4、实时数仓DWM层业务实现
DWM 层的设计
设计思路
我们在之前通过分流等手段,把数据分拆成了独立的 Kafka Topic。那么接下来如何处理数据,就要思考一下我们到底要通过实时计算出哪些指标项。
因为实时计算与离线不同,实时计算的开发和运维成本都是非常高的,要结合实际情况考虑是否有必要象离线数仓一样,建一个大而全的中间层。
如果没有必要大而全,这时候就需要大体规划一下要实时计算出的指标需求了。把这些指标以主题宽表的形式输出就是我们的 DWS 层。
需求梳理


为什么在实时数仓中没有DWT层,因为DWT层存放的是历史的聚集的结果,实时数仓中不需要这一层,可以实时计算。
当然实际需求还会有更多,这里主要以为可视化大屏为目的进行实时计算的处理。
DWM 层的定位是什么,DWM 层主要服务 DWS,因为部分需求直接从 DWD 层到DWS 层中间会有一定的计算量,而且这部分计算的结果很有可能被多个 DWS 层主题复用,
所以部分 DWD 成会形成一层 DWM,我们这里主要涉及业务。
- 访问 UV 计算
- 跳出明细计算
- 订单宽表
- 支付宽表
业务属于
用户
用户以设备为判断标准,在移动统计中,每个独立设备认为是一个独立用户。Android系统根据IMEI号,IOS系统根据OpenUDID来标识一个独立用户,每部手机一个用户。
新增用户
首次联网使用应用的用户。如果一个用户首次打开某APP,那这个用户定义为新增用户;卸载再安装的设备,不会被算作一次新增。新增用户包括日新增用户、周新增用户、月新增用户。
活跃用户
打开应用的用户即为活跃用户,不考虑用户的使用情况。每天一台设备打开多次会被计为一个活跃用户。
周(月)活跃用户
某个自然周(月)内启动过应用的用户,该周(月)内的多次启动只记一个活跃用户。
月活跃率
月活跃用户与截止到该月累计的用户总和之间的比例。
沉默用户
用户仅在安装当天(次日)启动一次,后续时间无再启动行为。该指标可以反映新增用户质量和用户与APP的匹配程度。
版本分布
不同版本的周内各天新增用户数,活跃用户数和启动次数。利于判断APP各个版本之间的优劣和用户行为习惯。
本周回流用户
上周未启动过应用,本周启动了应用的用户。
连续n周活跃用户
连续n周,每周至少启动一次。
忠实用户
连续活跃5周以上的用户
连续活跃用户
连续2周及以上活跃的用户
近期流失用户
连续n(2<= n <= 4)周没有启动应用的用户。(第n+1周没有启动过)
留存用户
某段时间内的新增用户,经过一段时间后,仍然使用应用的被认作是留存用户;这部分用户占当时新增用户的比例即是留存率。
例如,5月份新增用户200,这200人在6月份启动过应用的有100人,7月份启动过应用的有80人,8月份启动过应用的有50人;则5月份新增用户一个月后的留存率是50%,二个月后的留存率是40%,三个月后的留存率是25%。
用户新鲜度
每天启动应用的新老用户比例,即新增用户数占活跃用户数的比例。
单次使用时长
每次启动使用的时间长度。
日使用时长
累计一天内的使用时间长度。
启动次数计算标准
IOS平台应用退到后台就算一次独立的启动;Android平台我们规定,两次启动之间的间隔小于30秒,被计算一次启动。用户在使用过程中,若因收发短信或接电话等退出应用30秒又再次返回应用中,那这两次行为应该是延续而非独立的,所以可以被算作一次使用行为,即一次启动。业内大多使用30秒这个标准,但用户还是可以自定义此时间间隔。
DWM层访客 UV 计算
需求分析与思路
UV,全称是 Unique Visitor,即独立访客,对于实时计算中,也可以称为 DAU(Daily Active User),即每日活跃用户,因为实时计算中的 UV 通常是指当日的访客数。
那么如何从用户行为日志中识别出当日的访客,那么有两点:
- 其一,是识别出该访客打开的第一个页面,表示这个访客开始进入我们的应用
那具体在这里我们根据哪一个字段进行判断呢?
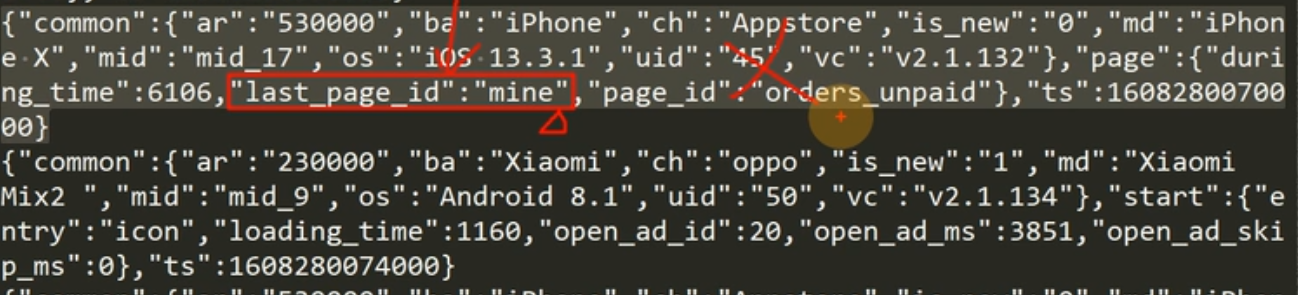
我们根据日志中的last_page_id判断,如果该字段是null,那么说明是今天第一次登录该页面,否则不空,也就是说不是第一次。这个字段代表上一跳的地址,为null说明没有上一跳。
- 其二,由于访客可以在一天中多次进入应用,所以我们要在一天的范围内进行去重,因为用户每一次访问页面,都会产生一个访问日志。
因为我们要统计日活跃量,而每一个访客可以多次重复登录,所以需要进行去重操作。我们可以使用Flink中的keyStated,一个mid对应于一个状态。key1-->state,状态中可以存储年月日时间。
数据流:模拟生成数据->日志处理服务器->写到 kafka 的 ODS 层(ods_base_log) ->BaseLogApp分流->dwd_page_log->UniqueVisitApp 读取输出
代码实现
从 Kafka 的 dwd_page_log 主题接收数据
//TODO 2.读取Kafka dwd_page_log 主题的数据
String groupId = "unique_visit_app";//消费者组
String sourceTopic = "dwd_page_log";//dwd层数据源,是kafka中的一个主题
String sinkTopic = "dwm_unique_visit";//存放在kafka中的dwm_unique_visit主题中
// 读取数据
DataStreamSource<String> kafkaDS = env.addSource(MyKafkaUtils.getKafkaConsumer(sourceTopic, groupId));
//TODO 3.将每行数据转换为JSON对象
SingleOutputStreamOperator<JSONObject> jsonObjDS = kafkaDS.map(JSON::parseObject);核心的过滤代码实现
- 首先用 keyby 按照 mid 进行分组,每组表示当前设备的访问情况
- 分组后使用 keystate 状态,记录用户进入时间,实现 RichFilterFunction 完成过滤
- 重写 open 方法用来初始化状态
- 重写 filter 方法进行过滤
- 可以直接筛掉 last_page_id 不为空的字段,因为只要有上一页,说明这条不是这个用户进入的首个页面。
- 状态用来记录用户的进入时间,只要这个 lastVisitDate 是今天,就说明用户今天已经访问过了所以筛除掉。如果为空或者不是今天,说明今天还没访问过,则保留。
- 因为状态值主要用于筛选是否今天来过,所以这个记录过了今天基本上没有用了,这里 enableTimeToLive 设定了 1 天的过期时间,避免状态过大。
//TODO 4.过滤数据 状态编程 只保留每个mid每天第一次登陆的数据
// 首先进行过滤分组,这里过滤掉的是mid为null的数据,也就是不合法的数据
KeyedStream<JSONObject, String> keyedStream = jsonObjDS.keyBy(jsonObj -> jsonObj.getJSONObject("common").getString("mid"));
// 因为这里需要用到状态编程,所以使用富函数,普通的Filter不可以使用状态
/**
* 在这里我们选用什么状态呢》valueState即可,因为我们存储的是一个时间
*/
SingleOutputStreamOperator<JSONObject> uvDS = keyedStream.filter(new RichFilterFunction<JSONObject>() {
// 时间存储围殴String了欸行
private ValueState<String> dateState;
// 因为数据里面只有时间戳,所以我们需要进行转换
private SimpleDateFormat simpleDateFormat;
/**
* 初始化
* @param parameters
* @throws Exception
*/
@Override
public void open(Configuration parameters) throws Exception {
ValueStateDescriptor<String> valueStateDescriptor = new ValueStateDescriptor<>("date-state", String.class);
/**
* Flink中的状态可以设置一个超时时间
*/
//设置状态的超时时间以及更新时间的方式
StateTtlConfig stateTtlConfig = new StateTtlConfig
.Builder(Time.hours(24))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.build();
// 设置状态过时时间
valueStateDescriptor.enableTimeToLive(stateTtlConfig);
// 访问时间状态
dateState = getRuntimeContext().getState(valueStateDescriptor);
simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd");
}
@Override
public boolean filter(JSONObject value) throws Exception {
//取出上一条页面信息
String lastPageId = value.getJSONObject("page").getString("last_page_id");
//判断上一条页面是否为Null
if (lastPageId == null || lastPageId.length() <= 0) {
//取出状态数据
String lastDate = dateState.value();
//取出今天的日期,也就是数据中的ts字段
String curDate = simpleDateFormat.format(value.getLong("ts"));
//判断两个日期是否相同
if (!curDate.equals(lastDate)) {
// 如果不相同,那么就保留当前数据,更新状态
// 注意,这里的状态更新,是一条数据对应一个状态,在这之前已经按照Mid进行分组了
dateState.update(curDate);
return true;
}
// else {
// return false;
// }
}
// 上一条不是null,直接返回false,过滤掉即可
return false;
}
});将过滤处理后的 UV写入到 Kafka的 dwm_unique_visit
//TODO 5.将数据写入Kafka
uvDS.print();
uvDS.map(JSONAware::toJSONString)//将json转换为String类型
.addSink(MyKafkaUtils.getKafkaProducer(sinkTopic));DWM 层跳出明细计算
需求分析与思路
什么是跳出
跳出就是用户成功访问了网站的一个页面后就退出,不在继续访问网站的其它页面。而跳出率就是用跳出次数除以访问次数。
使用会话窗口的方案解决,在没有会话id的时候,如何确定这个数据是同一次会话中访问的呢? 什么时候使用会话窗口,会话窗口之间的间隔时间我们自己可以确定,在我我们需要使用会话id去计算某一些指标的时候,但是这个时候没有会话id,那么我们就可以使用会话窗口解决。如果两次会话之间相隔时间较长,那么就认为是一次新的会话。
会话窗口会产生的问题
但是会话窗口可能导致丢失数据,比如数据A和数据B之间的间隔不足10秒,并且不是同一条数据,那么针对开的10秒会话窗口,两条数据分到一个窗口中,会发生丢失(因为我们是根据两条数据之间的时间间隔;来判断他们是否属于同一个窗口,现在两条数据属于统一个窗口,我们认为他没有跳出,但是实际上他是跳出的),针对这种情况,我们使用CEP。
关注跳出率,可以看出引流过来的访客是否能很快的被吸引,渠道引流过来的用户之间的质量对比,对于应用优化前后跳出率的对比也能看出优化改进的成果。
计算跳出行为的思路
首先要识别哪些是跳出行为,要把这些跳出的访客最后一个访问的页面识别出来。那么要抓住几个特征:
该页面是用户近期访问的第一个页面,这个可以通过该页面是否有上一个页面(last_page_id)来判断,如果这个表示为空,就说明这是这个访客这次访问的第一个页面。
首次访问之后很长一段时间(自己设定),用户没继续再有其他页面的访问。,如果有会话id的话,我们可以使用会话id方便的解决。
这第一个特征的识别很简单,保留 last_page_id 为空的就可以了。但是第二个访问的判断,其实有点麻烦,首先这不是用一条数据就能得出结论的,需要组合判断,要用一条存在的数据和不存在的数据进行组合判断。而且要通过一个不存在的数据求得一条存在的数据。更麻烦的他并不是永远不存在,而是在一定时间范围内不存在。那么如何识别有一定失效的组合行为呢?
最简单的办法就是 Flink 自带的 CEP 技术。这个 CEP 非常适合通过多条数据组合来识别某个事件。
用户跳出事件,本质上就是一个条件事件加一个超时事件的组合。
如果有会话id,那么就取出会话id,并且这条会话数据只有一条就可以了,但是没有会话id怎么办?
可以使用会话窗口,当没有会话id的时候,如何确定某一条数据是同一次会话中访问的呢?
会话窗口应用场景就是我们想根据会话id计算某一些指标的时候,但是没有会话id,我们就可以使用会话窗口代替。根据时间,如果两次会话时间间隔太长,那么就认为是两次会话。我们可以规定一个间隔时间。最后对会话窗口计算的时候,我们可以使用全量窗口进行计算,就是使用apply()函数,如果是一次访问,那么会话窗口中就只有一条数据。
但是这种思路会丢失数据,比如会话窗口间隔10秒,当两条数据a和b都是一次单跳,进入页面然后出去,那么当两条数据进入同一个窗口的时候 ,数据不止一条,就不认为是单跳。
使用cep,进来一条数据,只要判断其上一条是空,下一跳是还是null,说明这个数据就是我们需要的。但是这里也要定义一个超时时间,比如当前事件吓一跳事件迟迟不来怎么版,所以我们需要定义超时事件,将超时事件放到测输出流。
CEP编程三步骤
- 定义模式序列
- 将模式序列应用到流上
- 提取匹配上的超时事件
cep可以处理乱序数据
代码实现
从 kafka 的 dwd_page_log 主题中读取页面日志
//TODO 2.读取Kafka主题的数据创建流
String sourceTopic = "dwd_page_log";
String groupId = "userJumpDetailApp";
String sinkTopic = "dwm_user_jump_detail";
DataStreamSource<String> kafkaDS = env.addSource(MyKafkaUtils.getKafkaConsumer(sourceTopic, groupId));
//TODO 3.将每行数据转换为JSON对象并提取时间戳生成Watermark
SingleOutputStreamOperator<JSONObject> jsonObjDS = kafkaDS.map(JSON::parseObject)
.assignTimestampsAndWatermarks(WatermarkStrategy
// 设置乱序时间
.<JSONObject>forBoundedOutOfOrderness(Duration.ofSeconds(1))
.withTimestampAssigner(new SerializableTimestampAssigner<JSONObject>() {
// 提取事件时间
@Override
public long extractTimestamp(JSONObject element, long recordTimestamp) {
return element.getLong("ts");
}
}));通过 Flink 的 CEP 完成跳出判断
- 确认添加了 CEP 的依赖包
- 设定时间语义为事件时间并指定数据中的 ts 字段为事件时间
由于这里涉及到时间的判断,所以必须设定数据流的 EventTime 和水位线。这里没有设置延迟时间,实际生产情况可以视乱序情况增加一些延迟。
增加延迟把 forMonotonousTimestamps 换为 forBoundedOutOfOrderness 即可。
注意:flink1.12 默认的时间语义就是事件时间,所以不需要执行
env.setStreamTimeCharacteristic(TimeCharacteristic. EventTime)
根据日志数据的 mid 进行分组
因为用户的行为都是要基于相同的 Mid 的行为进行判断,所以要根据 Mid 进行分组。
//TODO 5.将模式序列作用到流上
PatternStream<JSONObject> patternStream = CEP
.pattern(jsonObjDS.keyBy(json -> json.getJSONObject("common").getString("mid"))//需要针对同一个mid左同一件事,所以使用keyby
, pattern);配置 CEP 表达式
//TODO 4.定义模式序列
Pattern<JSONObject, JSONObject> pattern = Pattern.<JSONObject>begin("start").where(new SimpleCondition<JSONObject>() {
@Override
public boolean filter(JSONObject value) throws Exception {
String lastPageId = value.getJSONObject("page").getString("last_page_id");
// 我们需要保留lastPageId为null的数据,也就是第一次访问页面的用户
return lastPageId == null || lastPageId.length() <= 0;
}
}).next("next").where(new SimpleCondition<JSONObject>() {
@Override
public boolean filter(JSONObject value) throws Exception {
String lastPageId = value.getJSONObject("page").getString("last_page_id");
return lastPageId == null || lastPageId.length() <= 0;
}
// 设置会话窗口时间间隔
}).within(Time.seconds(10));
//使用循环模式 定义模式序列
Pattern.<JSONObject>begin("start").where(new SimpleCondition<JSONObject>() {
@Override
public boolean filter(JSONObject value) throws Exception {
String lastPageId = value.getJSONObject("page").getString("last_page_id");
return lastPageId == null || lastPageId.length() <= 0;
}
})
.times(2)
.consecutive() //指定严格近邻(next)
.within(Time.seconds(10));根据表达式筛选流
//TODO 5.将模式序列作用到流上
PatternStream<JSONObject> patternStream = CEP
.pattern(jsonObjDS.keyBy(json -> json.getJSONObject("common").getString("mid"))//需要针对同一个mid左同一件事,所以使用keyby
, pattern);提取命中的数据
- 设定超时时间标识 timeoutTag。
- flatSelect 方法中,实现 PatternFlatTimeoutFunction 中的 timeout 方法。
- 所有 out.collect 的数据都被打上了超时标记。
- 本身的 flatSelect 方法提取匹配上的数据。
- 通过 SideOutput 侧输出流输出超时数据
//TODO 6.提取匹配上的和超时事件
OutputTag<JSONObject> timeOutTag = new OutputTag<JSONObject>("timeOut") {
};
SingleOutputStreamOperator<JSONObject> selectDS = patternStream.select(timeOutTag,
new PatternTimeoutFunction<JSONObject, JSONObject>() {
@Override
public JSONObject timeout(Map<String, List<JSONObject>> map, long ts) throws Exception {
return map.get("start").get(0);
}
}, new PatternSelectFunction<JSONObject, JSONObject>() {
@Override
public JSONObject select(Map<String, List<JSONObject>> map) throws Exception {
return map.get("start").get(0);
}
});将跳出数据写回到 kafka 的 DWM 层
提取超时时间的数据,超时时间的数据放在测输出流中
DataStream<JSONObject> timeOutDS = selectDS.getSideOutput(timeOutTag);
//TODO 7.UNION两种事件
DataStream<JSONObject> unionDS = selectDS.union(timeOutDS);
//TODO 8.将数据写入Kafka
unionDS.print();
unionDS.map(JSONAware::toJSONString)
.addSink(MyKafkaUtils.getKafkaProducer(sinkTopic));Flink join
Flink一共又4中join。

Interval不需要开窗就可以join。
带开窗函数的join操作
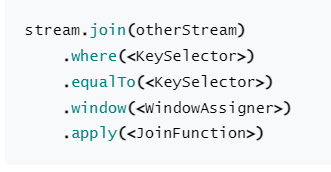
- join:连接的其他数据流
- whrere:第一个数据流的键
- equalTo:第二个数据流的key.
- window:开窗
- apply:join函数,也就是连接函数。
带窗口的join操作
Tumbling Window Join
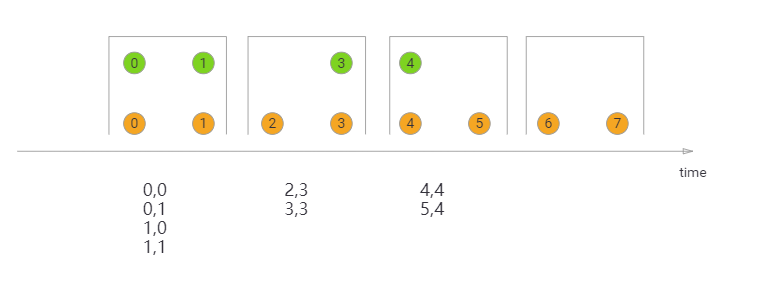
如果Flink使用的是滚动窗口,那么就和spark streaming是一样的。先收集完窗口中的数据,然后做统一计算。也就是说赞一个批次,处理完后向下传输。可以说也是一种微批次处理。
这种方式下没有重复的数据,因为窗口不会发生重叠。
DataStream<Integer> orangeStream = ...
DataStream<Integer> greenStream = ...
orangeStream.join(greenStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(TumblingEventTimeWindows.of(Time.milliseconds(2)))
.apply (new JoinFunction<Integer, Integer, String> (){
@Override
public String join(Integer first, Integer second) {
return first + "," + second;
}
});Sliding Window Join
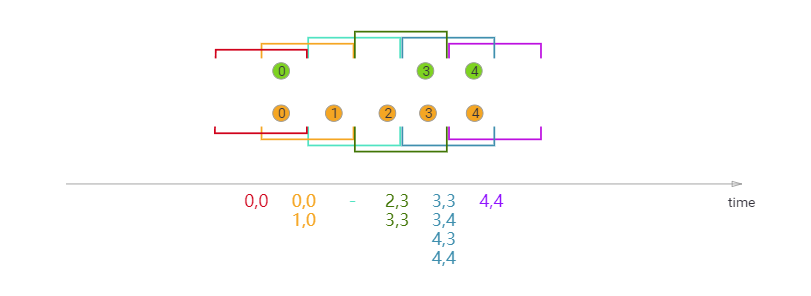
在滑动窗口中,可能会输出重复数据,因为窗口又重叠的部分,所以有一部分数据在多个窗口中进行关联输出。,比如图中的0,0,他们属于两个窗口,所以在每一个窗口中都会输出一次。
DataStream<Integer> orangeStream = ...
DataStream<Integer> greenStream = ...
orangeStream.join(greenStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(SlidingEventTimeWindows.of(Time.milliseconds(2) /* size */, Time.milliseconds(1) /* slide */))
.apply (new JoinFunction<Integer, Integer, String> (){
@Override
public String join(Integer first, Integer second) {
return first + "," + second;
}
});Session Window Join
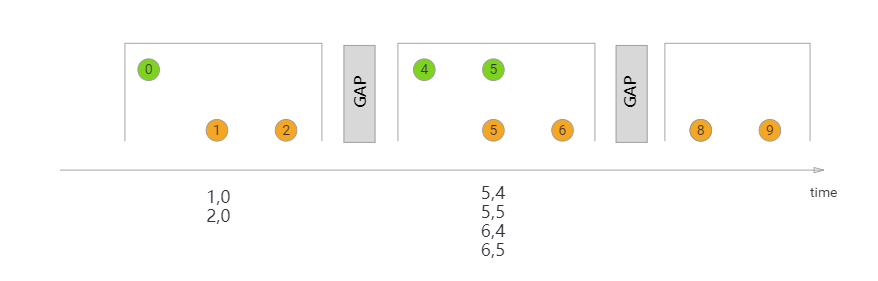
滚动窗口和滑动窗口的时间都是对齐的,对于会话窗口,时间是不对其的,也就是要求两个流相隔gap时间都没有数据流来才可以,两个流都同时满足超时时间才可以,中间之后某一个流满足时间间隔是不可以的。而滚动和滑动窗口的两个流都是同时开始,同时结束。
DataStream<Integer> orangeStream = ...
DataStream<Integer> greenStream = ...
orangeStream.join(greenStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(EventTimeSessionWindows.withGap(Time.milliseconds(1)))
.apply (new JoinFunction<Integer, Integer, String> (){
@Override
public String join(Integer first, Integer second) {
return first + "," + second;
}
});Interval Join
不需要开窗
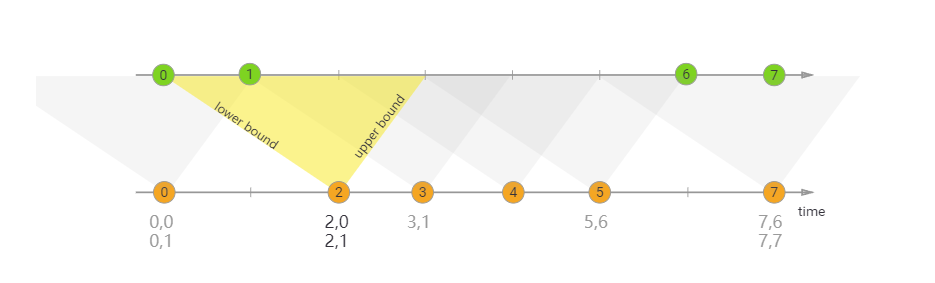
在一条流中的某一个时间点去join另外一条流中的某一个时间区间,如果有满足join条件的数据,全部输出。
比如上图中所示,橙色数据流在2位置开始join,此时绿色数据流相对橙色2位置左侧的数据保存在状态中,但是绿色数据流相对橙色数据流2右侧数据还没有到,那么此时会把橙色数据流2进行状态保存,等到绿色数据流右侧数据全部到齐,做join操作。
关联另一条数据流中一个范围内的数据时候,有一个时间上下界,为什么可以关联到某个时间点之前的数据呢,也就是时间下界的数据?
这是因为使用了状态编程,会把某个时间点之前到时间下界之间的数据写入状态中,
那为什么可以join某一个时间点到时间上界之间的数据呢?
也是状态编程,会把某一个时间点到时间上界之间的数据保存一段时间,然后join操作。
在Flink中有状态,所以可以保存历史数据,也就是状态,但是在spark streamming中没有状态,所以写入的是redis数据库保存,然后在关联。
The interval join currently only supports event time.
DataStream<Integer> orangeStream = ...
DataStream<Integer> greenStream = ...
orangeStream
.keyBy(<KeySelector>)
.intervalJoin(greenStream.keyBy(<KeySelector>))
.between(Time.milliseconds(-2), Time.milliseconds(1))
.process (new ProcessJoinFunction<Integer, Integer, String(){
@Override
public void processElement(Integer left, Integer right, Context ctx, Collector<String> out) {
out.collect(first + "," + second);
}
});- keyBy:指出橙色主流按照哪一个字段进行join。
- intervalJoin:绿色流按照哪一个字段join。
- between:join的时间上下界。
- process:处理方法
DWM 层-订单宽表
需求分析与思路
订单是统计分析的重要的对象,围绕订单有很多的维度统计需求,比如用户、地区、商品、品类、品牌等等。
为了之后统计计算更加方便,减少大表之间的关联,所以在实时计算过程中将围绕订单的相关数据整合成为一张订单的宽表。也就是围绕一个主题形成一个大的宽表。
那究竟哪些数据需要和订单整合在一起?
简单来说,只要和我们的订单有关的信息都可以整合在一起形成宽表。
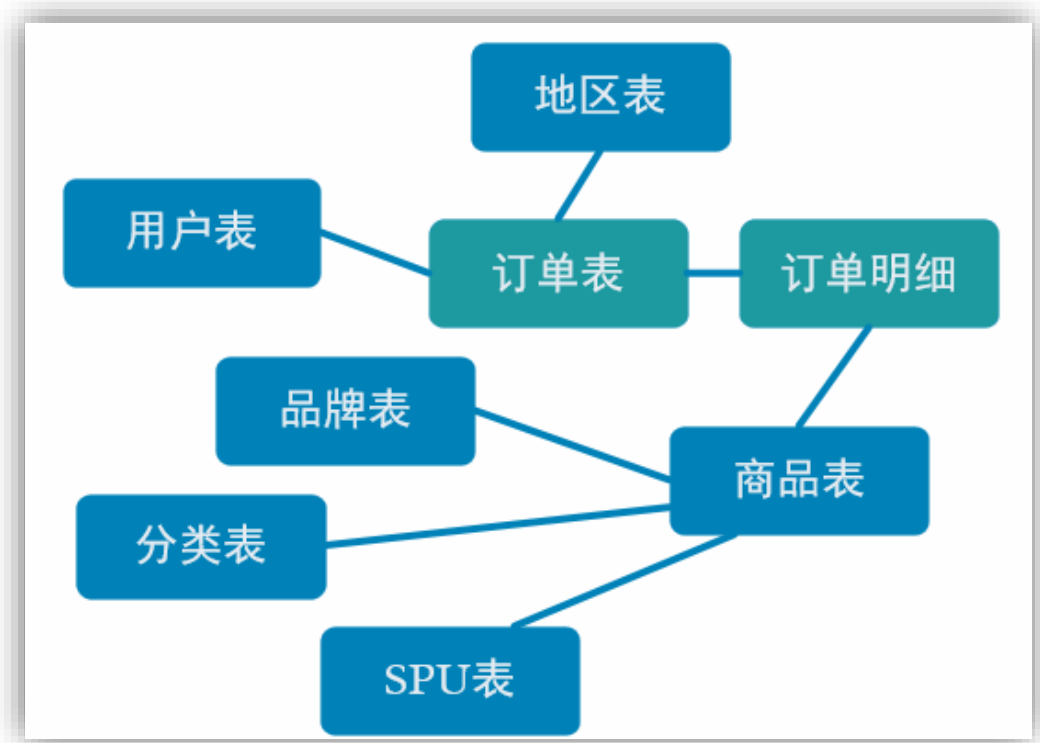
订单表是一个全部的订单信息,里面存储的是用户订单信息,在下单的时候,一个用户可以一次下好多订单,所以订单表 中的一个用户可能对应订单明细表中的多条记录,这两张表之间是一对多的关系。只有订单表我们无法去关联sku(商品表的),因为订单表里面并没有sku_id。所以首先需要把订单表和订单明细表关联。
这里我们使用双流join,使用connect非常的麻烦,并且connect每一次只能关联两个数据流,需要我们自己去维护状态。
关联两张实时表之后,我们需要去hbase中查找所有维度表,然后和事实表进行关联,有多少个维度表,就要关联多少个维度表。
如上图,由于在之前的操作我们已经把数据分拆成了事实数据和维度数据,事实数据(绿色)进入 kafka 数据流(DWD 层)中,维度数据(蓝色)进入 hbase 中长期保存。那么我们在 DWM 层中要把实时和维度数据进行整合关联在一起,形成宽表。那么这里就要处理有两种关联,事实数据和事实数据关联、事实数据和维度数据关联。
事实数据和事实数据关联,其实就是流与流之间的关联。因为实时表数据都是存储在kafka中的,所以我们只要从kafka数据流中读取数据,然后关联两条数据流即可。
事实数据与维度数据关联,其实就是流计算中查询外部数据源。我们事实表数据存储在kafka中,而维度表数据存储在hbase中,所以我们需要根据事实表中的数据id去查询hbase中的相同id进行关联。
订单和订单明细关联代码实现
也就是两个事实表之间的关联,准确说是两条数据流的关联。
从 Kafka 的 dwd 层接收订单和订单明细数据
创建订单实体类
// 数据字段来自mysql中的表
@Data
public class OrderInfo {
Long id;
Long province_id;
String order_status;
Long user_id;
BigDecimal total_amount;
BigDecimal activity_reduce_amount;
BigDecimal coupon_reduce_amount;
BigDecimal original_total_amount;
BigDecimal feight_fee;
String expire_time;
String create_time; //yyyy-MM-dd HH:mm:ss
String operate_time;
// 上面的字段来自mysql表
// 下main是扩展字段
String create_date; // 把其他字段处理得到
String create_hour;
// 时间戳
Long create_ts;
}创建订单明细实体类
@Data
public class OrderDetail {
Long id;
Long order_id;//订单ip,和订单表中的id进行关联
Long sku_id;
BigDecimal order_price;
Long sku_num;
String sku_name;
String create_time;
BigDecimal split_total_amount;
BigDecimal split_activity_amount;
BigDecimal split_coupon_amount;
// 时间戳
Long create_ts;
}创建 OrderWideApp 读取订单和订单明细数据,是用Kafka数据流中读取数据
因为我们创建的订单表bean对象和明细表bean对象中有扩展字段,也就是时间字段,所以在读取数据流的时候,我们需要根据事件事件去填充bean对象中的时间属性。
//TODO 2.读取Kafka 主题的数据 并转换为JavaBean对象&提取时间戳生成WaterMark
// 订单表
String orderInfoSourceTopic = "dwd_order_info";
// 订单明细表
String orderDetailSourceTopic = "dwd_order_detail";
// 订单宽表
String orderWideSinkTopic = "dwm_order_wide";
String groupId = "order_wide_group";
// 处理订单表数据流
SingleOutputStreamOperator<OrderInfo> orderInfoDS = env.addSource(MyKafkaUtils.getKafkaConsumer(orderInfoSourceTopic, groupId))
.map(line -> {
// 把json字符串转换为java对象
OrderInfo orderInfo = JSON.parseObject(line, OrderInfo.class);
// 提取创建时间:y-m-d h-m s格式
String create_time = orderInfo.getCreate_time();
String[] dateTimeArr = create_time.split(" ");
// 补充创建时间
orderInfo.setCreate_date(dateTimeArr[0]);
// 补充时间
orderInfo.setCreate_hour(dateTimeArr[1].split(":")[0]);
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
// 设置时间戳
orderInfo.setCreate_ts(sdf.parse(create_time).getTime());
return orderInfo;
}).assignTimestampsAndWatermarks(WatermarkStrategy.<OrderInfo>forMonotonousTimestamps()
// 提取时间戳
.withTimestampAssigner(new SerializableTimestampAssigner<OrderInfo>() {
@Override
public long extractTimestamp(OrderInfo element, long recordTimestamp) {
return element.getCreate_ts();
}
}));
// 处理订单详情表数据流
SingleOutputStreamOperator<OrderDetail> orderDetailDS = env.addSource(MyKafkaUtils.getKafkaConsumer(orderDetailSourceTopic, groupId))
.map(line -> {
OrderDetail orderDetail = JSON.parseObject(line, OrderDetail.class);
String create_time = orderDetail.getCreate_time();
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
orderDetail.setCreate_ts(sdf.parse(create_time).getTime());
return orderDetail;
}).assignTimestampsAndWatermarks(WatermarkStrategy.<OrderDetail>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<OrderDetail>() {
@Override
public long extractTimestamp(OrderDetail element, long recordTimestamp) {
return element.getCreate_ts();
}
}));注意:会根据配置分流 dwd 层,dwd 层还是保留的原始数据,所有我们这里 sink_columns 的内容和数据库表中的字段保持一致,可以使用文本编辑工具处理。
业务数据生成->FlinkCDCApp->Kafka 的 ods_base_db 主题->BaseDBApp 分流写回 kafka->dwd_order_info dwd_order_detail->OrderWideApp 从 kafka 的 dwd 层读数据,打印输出
订单和订单明细关联(双流 join)
在 flink 中的流 join 大体分为两种,一种是基于时间窗口的 join(Time Windowed Join),比如 join、coGroup 等。另一种是基于状态缓存的 join(Temporal Table Join),比如 intervalJoin。
这里选用 intervalJoin,因为相比较窗口 join,intervalJoin 使用更简单,而且避免了应用匹配的数据处于不同窗口的问题。intervalJoin 目前只有一个问题,就是还不支持 left join。
但是我们这里是订单主表与订单从表之间的关联不需要 left join,所以 intervalJoin 是较好的选择。
创建合并后的宽表实体类
这两个表合并之后,需要我们对两个表中的字段做一些去重处理。这个需要根据具体的业务进行考虑,保存那些字段和丢弃那些字段。
//订单表+订单明细表+所需的维度表(字段去重之后)
import lombok.AllArgsConstructor;
import lombok.Data;
import org.apache.commons.lang3.ObjectUtils;
import java.math.BigDecimal;
/**
* 通常情况下,订单表,订单明细表所有维度表中的字段都要,但是会重复字段,比如订单表中的id和订单明细表中的订单id是一个意思,所以需要去重操作
*/
@Data
@AllArgsConstructor
public class OrderWide {
//各个表的id
Long detail_id;
Long order_id;
Long sku_id;
BigDecimal order_price;
Long sku_num;
String sku_name;
Long province_id;
String order_status;
Long user_id;
// 订单和订单明细表中去重后的字段
BigDecimal total_amount;
BigDecimal activity_reduce_amount;
BigDecimal coupon_reduce_amount;
BigDecimal original_total_amount;
BigDecimal feight_fee;
BigDecimal split_feight_fee;
BigDecimal split_activity_amount;
BigDecimal split_coupon_amount;
BigDecimal split_total_amount;
String expire_time;
String create_time; //yyyy-MM-dd HH:mm:ss
String operate_time;
String create_date; // 把其他字段处理得到
String create_hour;
// 上面部分全部是订单和订单明细表去重后的字段
// 地区表字段维度表
String province_name;//查询维表得到
String province_area_code;
String province_iso_code;
String province_3166_2_code;
// 用户维度表字段
Integer user_age;
String user_gender;
// 商品表字段
Long spu_id; //作为维度数据 要关联进来
Long tm_id;
Long category3_id;
String spu_name;
String tm_name;
String category3_name;
public OrderWide(OrderInfo orderInfo, OrderDetail orderDetail) {
mergeOrderInfo(orderInfo);
mergeOrderDetail(orderDetail);
}
public void mergeOrderInfo(OrderInfo orderInfo) {
if (orderInfo != null) {
this.order_id = orderInfo.id;
this.order_status = orderInfo.order_status;
this.create_time = orderInfo.create_time;
this.create_date = orderInfo.create_date;
this.create_hour = orderInfo.create_hour;
this.activity_reduce_amount = orderInfo.activity_reduce_amount;
this.coupon_reduce_amount = orderInfo.coupon_reduce_amount;
this.original_total_amount = orderInfo.original_total_amount;
this.feight_fee = orderInfo.feight_fee;
this.total_amount = orderInfo.total_amount;
this.province_id = orderInfo.province_id;
this.user_id = orderInfo.user_id;
}
}
public void mergeOrderDetail(OrderDetail orderDetail) {
if (orderDetail != null) {
this.detail_id = orderDetail.id;
this.sku_id = orderDetail.sku_id;
this.sku_name = orderDetail.sku_name;
this.order_price = orderDetail.order_price;
this.sku_num = orderDetail.sku_num;
this.split_activity_amount = orderDetail.split_activity_amount;
this.split_coupon_amount = orderDetail.split_coupon_amount;
this.split_total_amount = orderDetail.split_total_amount;
}
}
public void mergeOtherOrderWide(OrderWide otherOrderWide) {
this.order_status = ObjectUtils.firstNonNull(this.order_status, otherOrderWide.order_status);
this.create_time = ObjectUtils.firstNonNull(this.create_time, otherOrderWide.create_time);
this.create_date = ObjectUtils.firstNonNull(this.create_date, otherOrderWide.create_date);
this.coupon_reduce_amount = ObjectUtils.firstNonNull(this.coupon_reduce_amount, otherOrderWide.coupon_reduce_amount);
this.activity_reduce_amount = ObjectUtils.firstNonNull(this.activity_reduce_amount, otherOrderWide.activity_reduce_amount);
this.original_total_amount = ObjectUtils.firstNonNull(this.original_total_amount, otherOrderWide.original_total_amount);
this.feight_fee = ObjectUtils.firstNonNull(this.feight_fee, otherOrderWide.feight_fee);
this.total_amount = ObjectUtils.firstNonNull(this.total_amount, otherOrderWide.total_amount);
this.user_id = ObjectUtils.<Long>firstNonNull(this.user_id, otherOrderWide.user_id);
this.sku_id = ObjectUtils.firstNonNull(this.sku_id, otherOrderWide.sku_id);
this.sku_name = ObjectUtils.firstNonNull(this.sku_name, otherOrderWide.sku_name);
this.order_price = ObjectUtils.firstNonNull(this.order_price, otherOrderWide.order_price);
this.sku_num = ObjectUtils.firstNonNull(this.sku_num, otherOrderWide.sku_num);
this.split_activity_amount = ObjectUtils.firstNonNull(this.split_activity_amount);
this.split_coupon_amount = ObjectUtils.firstNonNull(this.split_coupon_amount);
this.split_total_amount = ObjectUtils.firstNonNull(this.split_total_amount);
}
}订单和订单明细关联 intervalJoin
这里设置了正负 5 秒,以防止在业务系统中主表与从表保存的时间差
//TODO 3.双流JOIN,这里关联的是订单事实表和订单明细事实表,还没有关联维度表
SingleOutputStreamOperator<OrderWide> orderWideWithNoDimDS = orderInfoDS.keyBy(OrderInfo::getId)
.intervalJoin(orderDetailDS.keyBy(OrderDetail::getOrder_id))
.between(Time.seconds(-5), Time.seconds(5)) //生成环境中给的时间给最大延迟时间,这样可以防止丢失数据
.process(new ProcessJoinFunction<OrderInfo, OrderDetail, OrderWide>() {
@Override
public void processElement(OrderInfo orderInfo, OrderDetail orderDetail, Context ctx, Collector<OrderWide> out) throws Exception {
out.collect(new OrderWide(orderInfo, orderDetail));
}
});订单表和订单详情表在关联的时候是1:n的关系,因为订单表里面存储的是某一个用户订单的信息,而某一个用户可能有多个订单,那这多个订单信息存储在订单详情表中,所以这两个事实表在关联的时候是一对多的关系。
关联维度表信息
维度表的信息存储在Hbase中,我们需要根据kafka数据流中的每一条数据的id去hbase中查询一条数据然后在关联,所以不能使用connect,join操作,所以使用map操作。
因为kafka中的数据传输速率很高,延迟非常的低,但是我们去hbase中查询数据的时候,数据的延迟很高,因为hbase底层是存储在hdfs上面,所以这里存在一个速率不匹配问题,所以下面我们还需要做一些优化,尽量让hbase中的数据查询速度尽可能的快。
维表关联代码实现
维度关联实际上就是在流中查询存储在 HBase 中的数据表。但是即使通过主键的方式查询,HBase 速度的查询也是不及流之间的 join。外部数据源的查询常常是流式计算的性能瓶颈,所以咱们再这个基础上还有进行一定的优化。
因为如果是单并行度,hbase每一秒如果不从缓存中查询的话,耗费时间大概13毫秒,也就是说一秒中大概查询80次,显然很慢,如果仅仅提高并行度,而不提高单并行度每秒处理的数据,也是不行的,所以我们首先提高单并行度每一秒处理的数据量。
先实现基本的维度查询功能
这是一个通用的查询功能,可以去mysql或者hbase中执行查询,然后返回多条查询的结果。
public class JdbcUtil {
/**
* 封装为一个通用类,可以查mysql,hbase,并且还可以查询多行数据
* 使用List泛型,可以查询多条数据
* select * from t1;
* xx,xx,xx
* xx,xx,xx
*/
/**
*
* @param connection 查询mysql或者hbase需要不同的连接
* @param querySql 查询语句
* @param clz T泛型的类型
* @param underScoreToCamel 在mysql中通常使用_的命名方式,但是java bean中通常使用驼峰命名法,这个字段表示要不要把_命名方式转换为驼峰命名法
* @param <T>
* @return
* @throws Exception
*/
public static <T> List<T> queryList(Connection connection, String querySql, Class<T> clz, boolean underScoreToCamel) throws Exception {
//创建集合用于存放查询结果数据
ArrayList<T> resultList = new ArrayList<>();
//预编译SQL
PreparedStatement preparedStatement = connection.prepareStatement(querySql);
//执行查询
ResultSet resultSet = preparedStatement.executeQuery();
//解析resultSet
// 元信息,也就是列属性信息
ResultSetMetaData metaData = resultSet.getMetaData();
// 获取列的个数
int columnCount = metaData.getColumnCount();
while (resultSet.next()) {
//创建泛型对,根据类型创建泛型对象
T t = clz.newInstance();
//给泛型对象赋值,值是从1开始遍历
for (int i = 1; i < columnCount + 1; i++) {
//获取列名
String columnName = metaData.getColumnName(i);
//判断是否需要转换为驼峰命名
if (underScoreToCamel) {
columnName = CaseFormat.LOWER_UNDERSCORE //转换为小驼峰
.to(CaseFormat.LOWER_CAMEL, columnName.toLowerCase());
}
//获取列值
Object value = resultSet.getObject(i);
//给泛型对象赋值
//BeanUtils.copyProperty(t, columnName, value); JSONObject => {}
// 给对象设置属性
BeanUtils.setProperty(t, columnName, value);
}
//将该对象添加至集合
resultList.add(t);
}
preparedStatement.close();
resultSet.close();
//返回结果集合
return resultList;
}
public static void main(String[] args) throws Exception {
// System.out.println(CaseFormat.LOWER_UNDERSCORE.to(CaseFormat.LOWER_CAMEL, "aa_bb"));
Class.forName(GmallConfig.PHOENIX_DRIVER);
Connection connection = DriverManager.getConnection(GmallConfig.PHOENIX_SERVER);
List<JSONObject> queryList = queryList(connection,
"select * from GMALL210325_REALTIME.DIM_USER_INFO",
JSONObject.class,
true);
for (JSONObject jsonObject : queryList) {
System.out.println(jsonObject);
}
connection.close();
}
}封装查询维度的工具类 DimUtil(直接查询 Phoenix)
在这一步需要做大量的优化操作。
优化 1:加入旁路缓存模式 (cache-aside-pattern)
我们在上面实现的功能中,直接查询的 HBase,hbase中的数据是存储在hdfs上。外部数据源的查询常常是流式计算的性能瓶颈,所以我们需要在上面实现的基础上进行一定的优化。我们这里使用旁路缓存。
旁路缓存模式是一种非常常见的按需分配缓存的模式。如下图,任何请求优先访问缓存,缓存命中,直接获得数据返回请求。如果未命中则,查询数据库,同时把结果写入缓存以备后续请求使用。
缓存我们使用的是Rides,是基于内存的,速度肯定比基于hdfs的Hbase快很多。
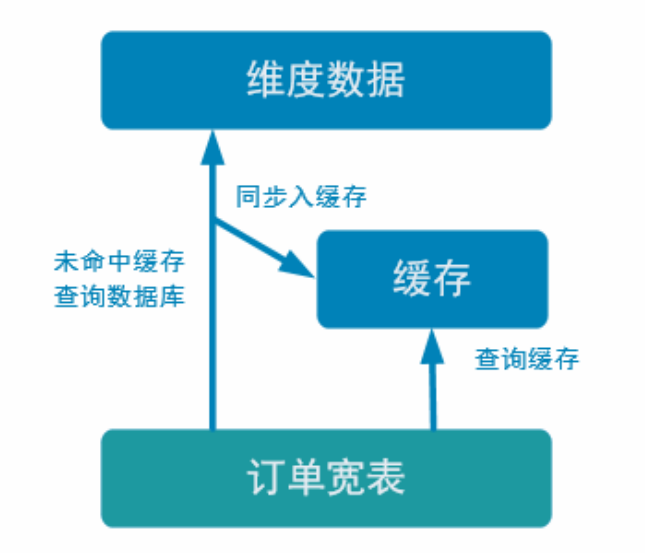
这种缓存策略有几个注意点
- 缓存要设过期时间,不然冷数据会常驻缓存浪费资源。因为有的用户访问一次后就不再访问了,所以如果把这种数据缓存起来,房费空间。所以添加一个过期时间。相当于把热点数据存储在Rides.
- 要考虑维度数据是否会发生变化,如果发生变化要主动清除缓存。为了保证hbase和Rides中的数据保证一致性。
缓存的选型
堆缓存的缺点:
- 如果任务挂掉,那么缓存的数据会全部丢失。
- 存在数据冗余,线程安全问题。
独立缓存的优点:
- 性能好,很容易扩展
- 稳定性高,简单,不用考虑线程安全问题
一般两种:堆缓存或者独立缓存服务(redis,memcache)。
堆缓存,从性能角度看更好,毕竟访问数据路径更短,减少过程消耗。但是管理性差,其他进程无法维护缓存中的数据。相当于我们在堆内存中加入一个Map,key作为键,值就是一行数据,如果任务挂掉,缓存数据全部失效。
另外,堆缓存可能存在大量的数据冗余,因为堆缓存中,其他进程无法维护堆缓存中数据,所以其他的进程中也需要保存一份堆缓存中的数据,比如有多条业务线,订单中有用户信息,支付中有用户信息,用Rides中只存在一份数据即可,但是用堆缓存服务,每一个进程中都需要存储用户信息。
但是也可以使用堆缓存和Rides结合的方式,这就相当于多级缓存模式,最热点的数据存储在堆缓存,堆缓存没有的数据去Rides中查询。堆缓存往往是LRU缓存。
独立缓存服务(redis,memcache)本事性能也不错,不过会有创建连接、网络 IO 等消耗。但是考虑到数据如果会发生变化,那还是独立缓存服务管理性更强,而且如果数据量特别大,独立缓存更容易扩展。
因为咱们的维度数据都是可变数据,所以这里还是采用 Redis 管理缓存。
所以对于本项目的缓存,有三件事情,读缓存,也就是查询数据的时候,先去缓存中查询,写缓存,当缓存中数据不存在,就去HBASE中查询,查询到后首先写入缓存中,然后在返回结果,最后是删除缓存,也就是数据发生不一致的时候,需要从缓存中删除数据。
- 读缓存
- 写缓存
- 删除缓存
Rides连接池的实现
public class RedisUtil {
/**
* 获取一个Rides连接池子,从池子中获取连接
*/
public static JedisPool jedisPool = null;
public static Jedis getJedis() {
if (jedisPool == null) {
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxTotal(100); //最大可用连接数
jedisPoolConfig.setBlockWhenExhausted(true); //连接耗尽是否等待
jedisPoolConfig.setMaxWaitMillis(2000); //等待时间
jedisPoolConfig.setMaxIdle(5); //最大闲置连接数
jedisPoolConfig.setMinIdle(5); //最小闲置连接数
jedisPoolConfig.setTestOnBorrow(true); //取连接的时候进行一下测试 ping pong
jedisPool = new JedisPool(jedisPoolConfig, "hadoop102", 6379, 1000);
System.out.println("开辟连接池");
return jedisPool.getResource();
} else {
// System.out.println(" 连接池:" + jedisPool.getNumActive());
return jedisPool.getResource();
}
}
}实现一个Rides连接池,可以返回一个Rides连接。
用Rides做缓存需要考虑的问题
Rides中具体存什么数据?
维度表中的数据 JsonStr,存储到Rides中的是json字符串。在Rides中查询数据是根据键值对形式查询,值肯定是我的数据字符串。
用什么类型的键? String 、Set 、Hash
如果选用String类型的键:String:tableName+id,那么主键就是表名和id,可以唯一确定一条数据吧,不同的表中可能存在相同的id,所以需要添加表明,这是一种可行的方案。
Set:tableName 使用set的话,使用的是表明为主键,如果查询一张维度表,会把维度表中所有数据全部查出来,所以不适用set方式,显然不是我们需要的结果。
Hash:tableName+id 外面的key存储表名字,内部的key存储id,value存储值,也可以查询到数据,外部的map指的是hashmap存储一个表的名字,内部是rides有自己的key,可以存储id,value存储数据,也可以定位数据。
那么具体我们选用哪一种方式呢?
为什么不选Hash方式?
- 用户维度数据量大,因为Rides是扩展集群,不是我们经常说的master-slave模式,比如我们有三条数据,1,2,3,那么分别发散到Rides集群的三台机器上,但是如果用map形式,就可能把数据全部分到一台机器上面,造成某一太机器数据量非常的大,成为热点机器,所以我们使用string作为键,将数据打散到不同的机器
- 第二个是数据有过期时间,如果使用map,那么他的键是表的名字,如果过期,那么一张表中的所有数据全部过期了,同时所有查询数据全部过期,就像雪崩了一样,全部会落到Hbase的查询,但是实际上,我们希望每一条数据都有一个各自的过期时间,显然map做不到。防止同一时间,所有数据全部过期的问题。
不选set是因为查询不方便,因为每一次查询都会查询出所有的数据。
加入Rides缓存后,我们的代码思路变为:
- 如果想要根据数据流中的id去查询某一条数据,那么先去Rides缓存中查询是否存在数据,如果数据存在,那么可以直接返回即可。
- 如果数据不存在,那么就去Hbase中查询数据,查询到数据首先写入Rides中,然后在返回。
- 如果是更新数据,那么需要判断更新的数据是否存在于Rides数据库中,如果存在,需要把Rides中的数据删除,防止数据发生不一致问题。
总的来说,Rides需要做三件事:
- 读缓存,也就是查询数据的时候,先去缓存中查询。
- 写缓存,当缓存中数据不存在,就去HBASE中查询,查询到后首先写入缓存中,然后在返回结果
- 最后是删除缓存,也就是数据发生不一致的时候,需要从缓存中删除数据。
这三部每一步做完都需要重新设置我们Rides中每一条数据的过期时间,过期后自动清除。
代码实现
public class DimUtil {
/**
* select * from t where id='19' and name='zhangsan';
* <p>
* Redis:
* 1.存什么数据? 维度数据 JsonStr,存储到Rides中的是json字符串
* 2.用什么类型? String Set Hash
* 3.RedisKey 的设计?
* String:tableName+id
* Set:tableName 使用set的话,如果查询依照维度表,会把所有数据全部查出来,所以不适用set方式
* Hash:tableName+id 外面的key存储表名字,内部的key存储id,value存储值,也可以查询到数据,外部的map指的是hashmap存储一个表的名字,内部是
* rides有自己的hashmap,可以存储id,value存储数据,也可以定位数据。
*
* 为什么不选hash()?
* 1 用户维度数据啊量大,因为Rides是扩展集群,比如我们有三条数据,1,2,3,那么分别发散到Rides集群的三台机器上,但是如果不用Hash,就可能把数据全部
* 分到一台机器上面,造成某一太机器数据量非常的大,成为热点机器,所以我们使用string作为键,将数据大三到不同的机器
* 2,第二个是数据有过期时间,如果使用map,那么他的键是表的名字,如果过期,那么一张表中的所有数据全部过期了,同时所有查询数据全部过期,就像雪崩了一样
* 全部会落到Hbase的查询,但是实际上,我们希望每一条数据都有一个各自的过期时间,显然map做不到。防止同一时间,所有数据全部过期的问题。
*
* 不选set是因为查询不方便
* t:19:zhangsan
* <p>
* 集合方式排除,原因在于我们需要对每条独立的维度数据设置过期时间
*/
public static JSONObject getDimInfo(Connection connection, String tableName, String id) throws Exception {
//查询Phoenix之前先查询Redis,如果Rides中有数据,直接返回即可
Jedis jedis = RedisUtil.getJedis();//获取一个Rides连接
//DIM:DIM_USER_INFO:143 作为key存储
String redisKey = "DIM:" + tableName + ":" + id;
// 获取key对应的值
String dimInfoJsonStr = jedis.get(redisKey);
// 判断是或否获取到数据,如果没有获取到,就去HBASE中查找
if (dimInfoJsonStr != null) {
// 不为bull,说明查询到数据
//重置过期时间,查找到,重置时间
jedis.expire(redisKey, 24 * 60 * 60);
//归还连接
jedis.close();
//返回结果
return JSONObject.parseObject(dimInfoJsonStr);
}
//拼接查询语句
//select * from db.tn where id='18';
String querySql = "select * from " + GmallConfig.HBASE_SCHEMA + "." + tableName +
" where id='" + id + "'";
//查询Phoenix,执行查询语句
List<JSONObject> queryList = JdbcUtil.queryList(connection, querySql, JSONObject.class, false);
// 因为上面已经限定了只有一条sql,所以返回的列表中只有一个值
JSONObject dimInfoJson = queryList.get(0);
//在返回结果之前,将数据写入Redis,
jedis.set(redisKey, dimInfoJson.toJSONString());
// 设置过期时间
jedis.expire(redisKey, 24 * 60 * 60);
jedis.close();
//返回结果
return dimInfoJson;
}
/**
* 删除不一致的数据
* @param tableName
* @param id
*/
public static void delRedisDimInfo(String tableName, String id) {
//获取一个Rides连接
Jedis jedis = RedisUtil.getJedis();
// 根据id获取数据
String redisKey = "DIM:" + tableName + ":" + id;
// 根据key删除数据
jedis.del(redisKey);
jedis.close();
}为了保证Hbase数据库中数据和Rides中数据一致性问题,所以我们如果是更新Hbase中的数据,我们需要删除Rides中的数据,这一部分代码在DimSinkFunction修改:
public class DimSinkFunction extends RichSinkFunction<JSONObject> {
// 声明一个链接
private Connection connection;
@Override
public void open(Configuration parameters) throws Exception {
// 获取链接
Class.forName(GmallConfig.PHOENIX_DRIVER);
connection = DriverManager.getConnection(GmallConfig.PHOENIX_SERVER);
connection.setAutoCommit(true);
}
//value:{"sinkTable":"dim_base_trademark","database":"gmall-210325-flink","before":{"tm_name":"atguigu","id":12},"after":{"tm_name":"Atguigu","id":12},"type":"update","tableName":"base_trademark"}
//SQL:upsert into db.tn(id,tm_name) values('...','...')
@Override
public void invoke(JSONObject value, Context context) throws Exception {
PreparedStatement preparedStatement = null;
try {
//获取SQL语句
String sinkTable = value.getString("sinkTable");
JSONObject after = value.getJSONObject("after");
String upsertSql = genUpsertSql(sinkTable,
after);
System.out.println(upsertSql);
//预编译SQL
preparedStatement = connection.prepareStatement(upsertSql);
//判断如果当前数据为更新操作,则先删除Redis中的数据,因为这里需要保存数据的一致性
// 在Rides中删除一个不存在的数据是不会报错的
if ("update".equals(value.getString("type"))){
DimUtil.delRedisDimInfo(sinkTable.toUpperCase(), after.getString("id"));
}
//执行插入操作
preparedStatement.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
} finally {
if (preparedStatement != null) {
preparedStatement.close();
}
}
}
//data:{"tm_name":"Atguigu","id":12}
//SQL:upsert into db.tn(id,tm_name,aa,bb) values('...','...','...','...')
private String genUpsertSql(String sinkTable, JSONObject data) {
Set<String> keySet = data.keySet();
Collection<Object> values = data.values();
//keySet.mkString(","); => "id,tm_name"
return "upsert into " + GmallConfig.HBASE_SCHEMA + "." + sinkTable + "(" +
StringUtils.join(keySet, ",") + ") values('" +
StringUtils.join(values, "','") + "')";
}
}优化 2:异步查询
再做异步IO前我们还又一种方案,就是提高并行度,但是这样需要更多的资源,比如更多task,内存,数据库连接等等。所以我们使用异步IO。
使用异步io的前提

需要有支持异步IO的客户端,但是我们的项目中,需要访问Rides和Hbase,显然提供的不能满足要求,并且做起来很麻烦,所以我们使用多线程的方式 ,模拟多个客户端进行任务的请求,使用多线程方式很通用。
如何使用异步IO

- 实现一个AsyncFunction函数,发送自己的请求。
- 使用异步方式相应相求。
- 将产生的结果写回流中产生关联。
实现RichAsyncFunction带Rich的接口好处就是有open()声明周期方法。
官方案例
// This example implements the asynchronous request and callback with Futures that have the
// interface of Java 8's futures (which is the same one followed by Flink's Future)
/**
* An implementation of the 'AsyncFunction' that sends requests and sets the callback.
*/
class AsyncDatabaseRequest extends RichAsyncFunction<String, Tuple2<String, String>> {
/** The database specific client that can issue concurrent requests with callbacks */
private transient DatabaseClient client;
@Override
public void open(Configuration parameters) throws Exception {
client = new DatabaseClient(host, post, credentials);
}
@Override
public void close() throws Exception {
client.close();
}
@Override
public void asyncInvoke(String key, final ResultFuture<Tuple2<String, String>> resultFuture) throws Exception {
// issue the asynchronous request, receive a future for result
final Future<String> result = client.query(key);
// set the callback to be executed once the request by the client is complete
// the callback simply forwards the result to the result future
CompletableFuture.supplyAsync(new Supplier<String>() {
@Override
public String get() {
try {
return result.get();
} catch (InterruptedException | ExecutionException e) {
// Normally handled explicitly.
return null;
}
}
}).thenAccept( (String dbResult) -> {
resultFuture.complete(Collections.singleton(new Tuple2<>(key, dbResult)));
});
}
}
// create the original stream
DataStream<String> stream = ...;
// apply the async I/O transformation
DataStream<Tuple2<String, String>> resultStream =
AsyncDataStream.unorderedWait(stream, new AsyncDatabaseRequest(), 1000, TimeUnit.MILLISECONDS, 100);AsyncDataStream这个方法是把异步产生的结果和流进行关联,
- unorderedWait:是说异步产生的结果是否保持原来的顺序,因为异步发送请求,有的请求可能处理慢,所以返回时间晚,那么使用这个方法的话,就是说不保证产生结果的顺序,如果对顺序没有要求,可以使用。
- Unordered:异步结果按照顺序到达。
异步编程三步
- 继承RichAsyncFunction类
- 实现asyncInvoke方法发送请求。
- 实现AsyncDataStream将产生的结果作用到流上。
为什么要异步IO
在 Flink 流处理过程中,经常需要和外部系统进行交互,用维度表补全事实表中的字段。
例如:在电商场景中,需要一个商品的 skuid 去关联商品的一些属性,例如商品所属行业、商品的生产厂家、生产厂家的一些情况;在物流场景中,知道包裹 id,需要去关联包裹的行业属性、发货信息、收货信息等等。
默认情况下,在 Flink 的 MapFunction 中,单个并行只能用同步方式去交互: 将请求发送到外部存储,IO 阻塞,等待请求返回,然后继续发送下一个请求。这种同步交互的方式往往在网络等待上就耗费了大量时间。为了提高处理效率,可以增加 MapFunction 的并行度,但增加并行度就意味着更多的资源,并不是一种非常好的解决方式。
Flink 在 1.2 中引入了 Async I/O,在异步模式下,将 IO 操作异步化,单个并行可以连续发送多个请求,哪个请求先返回就先处理,从而在连续的请求间不需要阻塞式等待,大大提高了流处理效率。
Async I/O 是阿里巴巴贡献给社区的一个呼声非常高的特性,解决与外部系统交互时网络延迟成为了系统瓶颈的问题。
异步查询实际上是把维表的查询操作托管给单独的线程池完成,这样不会因为某一个查询造成阻塞,单个并行可以连续发送多个请求,提高并发效率。
这种方式特别针对涉及网络 IO 的操作,减少因为请求等待带来的消耗。
封装线程池工具类
public class ThreadPoolUtil {
private static ThreadPoolExecutor threadPoolExecutor = null;
// 做成懒汉式单例模式
private ThreadPoolUtil() {
}
public static ThreadPoolExecutor getThreadPool() {
if (threadPoolExecutor == null) {
synchronized (ThreadPoolUtil.class) {
if (threadPoolExecutor == null) {
threadPoolExecutor = new ThreadPoolExecutor(8,
16,
1L,
TimeUnit.MINUTES,
new LinkedBlockingDeque<>());
}
}
}
return threadPoolExecutor;
}
}自定义维度查询接口
这个异步维表查询的方法适用于各种维表的查询,用什么条件查,查出来的结果如何合并到数据流对象中,需要使用者自己定义。
这就是自己定义了一个接口 DimJoinFunction<T>包括两个方法。
public interface DimAsyncJoinFunction<T> {
String getKey(T input);
void join(T input, JSONObject dimInfo) throws ParseException;
}封装维度异步查询的函数类 DimAsyncFunction
该类继承异步方法类 RichAsyncFunction,实现自定义维度查询接口,其中 RichAsyncFunction<IN,OUT>是 Flink 提供的异步方法类,此处因为是查询操作输入类和返回类一致,所以是<T,T>。
RichAsyncFunction 这个类要实现两个方法:
- open 用于初始化异步连接池。
- asyncInvoke 方法是核心方法,里面的操作必须是异步的,如果你查询的数据库有异步api 也可以用线程的异步方法,如果没有异步方法,就要自己利用线程池等方式实现异步查询。
public abstract class DimAsyncFunction<T> extends RichAsyncFunction<T, T> implements DimAsyncJoinFunction<T> {
private Connection connection;
private ThreadPoolExecutor threadPoolExecutor;
private String tableName;
public DimAsyncFunction(String tableName) {
this.tableName = tableName;
}
@Override
public void open(Configuration parameters) throws Exception {
Class.forName(GmallConfig.PHOENIX_DRIVER);
connection = DriverManager.getConnection(GmallConfig.PHOENIX_SERVER);
threadPoolExecutor = ThreadPoolUtil.getThreadPool();
}
@Override
public void asyncInvoke(T input, ResultFuture<T> resultFuture) throws Exception {
// 使用线程提交一个任务
threadPoolExecutor.submit(new Runnable() {
@Override
public void run() {
try {
//获取查询的主键
String id = getKey(input);
//查询维度信息
JSONObject dimInfo = DimUtil.getDimInfo(connection, tableName, id);
//补充维度信息
if (dimInfo != null) {
join(input, dimInfo);
}
//将数据输出
resultFuture.complete(Collections.singletonList(input));
} catch (Exception e) {
e.printStackTrace();
}
}
});
}
/**
* 如果请求没有被处理,那么就会发生超时
* @param input
* @param resultFuture
* @throws Exception
*/
@Override
public void timeout(T input, ResultFuture<T> resultFuture) throws Exception {
System.out.println("TimeOut:" + input);
}
}在这里为什么提出一个接口,因为再这个类中,我们使用的是泛型,而泛型的话,我们不知道具体的类型,也就无法获取里面的属性等信息,比如表明,如何关联两个表,所以我们提出两个方法放到接口中,让使用者自己去根据类型实现。
如何使用这个 DimAsyncFunction,核心的类是 AsyncDataStream,这个类有两个方法一个是有序等待(orderedWait),一个是无序等待(unorderedWait)。
无序等待(unorderedWait)
后来的数据,如果异步查询速度快可以超过先来的数据,这样性能会更好一些,但是会有乱序出现。
有序等待(orderedWait)
严格保留先来后到的顺序,所以后来的数据即使先完成也要等前面的数据。所以性能会差一些。
注意
- 这里实现了用户维表的查询,那么必须重写装配结果 join 方法和获取查询 rowkey的 getKey 方法。
- 方法的最后两个参数 10, TimeUnit. SECONDS ,标识次异步查询最多执行 10 秒,否则会报超时异常。
关联用户维度(在 OrderWideApp 中)
//4.1 关联用户维度
/**
* 这里只是关联维度,和顺序没有关系,所以使用unorderedWait
*/
SingleOutputStreamOperator<OrderWide> orderWideWithUserDS = AsyncDataStream.unorderedWait(
orderWideWithNoDimDS,
//*****************************************************************************************************
// 因为再DimAsyncFunction中类型式泛型,我们无法具体直到表明,所以把方法修改为抽象的,让使用者自己去实现
new DimAsyncFunction<OrderWide>("DIM_USER_INFO") {
@Override
public String getKey(OrderWide orderWide) {
return orderWide.getUser_id().toString();
}
@Override
public void join(OrderWide orderWide, JSONObject dimInfo) throws ParseException {
orderWide.setUser_gender(dimInfo.getString("GENDER"));
String birthday = dimInfo.getString("BIRTHDAY");
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
long currentTs = System.currentTimeMillis();
long ts = sdf.parse(birthday).getTime();
long age = (currentTs - ts) / (1000 * 60 * 60 * 24 * 365L);
orderWide.setUser_age((int) age);
}
},
60,//访问hbase之前会访问zk,访问zk时间超时式60s,所以需要设置超时时间大于等于60
TimeUnit.SECONDS);
//打印测试
// orderWideWithUserDS.print("orderWideWithUserDS");
//4.2 关联地区维度
SingleOutputStreamOperator<OrderWide> orderWideWithProvinceDS = AsyncDataStream.unorderedWait(orderWideWithUserDS,//这里关联的流应该式在哦用户流基础上关联
new DimAsyncFunction<OrderWide>("DIM_BASE_PROVINCE") {
@Override
public String getKey(OrderWide orderWide) {
return orderWide.getProvince_id().toString();
}
@Override
public void join(OrderWide orderWide, JSONObject dimInfo) throws ParseException {
orderWide.setProvince_name(dimInfo.getString("NAME"));
orderWide.setProvince_area_code(dimInfo.getString("AREA_CODE"));
orderWide.setProvince_iso_code(dimInfo.getString("ISO_CODE"));
orderWide.setProvince_3166_2_code(dimInfo.getString("ISO_3166_2"));
}
}, 60, TimeUnit.SECONDS);
//4.3 关联SKU维度
SingleOutputStreamOperator<OrderWide> orderWideWithSkuDS = AsyncDataStream.unorderedWait(
orderWideWithProvinceDS, new DimAsyncFunction<OrderWide>("DIM_SKU_INFO") {
@Override
public void join(OrderWide orderWide, JSONObject jsonObject) throws ParseException {
orderWide.setSku_name(jsonObject.getString("SKU_NAME"));
orderWide.setCategory3_id(jsonObject.getLong("CATEGORY3_ID"));
orderWide.setSpu_id(jsonObject.getLong("SPU_ID"));
orderWide.setTm_id(jsonObject.getLong("TM_ID"));
}
@Override
public String getKey(OrderWide orderWide) {
return String.valueOf(orderWide.getSku_id());
}
}, 60, TimeUnit.SECONDS);
//4.4 关联SPU维度
SingleOutputStreamOperator<OrderWide> orderWideWithSpuDS = AsyncDataStream.unorderedWait(
orderWideWithSkuDS, new DimAsyncFunction<OrderWide>("DIM_SPU_INFO") {
@Override
public void join(OrderWide orderWide, JSONObject jsonObject) throws ParseException {
orderWide.setSpu_name(jsonObject.getString("SPU_NAME"));
}
@Override
public String getKey(OrderWide orderWide) {
return String.valueOf(orderWide.getSpu_id());
}
}, 60, TimeUnit.SECONDS);
//4.5 关联TM维度
SingleOutputStreamOperator<OrderWide> orderWideWithTmDS = AsyncDataStream.unorderedWait(
orderWideWithSpuDS, new DimAsyncFunction<OrderWide>("DIM_BASE_TRADEMARK") {
@Override
public void join(OrderWide orderWide, JSONObject jsonObject) throws ParseException {
orderWide.setTm_name(jsonObject.getString("TM_NAME"));
}
@Override
public String getKey(OrderWide orderWide) {
return String.valueOf(orderWide.getTm_id());
}
}, 60, TimeUnit.SECONDS);
//4.6 关联Category维度
SingleOutputStreamOperator<OrderWide> orderWideWithCategory3DS = AsyncDataStream.unorderedWait(
orderWideWithTmDS, new DimAsyncFunction<OrderWide>("DIM_BASE_CATEGORY3") {
@Override
public void join(OrderWide orderWide, JSONObject jsonObject) throws ParseException {
orderWide.setCategory3_name(jsonObject.getString("NAME"));
}
@Override
public String getKey(OrderWide orderWide) {
return String.valueOf(orderWide.getCategory3_id());
}
}, 60, TimeUnit.SECONDS);
orderWideWithCategory3DS.print("orderWideWithCategory3DS>>>>>>>>>>>");关联的思路
关联维度信息 维度表在HBase Phoenix,现在假如关联用户的维度信息:
关联用户维度,比如关联用户表,首先获取用户的id
根据user_id查询Phoenix用户信息,也就是去hbase中根据id查询用户信息,因为这一个步骤,很多地方都用,所以封装为一个工具类。
将用户信息补充至orderWide并且返回
简单来说就上面三个步骤,关联所有的维度信息都是使用上面的方法,关联哪一个维度表,就去除哪一个维度表的主键进行关联。比如还有地区维度,SKU,SPU。
结果写入 Kafka Sink
//TODO 5.将数据写入Kafka,写入的式dwm_order_wide主题
orderWideWithCategory3DS
.map(JSONObject::toJSONString)
.addSink(MyKafkaUtils.getKafkaProducer(orderWideSinkTopic));s订单宽表已经输出到kafka的主题当中了。
DWM 层-支付宽表
需求分析和思路
再支付表中,支付行为主要和订单相关,那么我们希望根据商品来计算其总金额,也就是被支付的数量,被支付的次数,但是支付表中是和订单相关,并没有商品的明细,所以我们需要做一个支付宽表。
支付宽表的目的,最主要的原因是支付表没有到订单明细,支付金额没有细分到商品上,没有办法统计商品级的支付状况。
所以本次宽表的核心就是要把支付表的信息与订单宽表关联上
解决方案有两个
- 一个是把订单宽表输出到 HBase上,在支付宽表计算时查询 HBase,这相当于把订单宽表作为一种维度进行管理。
- 一个是用流的方式接收订单宽表,然后用双流 join 方式进行合并。因为订单与支付产生有一定的时差。所以必须用 intervalJoin 来管理流的状态时间,保证当支付到达时订单宽表还保存在状态中。
在这里我们选用第二种方式,因为订单和支付中间不是连续的,可能下订单了,但是过了15分钟后支付,而这需要保存为一个状态,如果这个状态使用双流join,只需要将状态保存15分钟即可,但是Hbase默认是永久保存的,但是这里并不需要永久保存状态。
另一个原因是如果把订单宽表作为维度表去查询,因为这个表很大,查询延迟必然很高。
使用kafka双流Join效率高,实现起来相对容易。订单宽表本来是在kafka中,没必要再写入hbase中作为宽表处理,这样增加了难度和复杂度。
创建支付实体类 PaymentInfo
@Data
public class PaymentInfo {
Long id;
Long order_id;
Long user_id;
BigDecimal total_amount;
String subject;
String payment_type;
String create_time;
String callback_time;
}创建支付宽表实体类 PaymentWide
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.commons.beanutils.BeanUtils;
import java.lang.reflect.InvocationTargetException;
import java.math.BigDecimal;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class PaymentWide {
Long payment_id;
String subject;
String payment_type;
String payment_create_time;
String callback_time;
Long detail_id;
Long order_id;
Long sku_id;
BigDecimal order_price;
Long sku_num;
String sku_name;
Long province_id;
String order_status;
Long user_id;
BigDecimal total_amount;
BigDecimal activity_reduce_amount;
BigDecimal coupon_reduce_amount;
BigDecimal original_total_amount;
BigDecimal feight_fee;
BigDecimal split_feight_fee;
BigDecimal split_activity_amount;
BigDecimal split_coupon_amount;
BigDecimal split_total_amount;
String order_create_time;
String province_name; //查询维表得到
String province_area_code;
String province_iso_code;
String province_3166_2_code;
Integer user_age; //用户信息
String user_gender;
Long spu_id; //作为维度数据 要关联进来
Long tm_id;
Long category3_id;
String spu_name;
String tm_name;
String category3_name;
public PaymentWide(PaymentInfo paymentInfo, OrderWide orderWide) {
mergeOrderWide(orderWide);
mergePaymentInfo(paymentInfo);
}
public void mergePaymentInfo(PaymentInfo paymentInfo) {
if (paymentInfo != null) {
try {
BeanUtils.copyProperties(this, paymentInfo);
payment_create_time = paymentInfo.create_time;
payment_id = paymentInfo.id;
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
}
}
}
public void mergeOrderWide(OrderWide orderWide) {
if (orderWide != null) {
try {
BeanUtils.copyProperties(this, orderWide);
order_create_time = orderWide.create_time;
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
}
}
}
}支付宽表处理程序
//数据流:web/app -> nginx -> SpringBoot -> Mysql -> FlinkApp -> Kafka(ods) -> FlinkApp -> Kafka/Phoenix(dwd-dim) -> FlinkApp(redis) -> Kafka(dwm) -> FlinkApp -> Kafka(dwm)
//程 序: MockDb -> Mysql -> FlinkCDC -> Kafka(ZK) -> BaseDbApp -> Kafka/Phoenix(zk/hdfs/hbase) -> OrderWideApp(Redis) -> Kafka -> PaymentWideApp -> Kafka
public class PaymentWideApp {
public static void main(String[] args) throws Exception {
//TODO 1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//1.1 设置CK&状态后端
//env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/gmall-flink-210325/ck"));
//env.enableCheckpointing(5000L);
//env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//env.getCheckpointConfig().setCheckpointTimeout(10000L);
//env.getCheckpointConfig().setMaxConcurrentCheckpoints(2);
//env.getCheckpointConfig().setMinPauseBetweenCheckpoints(3000);
//env.setRestartStrategy(RestartStrategies.fixedDelayRestart());
//TODO 2.读取Kafka主题的数据创建流 并转换为JavaBean对象 提取时间戳生成WaterMark
String groupId = "payment_wide_group";
String paymentInfoSourceTopic = "dwd_payment_info";
String orderWideSourceTopic = "dwm_order_wide";
String paymentWideSinkTopic = "dwm_payment_wide";
// 订单数据流
SingleOutputStreamOperator<OrderWide> orderWideDS = env.addSource(MyKafkaUtils.getKafkaConsumer(orderWideSourceTopic, groupId))
.map(line -> JSON.parseObject(line, OrderWide.class))
// forMonotonousTimestam表示时间戳是增长的方式
.assignTimestampsAndWatermarks(WatermarkStrategy.<OrderWide>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<OrderWide>() {
@Override
public long extractTimestamp(OrderWide element, long recordTimestamp) {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
try {
return sdf.parse(element.getCreate_time()).getTime();
} catch (ParseException e) {
e.printStackTrace();
return recordTimestamp;
}
}
}));
// 支付数据流
SingleOutputStreamOperator<PaymentInfo> paymentInfoDS = env.addSource(MyKafkaUtils.getKafkaConsumer(paymentInfoSourceTopic, groupId))
.map(line -> JSON.parseObject(line, PaymentInfo.class))
.assignTimestampsAndWatermarks(WatermarkStrategy.<PaymentInfo>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<PaymentInfo>() {
@Override
public long extractTimestamp(PaymentInfo element, long recordTimestamp) {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
try {
return sdf.parse(element.getCreate_time()).getTime();
} catch (ParseException e) {
e.printStackTrace();
return recordTimestamp;
}
}
}));
//TODO 3.双流JOIN
SingleOutputStreamOperator<PaymentWide> paymentWideDS = paymentInfoDS.keyBy(PaymentInfo::getOrder_id)
.intervalJoin(orderWideDS.keyBy(OrderWide::getOrder_id))
.between(Time.minutes(-15), Time.seconds(5))//给5s的时间延迟
.process(new ProcessJoinFunction<PaymentInfo, OrderWide, PaymentWide>() {
@Override
public void processElement(PaymentInfo paymentInfo, OrderWide orderWide, Context ctx, Collector<PaymentWide> out) throws Exception {
out.collect(new PaymentWide(paymentInfo, orderWide));
}
});
//TODO 4.将数据写入Kafka,写入的是支付宽表主题:dwm_payment_wide
paymentWideDS.print(">>>>>>>>>");
paymentWideDS
.map(JSONObject::toJSONString)
.addSink(MyKafkaUtils.getKafkaProducer(paymentWideSinkTopic));
//TODO 5.启动任务
env.execute("PaymentWideApp");
}
}封装日期转换工具类
public class DateTimeUtil {
private final static DateTimeFormatter formater = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
public static String toYMDhms(Date date) {
LocalDateTime localDateTime = LocalDateTime.ofInstant(date.toInstant(), ZoneId.systemDefault());
return formater.format(localDateTime);
}
public static Long toTs(String YmDHms) {
LocalDateTime localDateTime = LocalDateTime.parse(YmDHms, formater);
return localDateTime.toInstant(ZoneOffset.of("+8")).toEpochMilli();
}
}因为SimpleDateFormat不是一个线程安全的类,如果使用SimpleDateFormat类,那么需要把这个操作放在一个方法内部,让他变为一个局部变量,否则放在方法外面,就存在线程安全问题。
LocalDateTime是一个线程安全的类,全局只有一个对象,也可以保证线程安全,但是上面的SimpleDateFormat类,全局只有一个就存在线程安全问题。
小结
使用技术
- 学会利用状态(state)进行去重操作。(需求:UV 计算)
- 学会利用 CEP 可以针对一组数据进行筛选判断。需求:跳出行为计算
- 学会使用 intervalJoin 处理流 join
- 学会处理维度关联,并通过旁路缓存和异步查询对其进行性能优化。
再DWM层,我们形成了四张宽表:
- 访客主题宽表(离线数仓按照user_id,实时按照mid来)
- 跳出明细主题宽表
- 商品主题宽表(也就是订单宽表)
- 支付宽表
形成三张宽表,主要是为ads层统计服务
实现类说明
UniqueVisitApp
访客 UV 计算,也就是计算每天活跃用户。
UserJumpDetailApp
跳出明细计算
OrderInfo
订单实体类。
OrderDetail
订单明细实体类
OrderWideApp
OrderWide
订单表和订单明细表join之后形成的宽表实体类。
OrderWide
通用工具类,实现向mysql或者Hbase中插入数据。
DimUtil
封装查询维度的工具类 DimUtil,在查询维度信息的时候,只有表名字和我们传输的过滤条件不同,其他的sql基本都一样,所以我们再做一次封装。
RedisUtil
实现Rides缓存类。因为直接访问hbase进行数据的查询延迟非常高,如果连接不关闭,大概处理一条数据是13毫秒,也就是单并行度,一秒钟大概处理80条数据,80次访问,所以使用Rides进行优化。
在删除数据的时候,我们先删除Rides中数据,然后写入hbase中,这样做主要保证数据一致性。
由于是两个不同的进程,如果再把Rides中的数据删除之后,那orderWideApp刚好又查询了一次,那么又把查询到的老数据写入Rides,这个时候,还没有向Hbase中写入数据。此时Rides中还是老的数据。
- 先删除Rides中数据,在改hbase中数据,在删除Rides中数据,这种方式一定程度上可以解决问题,如果任务挂掉的情况,Rides中数据没有删除掉,还不行。
- 我们Hbase中存储的是维度数据,那么维度数据一般是缓慢变化的,更新操作并不是很多,所以这块可以直接不删除Rides中数据,直接向Rides中写一份修改后的数据即可,这种方案最好。如果写入hbase失败怎么办,因为Rides中数据是保存24小时的,即使保存到hbase中的任务失败,那么我们可以重新启动任务,在24小时内重新写入hbase即可。所以解决了hbase中间出错的问题,如果Rides失败,那么直接去hbase中查询数据即可,Rides启动之后,再写入Rides即可,这样即使中间某一方出错,其他来查询也不会出现问题。
- 为什么不使用事务或者锁方案,因为在Rides中锁是乐观锁,又处理请求的话,会释放锁。
我们一共6个维度表,假设6个维度表数据全部再Rides中,那么一个维度的查询需要1毫秒,6个维度需要6毫秒,我们假设5毫秒,那么就是说,每一秒中,单个并行度可以处理200条数据,这样就不会产生反压。如果数据超过200每一秒,那么就会产生反压。再高峰期大概每一秒1000-2000条,所以还需要对这种方案进行优化。
目前Rides方案是满足要求,但是我们需要考虑可拓展性,比如再搞活动的时候,或者kafka做压测的时候,最小是2000,所以我们还需要优化。
我们一般不会对Rides加锁,因为Rides是乐观锁。
ThreadPoolUtil
获取单例的线程池对象 corePoolSize:指定了线程池中的线程数量,它的数量决定了添加的任务是开辟新的线程 去执行,还是放到 workQueue 任务队列中去; maximumPoolSize:指定了线程池中的最大线程数量,这个参数会根据你使用的 workQueue 任务队列的类型,决定线程池会开辟的最大线程数量; keepAliveTime:当线程池中空闲线程数量超过 corePoolSize 时,多余的线程会在多长时间 内被销毁; unit:keepAliveTime 的单位 workQueue:任务队列,被添加到线程池中,但尚未被执行的任务
DimAsyncJoinFunction
自定义维度查询接口类
DimAsyncFunction
实现异步查询功能。
PaymentInfo
支付实体对象
PaymentWide
支付宽表实体类
PaymentWideApp
支付宽表处理程序
DateTimeUtil
封装日期转换工具类。
贡献者
 codingLab
codingLab版权所有
版权归属:
许可证: