外的层次准备数据。
每一条日志都有common,page,ts属性。
功能实现
封装商品统计实体类 ProductStats
在这里需要注意一下,商品宽表实体类的创建使用的是建造者模式,,因为实体里面的字段很多,如果普通的赋值,很麻烦,所以使用建造者模式,可以设置默认值。
/**
* Desc: 商品统计实体类
*
* @Builder注解 可以使用构造者方式创建对象,给属性赋值
* @Builder.Default 在使用构造者方式给属性赋值的时候,属性的初始值会丢失
* 该注解的作用就是修复这个问题
* 例如:我们在属性上赋值了初始值为0L,如果不加这个注解,通过构造者创建的对象属性值会变为null
*/
@Data
@Builder //添加了builder的话,引用值默认是null
public class ProductStats {
String stt;//窗口起始时间
String edt; //窗口结束时间
Long sku_id; //sku编号
String sku_name;//sku名称
BigDecimal sku_price; //sku单价
Long spu_id; //spu编号
String spu_name;//spu名称
Long tm_id; //品牌编号
String tm_name;//品牌名称
Long category3_id;//品类编号
String category3_name;//品类名称
// 上面是8个维度信息,多加一个单价
@Builder.Default//添加default后,会保留自定义的默认值,否则初始化为null
Long display_ct = 0L; //曝光数
@Builder.Default
Long click_ct = 0L; //点击数
@Builder.Default
Long favor_ct = 0L; //收藏数
@Builder.Default
Long cart_ct = 0L; //添加购物车数
@Builder.Default
Long order_sku_num = 0L; //下单商品个数
@Builder.Default //下单商品金额
BigDecimal order_amount = BigDecimal.ZERO;
//************************************
// 订单数,支付订单数,退款订单数,我们都要做去重操作
@Builder.Default
Long order_ct = 0L; //订单数
@Builder.Default //支付金额
BigDecimal payment_amount = BigDecimal.ZERO;
@Builder.Default
Long paid_order_ct = 0L; //支付订单数
@Builder.Default
Long refund_order_ct = 0L; //退款订单数
@Builder.Default
BigDecimal refund_amount = BigDecimal.ZERO;
@Builder.Default
Long comment_ct = 0L;//评论订单数
@Builder.Default
Long good_comment_ct = 0L; //好评订单数
// 三个set用户辅助去重操作
@Builder.Default
@TransientSink
Set orderIdSet = new HashSet(); //用于统计订单数
@Builder.Default
@TransientSink
Set paidOrderIdSet = new HashSet(); //用于统计支付订单数
@Builder.Default
@TransientSink//加了注解,那么在赋值的时候将会被跳过,并不会写入ck数据库
Set refundOrderIdSet = new HashSet();//用于退款支付订单数
Long ts; //统计时间戳,使用事件时间开窗
}注意:在ProductStats里面使用了创建者模式取创建一个对象,因为该类里面的属性是比较多的,如果对属性一一赋值的话,那么需要很多冗余代码,使用构造者模式,只需要给需要赋值的属性赋值即可。
创建 ProductStatsApp,从 Kafka 主题中获得数据流
//TODO 2.读取Kafka 7个主题的 数据创建流
String groupId = "product_stats_app";
String pageViewSourceTopic = "dwd_page_log";//获得点击和曝光数据流
String orderWideSourceTopic = "dwm_order_wide";//下单数据流
String paymentWideSourceTopic = "dwm_payment_wide";//订单支付数据流
String cartInfoSourceTopic = "dwd_cart_info";//购物车数据流
String favorInfoSourceTopic = "dwd_favor_info";//收藏数据流
String refundInfoSourceTopic = "dwd_order_refund_info";//退款数据流
String commentInfoSourceTopic = "dwd_comment_info";//评论数据流
DataStreamSource<String> pvDS = env.addSource(MyKafkaUtils.getKafkaConsumer(pageViewSourceTopic, groupId));
DataStreamSource<String> favorDS = env.addSource(MyKafkaUtils.getKafkaConsumer(favorInfoSourceTopic, groupId));
DataStreamSource<String> cartDS = env.addSource(MyKafkaUtils.getKafkaConsumer(cartInfoSourceTopic, groupId));
DataStreamSource<String> orderDS = env.addSource(MyKafkaUtils.getKafkaConsumer(orderWideSourceTopic, groupId));
DataStreamSource<String> payDS = env.addSource(MyKafkaUtils.getKafkaConsumer(paymentWideSourceTopic, groupId));
DataStreamSource<String> refundDS = env.addSource(MyKafkaUtils.getKafkaConsumer(refundInfoSourceTopic, groupId));
DataStreamSource<String> commentDS = env.addSource(MyKafkaUtils.getKafkaConsumer(commentInfoSourceTopic, groupId));把 JSON 字符串数据流转换为统一数据对象的数据流
//TODO 3.将7个流统一数据格式
// 出点击和曝光两个指标
SingleOutputStreamOperator<ProductStats> productStatsWithClickAndDisplayDS = pvDS.flatMap(new FlatMapFunction<String, ProductStats>() {
@Override
public void flatMap(String value, Collector<ProductStats> out) throws Exception {
/**
* 如何判断是点击数据
* 如果是搜索,那么他进入的页面是good_list,page_id是good_list也就是商品列表
* 如果是点击,那么他的吓一跳page_id是good_detail
* 曝光数据的话,直接访问display即可
*/
//将数据转换为JSON对象
JSONObject jsonObject = JSON.parseObject(value);
//取出page信息,也就是获取当前页面信息
JSONObject page = jsonObject.getJSONObject("page");
// 获取page_id,看上一次页面的id
String pageId = page.getString("page_id");
// 获取时间戳
Long ts = jsonObject.getLong("ts");
// 如果上一个页面的id是good_detail,那么就说明是一个点击数据
// 也就是说当前页面必须是详情页,并且点击的是某一个sku_id
if ("good_detail".equals(pageId) && "sku_id".equals(page.getString("item_type"))) {
out.collect(ProductStats.builder()
.sku_id(page.getLong("item"))
.click_ct(1L)
.ts(ts)
.build());
}
//尝试取出曝光数据,曝光是一个数组
JSONArray displays = jsonObject.getJSONArray("displays");
if (displays != null && displays.size() > 0) {
for (int i = 0; i < displays.size(); i++) {
//取出单条曝光数据
JSONObject display = displays.getJSONObject(i);
// 判断曝光的是否是商品类型,不能曝光活动
if ("sku_id".equals(display.getString("item_type"))) {
out.collect(ProductStats.builder()
.sku_id(display.getLong("item"))
.display_ct(1L)//曝光了一次
.ts(ts)
.build());
}
}
}
}
});
// 收藏的指标
SingleOutputStreamOperator<ProductStats> productStatsWithFavorDS = favorDS.map(line -> {
JSONObject jsonObject = JSON.parseObject(line);
return ProductStats.builder()
.sku_id(jsonObject.getLong("sku_id"))//获取商品号
.favor_ct(1L)//收藏的次数+1
.ts(DateTimeUtil.toTs(jsonObject.getString("create_time")))
.build();
});
// 加入购物车,我们只需要算一个指标:添加购物车的次数
SingleOutputStreamOperator<ProductStats> productStatsWithCartDS = cartDS.map(line -> {
JSONObject jsonObject = JSON.parseObject(line);
return ProductStats.builder()
.sku_id(jsonObject.getLong("sku_id"))
.cart_ct(1L)//添加+1
.ts(DateTimeUtil.toTs(jsonObject.getString("create_time")))
.build();
});
// 下单指标
/**
* 指标:
* 1 下单商品的个数,累加即可
* 2 下单商品总金额,累加即可
* 3 订单数,我们通过辅助字段
*/
SingleOutputStreamOperator<ProductStats> productStatsWithOrderDS = orderDS.map(line -> {
// 因为有订单宽表,所以我们直接获取订单宽表对象
OrderWide orderWide = JSON.parseObject(line, OrderWide.class);
HashSet<Long> orderIds = new HashSet<>();
orderIds.add(orderWide.getOrder_id());
return ProductStats.builder()
.sku_id(orderWide.getSku_id())//商品sku_id
.order_sku_num(orderWide.getSku_num())//商品的件数
.order_amount(orderWide.getSplit_total_amount())//商品总件数
.orderIdSet(orderIds)//订单的总次数需要去重,因为可能有多件商品在一个订单,所以需要根据订单id进行去重操作
.ts(DateTimeUtil.toTs(orderWide.getCreate_time()))
.build();
});
// 支付指标,也有javabean对象
/**
* 1. 支付金额
* 2.支付订单数,去重
*/
SingleOutputStreamOperator<ProductStats> productStatsWithPaymentDS = payDS.map(line -> {
// 获取javabean
PaymentWide paymentWide = JSON.parseObject(line, PaymentWide.class);
HashSet<Long> orderIds = new HashSet<>();
orderIds.add(paymentWide.getOrder_id());
return ProductStats.builder()
.sku_id(paymentWide.getSku_id())
.payment_amount(paymentWide.getSplit_total_amount())//支付金额,使用明细表中的金额
.paidOrderIdSet(orderIds)
.ts(DateTimeUtil.toTs(paymentWide.getPayment_create_time()))
.build();
});
// 退款
/**
* 退款订单数
* 2.退款金额
*/
SingleOutputStreamOperator<ProductStats> productStatsWithRefundDS = refundDS.map(line -> {
JSONObject jsonObject = JSON.parseObject(line);
HashSet<Long> orderIds = new HashSet<>();
orderIds.add(jsonObject.getLong("order_id"));
return ProductStats.builder()
.sku_id(jsonObject.getLong("sku_id"))
.refund_amount(jsonObject.getBigDecimal("refund_amount"))
.refundOrderIdSet(orderIds)//需要去重
.ts(DateTimeUtil.toTs(jsonObject.getString("create_time")))
.build();
});
/**
* 评价
*
* 1.评论订单数
* 2.好评订单数
*
*
* sku_id,create_time这两个字段是所有指标都必须有的
*/
SingleOutputStreamOperator<ProductStats> productStatsWithCommentDS = commentDS.map(line -> {
JSONObject jsonObject = JSON.parseObject(line);
String appraise = jsonObject.getString("appraise");
long goodCt = 0L;
// 根据常量表查询
if (GmallConstant.APPRAISE_GOOD.equals(appraise)) {
goodCt = 1L;
}
return ProductStats.builder()
.sku_id(jsonObject.getLong("sku_id"))
.comment_ct(1L)
.good_comment_ct(goodCt)
.ts(DateTimeUtil.toTs(jsonObject.getString("create_time")))
.build();
});创建电商业务常量类 GmallConstant
public class GmallConfig {
//Phoenix 库名
public static final String HBASE_SCHEMA = "GMALL2021_REALTIME";
//Phoenix 驱动
public static final String PHOENIX_DRIVER = "org.apache.phoenix.jdbc.PhoenixDriver";
//Phoenix 连接参数
public static final String PHOENIX_SERVER =
"jdbc:phoenix:hadoop102,hadoop103,hadoop104:2181";
// CK的url
public static final String
CLICKHOUSE_URL="jdbc:clickhouse://hadoop102:8123/default";
// ck的driver
public static final String CLICKHOUSE_DRIVER =
"ru.yandex.clickhouse.ClickHouseDriver";
}把统一的数据结构流合并为一个流
//TODO 4.Union 7个流
/**
* 输入的7个数据流类型都是一样的,所以union会将七个流合并为一个流输出
*/
DataStream<ProductStats> unionDS = productStatsWithClickAndDisplayDS.union(
productStatsWithFavorDS,
productStatsWithCartDS,
productStatsWithOrderDS,
productStatsWithPaymentDS,
productStatsWithRefundDS,
productStatsWithCommentDS);设定事件时间与水位线
//TODO 5.提取时间戳生成WaterMark
/**
* 因为需要开创,所以需要考虑乱序问题,给2s的延迟时间
*/
SingleOutputStreamOperator<ProductStats> productStatsWithWMDS = unionDS.assignTimestampsAndWatermarks(WatermarkStrategy.<ProductStats>forBoundedOutOfOrderness(Duration.ofSeconds(2)).withTimestampAssigner(new SerializableTimestampAssigner<ProductStats>() {
@Override
public long extractTimestamp(ProductStats element, long recordTimestamp) {
return element.getTs();
}
}));分组、开窗、聚合
//TODO 6.分组、开窗、聚合 按照sku_id分组,10秒的滚动窗口,结合增量聚合(累加值)和全量聚合(提取窗口信息)
SingleOutputStreamOperator<ProductStats> reduceDS = productStatsWithWMDS.keyBy(ProductStats::getSku_id)
// 10秒的滚动窗口
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
// 增量聚合
.reduce(new ReduceFunction<ProductStats>() {
@Override
public ProductStats reduce(ProductStats stats1, ProductStats stats2) throws Exception {
stats1.setDisplay_ct(stats1.getDisplay_ct() + stats2.getDisplay_ct());
stats1.setClick_ct(stats1.getClick_ct() + stats2.getClick_ct());
stats1.setCart_ct(stats1.getCart_ct() + stats2.getCart_ct());
stats1.setFavor_ct(stats1.getFavor_ct() + stats2.getFavor_ct());
stats1.setOrder_amount(stats1.getOrder_amount().add(stats2.getOrder_amount()));
stats1.getOrderIdSet().addAll(stats2.getOrderIdSet());
//stats1.setOrder_ct(stats1.getOrderIdSet().size() + 0L);
stats1.setOrder_sku_num(stats1.getOrder_sku_num() + stats2.getOrder_sku_num());
stats1.setPayment_amount(stats1.getPayment_amount().add(stats2.getPayment_amount()));
stats1.getRefundOrderIdSet().addAll(stats2.getRefundOrderIdSet());
//stats1.setRefund_order_ct(stats1.getRefundOrderIdSet().size() + 0L);
stats1.setRefund_amount(stats1.getRefund_amount().add(stats2.getRefund_amount()));
stats1.getPaidOrderIdSet().addAll(stats2.getPaidOrderIdSet());
//stats1.setPaid_order_ct(stats1.getPaidOrderIdSet().size() + 0L);
stats1.setComment_ct(stats1.getComment_ct() + stats2.getComment_ct());
stats1.setGood_comment_ct(stats1.getGood_comment_ct() + stats2.getGood_comment_ct());
return stats1;
}
}, new WindowFunction<ProductStats, ProductStats, Long, TimeWindow>() {
// win fun获取窗口的时间,做全量聚合,这里面只有一条数据
@Override
public void apply(Long aLong, TimeWindow window, Iterable<ProductStats> input, Collector<ProductStats> out) throws Exception {
//取出数据
ProductStats productStats = input.iterator().next();
//设置窗口时间
productStats.setStt(DateTimeUtil.toYMDhms(new Date(window.getStart())));
productStats.setEdt(DateTimeUtil.toYMDhms(new Date(window.getEnd())));
//设置订单数量
productStats.setOrder_ct((long) productStats.getOrderIdSet().size());
productStats.setPaid_order_ct((long) productStats.getPaidOrderIdSet().size());
productStats.setRefund_order_ct((long) productStats.getRefundOrderIdSet().size());
//将数据写出
out.collect(productStats);
}
});补充商品维度信息
//TODO 7.关联维度信息
/**
* 关联维度,我们使用异步io
*
* 关联维度信息,其实就是去hbase中查询维度数据,然后把bean中的属性补充完整
*/
//7.1 关联SKU维度
SingleOutputStreamOperator<ProductStats> productStatsWithSkuDS = AsyncDataStream.unorderedWait(reduceDS,
// 在这里去Hbase中查询维度表信息
new DimAsyncFunction<ProductStats>("DIM_SKU_INFO") {
@Override
public String getKey(ProductStats productStats) {
// key是产品的sku_id
return productStats.getSku_id().toString();
}
@Override
public void join(ProductStats productStats, JSONObject dimInfo) throws ParseException {
productStats.setSku_name(dimInfo.getString("SKU_NAME"));
productStats.setSku_price(dimInfo.getBigDecimal("PRICE"));
productStats.setSpu_id(dimInfo.getLong("SPU_ID"));
productStats.setTm_id(dimInfo.getLong("TM_ID"));
productStats.setCategory3_id(dimInfo.getLong("CATEGORY3_ID"));
}
}, 60, TimeUnit.SECONDS);
//7.2 关联SPU维度
SingleOutputStreamOperator<ProductStats> productStatsWithSpuDS =
AsyncDataStream.unorderedWait(productStatsWithSkuDS,
new DimAsyncFunction<ProductStats>("DIM_SPU_INFO") {
@Override
public void join(ProductStats productStats, JSONObject jsonObject) throws ParseException {
productStats.setSpu_name(jsonObject.getString("SPU_NAME"));
}
@Override
public String getKey(ProductStats productStats) {
return String.valueOf(productStats.getSpu_id());
}
}, 60, TimeUnit.SECONDS);
//7.3 关联Category维度
SingleOutputStreamOperator<ProductStats> productStatsWithCategory3DS =
AsyncDataStream.unorderedWait(productStatsWithSpuDS,
new DimAsyncFunction<ProductStats>("DIM_BASE_CATEGORY3") {
@Override
public void join(ProductStats productStats, JSONObject jsonObject) throws ParseException {
productStats.setCategory3_name(jsonObject.getString("NAME"));
}
@Override
public String getKey(ProductStats productStats) {
return String.valueOf(productStats.getCategory3_id());
}
}, 60, TimeUnit.SECONDS);
//7.4 关联TM维度
SingleOutputStreamOperator<ProductStats> productStatsWithTmDS =
AsyncDataStream.unorderedWait(productStatsWithCategory3DS,
new DimAsyncFunction<ProductStats>("DIM_BASE_TRADEMARK") {
@Override
public void join(ProductStats productStats, JSONObject jsonObject) throws ParseException {
productStats.setTm_name(jsonObject.getString("TM_NAME"));
}
@Override
public String getKey(ProductStats productStats) {
return String.valueOf(productStats.getTm_id());
}
}, 60, TimeUnit.SECONDS);在 ClickHouse 中创建商品主题宽表
create table product_stats_2021 (
stt DateTime,
edt DateTime,
sku_id UInt64,
sku_name String,
sku_price Decimal64(2),
spu_id UInt64,
spu_name String ,
tm_id UInt64,
tm_name String,
category3_id UInt64,
category3_name String ,
display_ct UInt64,
click_ct UInt64,
favor_ct UInt64,
cart_ct UInt64,
order_sku_num UInt64,
order_amount Decimal64(2),
order_ct UInt64 ,
payment_amount Decimal64(2),
paid_order_ct UInt64,
refund_order_ct UInt64,
refund_amount Decimal64(2),
comment_ct UInt64,
good_comment_ct UInt64 ,
ts UInt64
)engine =ReplacingMergeTree(ts)
partition by toYYYYMMDD(stt)
order by (stt,edt,sku_id );写入 ClickHouse
//TODO 8.将数据写入ClickHouse
productStatsWithTmDS.print();
productStatsWithTmDS.addSink(ClickHouseUtil.getSink("insert into table product_stats_210325 values(?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?)"));DWS 层地区主题表(FlinkSQL)

地区主题宽表主要是反映各个地区的销售情况。从业务逻辑上地区主题比起商品更加简单,业务逻辑也没有什么特别的就是做一次轻度聚合然后保存,所以在这里我们体验一下使用FlinkSQL,来完成该业务。
需求分析与思路
- 定义 Table 流环境
- 把数据源定义为动态表
- 通过 SQL 查询出结果表
- 把结果表转换为数据流
- 把数据流写入目标数据库
在这里为什们没有使用Flink sql直接向外面写数据,因为直接使用Flink sql的话我们需要去写一套功能,将Flink sql数据写入到ck,中,但是我们之前已经写好了如何将数据流写入到ck中,所以这样更加的方便。
如果是Flink官方支持的数据库,也可以直接把目标数据表定义为动态表,用insert into写入。由于ClickHouse目前官方没有支持的jdbc连接器(目前支持Mysql、 PostgreSQL、Derby)。也可以制作自定义 sink,实现官方不支持的连接器。但是比较繁琐。
这个宽表难点有两个:
- 提取事件时间生成watermark。
- 第二个是开窗。
功能实现
创建 ProvinceStatsSqlApp,定义 Table 流环境
// 获取表的执行环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);把数据源定义为动态表
其中 WATERMARK FOR rowtime AS rowtime 是把某个虚拟字段设定为 EVENT_TIME
//TODO 2.使用DDL创建表 提取时间戳生成WaterMark,这一步是难点
String groupId = "province_stats";
String orderWideTopic = "dwm_order_wide";//数据源
tableEnv.executeSql("CREATE TABLE order_wide ( " +
" `province_id` BIGINT, " +
" `province_name` STRING, " +
" `province_area_code` STRING, " +
" `province_iso_code` STRING, " +
" `province_3166_2_code` STRING, " +
" `order_id` BIGINT, " +
" `split_total_amount` DECIMAL, " +
" `create_time` STRING, " +//将这个字段转换为TIMESTAMP(3)这种类型
" `rt` as TO_TIMESTAMP(create_time), " +//rt是事件事件
//rt - INTERVAL '1' SECONDwatermart延迟的事件如果不写,那么使用的就是ascending这种方式生成watermark
" WATERMARK FOR rt AS rt - INTERVAL '1' SECOND ) with(" +
MyKafkaUtils.getKafkaDDL(orderWideTopic, groupId) + ")");MyKafkaUtil 增加一个 DDL 的方法
//拼接Kafka相关属性到DDL
public static String getKafkaDDL(String topic, String groupId) {
return " 'connector' = 'kafka', " +
" 'topic' = '" + topic + "'," +
" 'properties.bootstrap.servers' = '" + brokers + "', " +
" 'properties.group.id' = '" + groupId + "', " +
" 'format' = 'json', " +
" 'scan.startup.mode' = 'latest-offset' ";
}聚合计算
//TODO 3.查询数据 分组、开窗、聚合 这一步也是难点
Table table = tableEnv.sqlQuery("select " +
// 获取窗口的开始和结束时间
" DATE_FORMAT(TUMBLE_START(rt, INTERVAL '10' SECOND), 'yyyy-MM-dd HH:mm:ss') stt, " +
" DATE_FORMAT(TUMBLE_END(rt, INTERVAL '10' SECOND), 'yyyy-MM-dd HH:mm:ss') edt, " +
" province_id, " +
" province_name, " +
" province_area_code, " +
" province_iso_code, " +
" province_3166_2_code, " +
" count(distinct order_id) order_count, " +
" sum(split_total_amount) order_amount, " +
" UNIX_TIMESTAMP()*1000 ts " +
"from " +
" order_wide " +
"group by " +
" province_id, " +
" province_name, " +
" province_area_code, " +
" province_iso_code, " +
" province_3166_2_code, " +
" TUMBLE(rt, INTERVAL '10' SECOND)");转为数据流
//TODO 4.将动态表转换为流
DataStream<ProvinceStats> provinceStatsDataStream = tableEnv.toAppendStream(table, ProvinceStats.class);定义地区统计宽表实体类 ProvinceStats
/**
* Desc:地区统计宽表实体类
*/
@AllArgsConstructor
@NoArgsConstructor
@Data
public class ProvinceStats {
private String stt;
private String edt;
private Long province_id;
private String province_name;
private String province_area_code;
private String province_iso_code;
private String province_3166_2_code;
private BigDecimal order_amount;
private Long order_count;
private Long ts;
public ProvinceStats(OrderWide orderWide) {
province_id = orderWide.getProvince_id();
order_amount = orderWide.getSplit_total_amount();
province_name = orderWide.getProvince_name();
province_area_code = orderWide.getProvince_area_code();
province_iso_code = orderWide.getProvince_iso_code();
province_3166_2_code = orderWide.getProvince_3166_2_code();
order_count = 1L;
ts = new Date().getTime();
}
}在 ClickHouse 中创建地区主题宽表
create table province_stats (
stt DateTime,
edt DateTime,
province_id UInt64,
province_name String,
area_code String,
iso_code String,
iso_3166_2 String,
order_amount Decimal64(2),
order_count UInt64,
ts UInt64
)engine =ReplacingMergeTree(ts)
partition by toYYYYMMDD(stt)
order by (stt,edt,province_id);写入 ClickHouse
//TODO 5.打印数据并写入ClickHouse
provinceStatsDataStream.print();
provinceStatsDataStream.addSink(ClickHouseUtil.getSink("insert into province_stats values(?,?,?,?,?,?,?,?,?,?)"));DWS 层关键词主题表(FlinkSQL)
关键词主题这个主要是为了大屏展示中的字符云的展示效果,用于感性的让大屏观看者感知目前的用户都更关心的那些商品和关键词。
关键词的展示也是一种维度聚合的结果,根据聚合的大小来决定关键词的大小。
关键词的第一重要来源的就是用户在搜索栏的搜索,另外就是从以商品为主题的统计中获取关键词。
关于分词
因为无论是从用户的搜索栏中,还是从商品名称中文字都是可能是比较长的,且由多个关键词组成
所以我们需要根据把长文本分割成一个一个的词,这种分词技术,在搜索引擎中可能会用到。对于中文分词,现在的搜索引擎基本上都是使用的第三方分词器,咱们在计算数据中也可以,使用和搜索引擎中一致的分词器,IK。
搜索关键词功能实现
IK 分词器的使用
封装分词工具类并进行测试
public class KeywordUtil {
/**
* 输入一个字符串,返回切好的词
* @param keyWord
* @return
* @throws IOException
*/
public static List<String> splitKeyWord(String keyWord) throws IOException {
//创建集合用于存放结果数据
ArrayList<String> resultList = new ArrayList<>();
StringReader reader = new StringReader(keyWord);
IKSegmenter ikSegmenter = new IKSegmenter(reader, false);
while (true) {
Lexeme next = ikSegmenter.next();
if (next != null) {
String word = next.getLexemeText();
resultList.add(word);
} else {
break;
}
}
//返回结果数据
return resultList;
}
public static void main(String[] args) throws IOException {
System.out.println(splitKeyWord("尚硅谷大数据项目之实时数仓"));
}
}自定义函数
有了分词器,那么另外一个要考虑的问题就是如何把分词器的使用揉进 FlinkSQL 中。因为 SQL 的语法和相关的函数都是 Flink 内定的,想要使用外部工具,就必须结合自定义函数。
在Flink中,有四种自定义函数:
- Scalar Fun:标量函数,一进一出。(相当于 Spark 的 UDF),
- Table Fun:表函数,udtf,(相当于 Spark 的 UDTF),
- Aggregate Fun:聚合函数,udaf,多进一出。 (相当于 Spark 的 UDAF)
- table Aggregate Fun:表聚合函数,这种自定义函数只能够用在table的api里面,无法在sql中使用。
前三种自定义函数可以在sql中使用,也可以在table api中使用。

// define function logic
public static class SubstringFunction extends ScalarFunction {
public String eval(String s, Integer begin, Integer end) {
return s.substring(begin, end);
}
}
TableEnvironment env = TableEnvironment.create(...);
// call function "inline" without registration in Table API
env.from("MyTable").select(call(SubstringFunction.class, $("myField"), 5, 12));
// register function
env.createTemporarySystemFunction("SubstringFunction", SubstringFunction.class);
// call registered function in Table API
env.from("MyTable").select(call("SubstringFunction", $("myField"), 5, 12));
// call registered function in SQL
env.sqlQuery("SELECT SubstringFunction(myField, 5, 12) FROM MyTable");考虑到一个词条包括多个词语所以分词是指一种一对多的拆分,一拆多的情况,我们应该选择 Table Function。
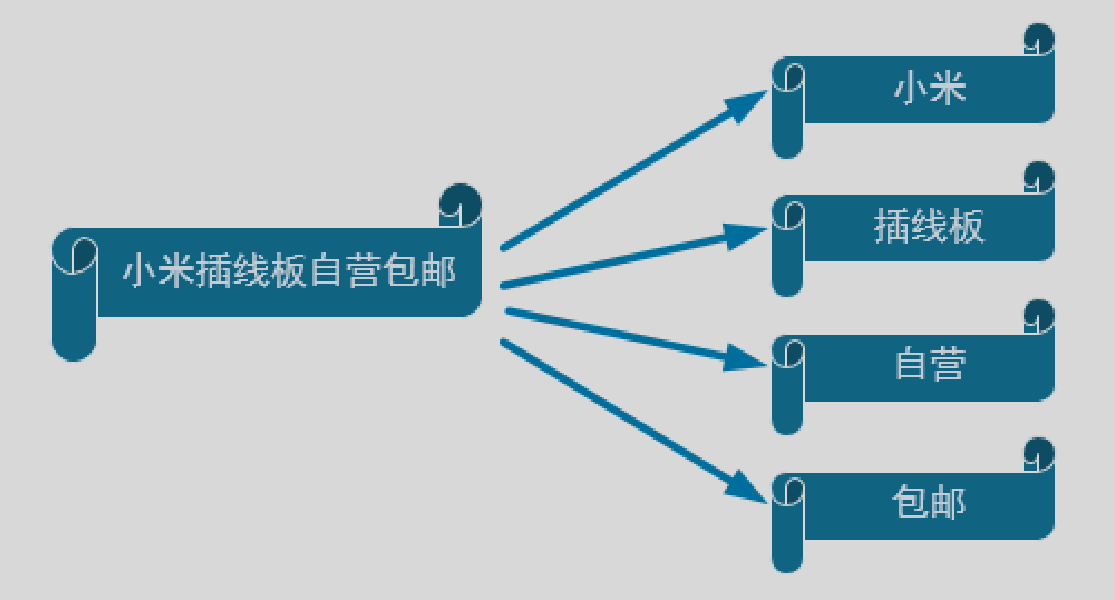
封装 KeywordUDTF 函数
@FunctionHint 主要是为了标识输出数据的类型
row.setField(0,keyword)中的 0 表示返回值下标为 0 的值
**
* 自定义函数,实现炸裂功能,将一个字符串炸裂为多个行输出
*/
//注解表示输出的列名字和列的类型
@FunctionHint(output = @DataTypeHint("ROW<word STRING>"))
public class SplitFunction extends TableFunction<Row> {
public void eval(String str) {
try {
//分词
List<String> words = KeywordUtil.splitKeyWord(str);
//遍历并写出
for (String word : words) {
collect(Row.of(word));
}
} catch (IOException e) {
collect(Row.of(str));
}
}
}创建 KeywordStatsApp,定义流环境
//TODO 1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);声明动态表和自定义函数
注意 json 格式的要定义为 Map 对象
//TODO 2.使用DDL方式读取Kafka数据创建表
String groupId = "keyword_stats_app";
String pageViewSourceTopic = "dwd_page_log";
tableEnv.executeSql("create table page_view( " +
" `common` Map<STRING,STRING>, " +
" `page` Map<STRING,STRING>, " +
" `ts` BIGINT, " +
// FROM_UNIXTIME:将数字转换为时间的标准格式
" `rt` as TO_TIMESTAMP(FROM_UNIXTIME(ts/1000)), " +
" WATERMARK FOR rt AS rt - INTERVAL '1' SECOND " +
") with (" + MyKafkaUtils.getKafkaDDL(pageViewSourceTopic, groupId) + ")");过滤数据
//TODO 3.过滤数据 上一跳页面为"search" and 搜索词 is not null,这里过滤null可能我们没有在搜索框里面输入任何东西,所以需要过滤掉
Table fullWordTable = tableEnv.sqlQuery("" +
"select " +
" page['item'] full_word, " +
" rt " +
"from " +
" page_view " +
"where " +
" page['last_page_id']='search' and page['item'] is not null");利用 UDTF 进行拆分
//TODO 4.注册UDTF,进行分词处理
tableEnv.createTemporarySystemFunction("split_words", SplitFunction.class);
Table wordTable = tableEnv.sqlQuery("" +
"SELECT " +
" word, " +
" rt " +
"FROM " +
" " + fullWordTable + ", LATERAL TABLE(split_words(full_word))");聚合
//TODO 5.分组、开窗、聚合
Table resultTable = tableEnv.sqlQuery("" +
"select " +
" 'search' source, " +
" DATE_FORMAT(TUMBLE_START(rt, INTERVAL '10' SECOND), 'yyyy-MM-dd HH:mm:ss') stt, " +
" DATE_FORMAT(TUMBLE_END(rt, INTERVAL '10' SECOND), 'yyyy-MM-dd HH:mm:ss') edt, " +
" word keyword, " +
" count(*) ct, " +
" UNIX_TIMESTAMP()*1000 ts " +
"from " + wordTable + " " +
"group by " +
" word, " +
" TUMBLE(rt, INTERVAL '10' SECOND)");在 ClickHouse 中创建关键词统计表
create table keyword_stats (
stt DateTime,
edt DateTime,
keyword String ,
source String ,
ct UInt64 ,
ts UInt64
)engine =ReplacingMergeTree( ts)
partition by toYYYYMMDD(stt)
order by ( stt,edt,keyword,source );封装 KeywordStats 实体类
/**
* Desc: 关键词统计实体类
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class KeywordStats {
private String keyword;
private Long ct;
private String source;//表示当前的关键词的来源,因为关键词的来源不止一个地方,有的从搜索框中来,有的是中其他地方统计出来的
private String stt;
private String edt;
private Long ts;
}转换为流并写入 ClickHouse
//TODO 6.将动态表转换为流
DataStream<KeywordStats> keywordStatsDataStream = tableEnv.toAppendStream(resultTable, KeywordStats.class);
//TODO 7.将数据打印并写入ClickHouse
keywordStatsDataStream.print();
keywordStatsDataStream.addSink(ClickHouseUtil.getSink("insert into keyword_stats(keyword,ct,source,stt,edt,ts) values(?,?,?,?,?,?)"));小结
VisitorStatsApp
VisitorStats
访客统计实体类
ClickHouseUtil
DateTimeUtil
实现DateTimeUtil格式化时间线程安全工具类
TransientSink
创建注解TransientSink
ProductStats
ProductStatsApp
GmallConfig
ProvinceStatsSqlApp
ProvinceStats
地区宽表实体对象。
KeywordStatsApp
KeywordUtil
切分字符串工具类
SplitFunction
自定义udtf函数
KeywordStats
关键词宽表实体类
小结
- DWS 层主要是基于 DWD 和 DWM 层的数据进行轻度聚合统计
- 掌握利用 union 操作实现多流的合并
- 掌握窗口聚合操作
- 掌握对 clickhouse 数据库的写入操作
- 掌握用 FlinkSQL 实现业务
- 掌握分词器的使用
- 掌握在 FlinkSQL 中自定义函数的使用
贡献者
 codingLab
codingLab版权所有
版权归属:
许可证: