2、实时数仓DWD层设计
功能一:需求分析及实现思路
分层需求分析
在之前介绍实时数仓概念时讨论过,建设实时数仓的目的,主要是增加数据计算的复用性。每次新增加统计需求时,不至于从原始数据进行计算,而是从半成品继续加工而成。
我们这里从Kafka的ODS层读取用户行为日志以及业务数据,并进行简单处理,写回到 Kafka 作为 DWD 层。
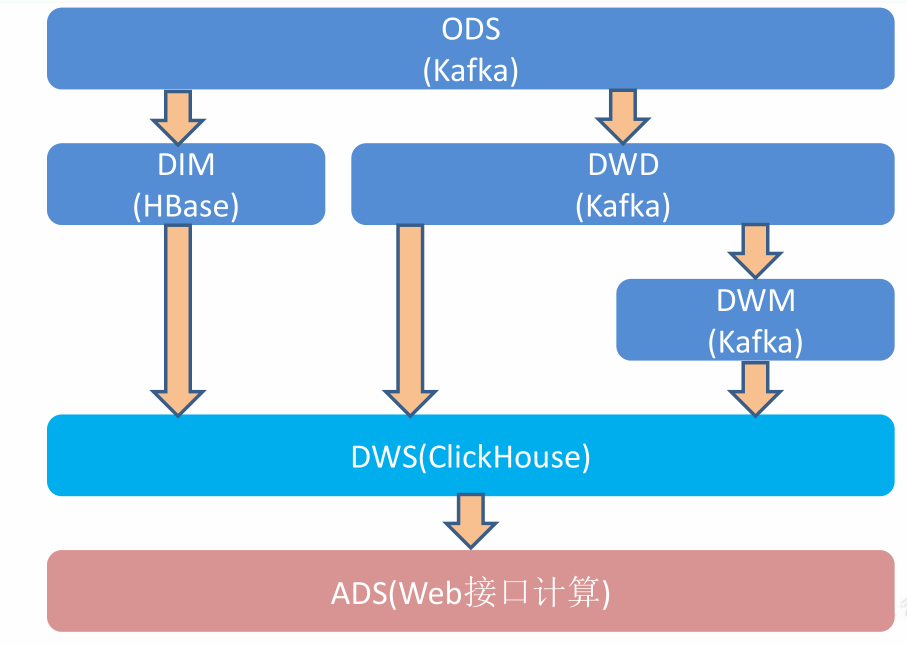
每一层的功能说明
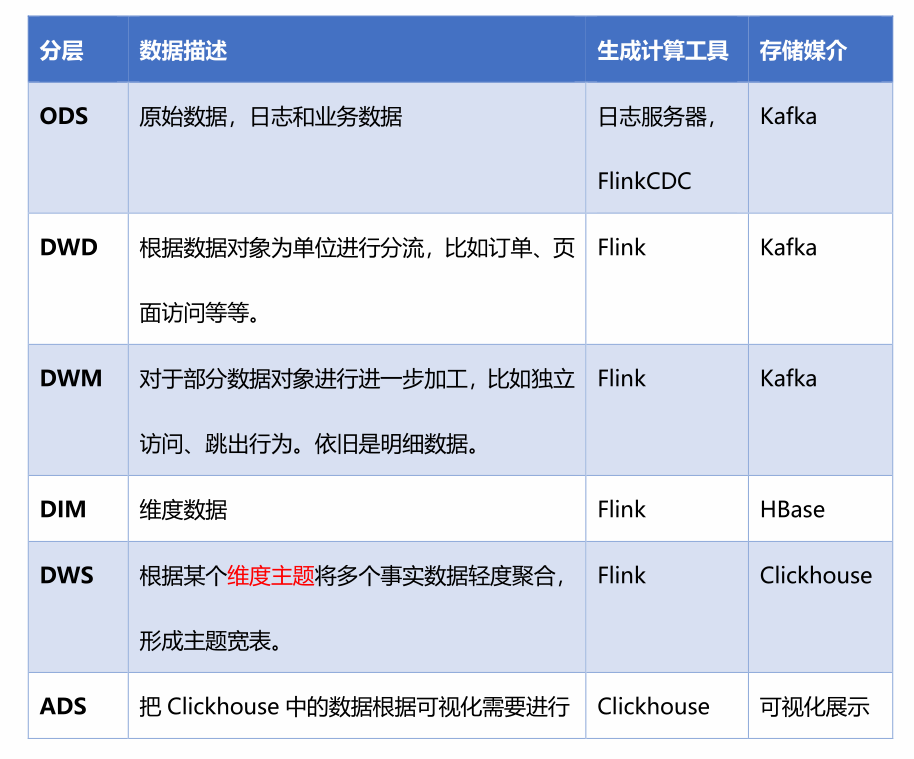
ods层
存放原始的数据,本项目中存放行为数据的是:ods_base_log表,日志数据通过springboot产生,然后传输到kafka的ods_base_log分区中,供后续的使用。
存放业务数据的是:业务数据在mysql数据库中,本项目使用的是Flink CDC监控库中的所有表,将数据传输到kafka的ods_base_db主题中。
dwd和dim
这两层都是属于dwd层,只不过dim层存放的是维度表数据,维度数据存放在Hbase数据库中,dwd层存储的是事实表数据,事实表数据存放在kafka主题当中。
在dwd层,也可以认为是对数据做清晰工作,过滤掉不合法的数据。
dwm
这一层是dwd层到dws层之间的过度层,也可以看作是中间数据层。提取公共数据为后面ads层计算指标做准备。
dws
dws层数据存储在clickhouse中,根据某个维度主题将多个事实数据轻度聚合,形成主题宽表。
ads
把clickHouse中的数据,根据可视化需求,进行聚合。这一步可以看作我们具体的需求。
功能二:准备用户行为日志 DWD 层
这里首先说明以下用户行为数据的格式
/**
* 封装的数据格式
* {
* "database":"",
* "tableName":"",
* "before":{"id":"","tm_name":""....},
* "after":{"id":"","tm_name":""....},
* "type":"c u d",
* //"ts":156456135615
* }
*/- database:数据库
- tableNmae:具体的表名字
- before:更新之前的数据
- after:更新之后的数据
- type:对数据的操作,delete,update,insert。
- ts:时间戳字段
我们前面采集的日志数据已经保存到 Kafka 的ods_base_log主题当中,作为日志数据的 ODS 层,从 Kafka 的ODS 层读取的日志数据分为 3 类, 页面日志、启动日志和曝光日志。这三类数据虽然都是用户行为数据,但是有着完全不一样的数据结构,所以要拆分处理。将拆分后的不同的日志写回 Kafka 不同主题中,作为日志 DWD 层。
我们的日志分为三类,针对不同的业务,可能有多种分类方法
页面日志输出到主流
启动日志输出到启动侧输出流
曝光日志输出到曝光侧输出流。
在Flink中因为有测输出流,所以我们可以使用测输出流进行分流处理,但是如果在spark streaming中,没有测输出流,我们就需要使用filter进行过滤。
主要任务
识别新老用户
首先需要对日志数据进行一个过滤,过滤掉非json的字符串。这里可以统计出不合法的数据有多少,最后可以计算出脏数据率。
本身客户端业务有新老用户的标识,默认情况下new_id=1表示是新用户,0表示是老用户,但是不够准确,需要用实时计算再次确认(不涉及业务操作,只是单纯的做个状态确认)。所以在这里我们使用状态编程。
首先需要根据mid来进行分类操作,只有针对相同用户的操作才有意义。保存每个 mid 的首次访问日期,每条进入该算子的访问记录,都会把 mid 对应的首次访问时间读取出来,只有首次访问时间不为空,则认为该访客是老访客,否则是新访客。
同时如果是新访客且没有访问记录的话,会写入首次访问时间。
消费 ods_base_log 主题数据创建流
主要工作就是读取ods_base_log中的数据,然后过滤掉不合法的json数据。
//TODO 2.消费 ods_base_log 主题数据创建流
String sourceTopic = "ods_base_log";//西奥菲哪一个topic
String groupId = "base_log_app";//消费者组
DataStreamSource<String> kafkaDS = env.addSource(MyKafkaUtils.getKafkaConsumer(sourceTopic, groupId));
//TODO 3.将每行数据转换为JSON对象
OutputTag<String> outputTag = new OutputTag<String>("Dirty") {
};
SingleOutputStreamOperator<JSONObject> jsonObjDS = kafkaDS.process(new ProcessFunction<String, JSONObject>() {
@Override
public void processElement(String value, Context ctx, Collector<JSONObject> out) throws Exception {
try {
/**
* 在这里对json字符串进行解析的时候,可能有异常,也就是不合法的json字符串,那么我们不能简单的就把异常的数据全部过滤掉
* 而是要保存输出到其他框架中,查看异常数据所占的比例,所以如果发生解析异常,我们将数据写出到测输出流
*/
JSONObject jsonObject = JSON.parseObject(value);
out.collect(jsonObject);
} catch (Exception e) {
//发生异常,将数据写入侧输出流
/**
* 脏数据的处理,这里是一个可以说的问题
*/
ctx.output(outputTag, value);
}
}
});
//打印脏数据
jsonObjDS.getSideOutput(outputTag).print("Dirty>>>>>>>>>>>");新老用户校验 状态编程
//TODO 4.新老用户校验 状态编程
/**
* 在处理新老用户的时候,我们是根据common中mid字段进行判断的,所以我们现需要根据mid字段进行分组操作
*/
SingleOutputStreamOperator<JSONObject> jsonObjWithNewFlagDS = jsonObjDS.keyBy(jsonObj -> jsonObj.getJSONObject("common").getString("mid"))
// 因为需要操作状态,所以使用RichMapFunction,
.map(new RichMapFunction<JSONObject, JSONObject>() {
private ValueState<String> valueState;
@Override
public void open(Configuration parameters) throws Exception {
valueState = getRuntimeContext().getState(new ValueStateDescriptor<String>("value-state", String.class));
}
// 针对每一条数据处理
@Override
public JSONObject map(JSONObject value) throws Exception {
//获取数据中的"is_new"标记
String isNew = value.getJSONObject("common").getString("is_new");
//判断isNew标记是否为"1",只有标记位1的时候,我们才需要处理
/**
* 这里为什么要修改位0,比如针对同一条数据,第一次来的时候,new_mid=1表示是新数据,那么第二次如果还是这条数据来了
* 那么此时他就是老的数据,所以需要把new_mid修改位0,表示他不是新的数据
*/
if ("1".equals(isNew)) {
//获取状态数据
String state = valueState.value();
if (state != null) {
//修改isNew标记
value.getJSONObject("common").put("is_new", "0");
} else {
valueState.update("1");
}
}
return value;
}
});利用侧输出流实现数据拆分
根据日志数据内容,将日志数据分为 3 类, 页面日志、启动日志和曝光日志。页面日志输出到主流,启动日志输出到启动侧输出流,曝光日志输出到曝光日志侧输出流。
那么我们具体是如何区分上面这三种页面呢:
启动日志有下面字段:common,start,ts
曝光日志:common,displays,page,ts字段
页面日志:page,common,ts
所以,我们根据一条数据中是否有start,display去判断日志的类型。
代码实现
//TODO 5.分流 侧输出流 页面:主流 启动:侧输出流 曝光:侧输出流
OutputTag<String> startTag = new OutputTag<String>("start") {
};
OutputTag<String> displayTag = new OutputTag<String>("display") {
};
SingleOutputStreamOperator<String> pageDS = jsonObjWithNewFlagDS.process(new ProcessFunction<JSONObject, String>() {
@Override
public void processElement(JSONObject value, Context ctx, Collector<String> out) throws Exception {
//获取启动日志字段
String start = value.getString("start");
if (start != null && start.length() > 0) {
//将数据写入启动日志侧输出流
ctx.output(startTag, value.toJSONString());
} else {
/**
* 曝光数九也是页面日志,所以不是启动日志的话,我们都邪物页面日志输出流
*/
//将数据写入页面日志主流
out.collect(value.toJSONString());
//取出数据中的曝光数据
JSONArray displays = value.getJSONArray("displays");
if (displays != null && displays.size() > 0) {
//获取页面ID
String pageId = value.getJSONObject("page").getString("page_id");
for (int i = 0; i < displays.size(); i++) {
JSONObject display = displays.getJSONObject(i);
//添加页面id
display.put("page_id", pageId);
//将输出写出到曝光侧输出流
ctx.output(displayTag, display.toJSONString());
}
}
}
}
});
//TODO 6.提取侧输出流
DataStream<String> startDS = pageDS.getSideOutput(startTag);
DataStream<String> displayDS = pageDS.getSideOutput(displayTag);将不同流的数据推送下游的 Kafka 的不同 Topic 中
页面日志:dwd_page_log
曝光日志:dwd_display_log
启动日志:dwd_start_log
在ods层中,每一条数据都是json数据的格式。
在dwd层,我们需要转换位json对象。
代码实现
//TODO 7.将三个流进行打印并输出到对应的Kafka主题中
startDS.print("Start>>>>>>>>>>>");
pageDS.print("Page>>>>>>>>>>>");
displayDS.print("Display>>>>>>>>>>>>");
startDS.addSink(MyKafkaUtils.getKafkaProducer("dwd_start_log"));
pageDS.addSink(MyKafkaUtils.getKafkaProducer("dwd_page_log"));
displayDS.addSink(MyKafkaUtils.getKafkaProducer("dwd_display_log"));分流后输入到kafka中的都是json字符串。
功能三:准备业务数据 DWD 层
业务数据的变化,我们可以通过 FlinkCDC 采集到,但是 FlinkCDC 是把全部数据统一写入一个 Topic 中, mysql数据库中的所有表数据全部写入了一个topic中,这些数据包括事实数据,也包含维度数据,这样显然不利于日后的数据处理,所以这个功能是从 Kafka 的业务数据 ODS 层读取数据,经过处理后,将维度数据保存到 HBase,将事实数据写回 Kafka 作为业务数据的 DWD 层。
主要任务
接收 Kafka 数据,过滤空值数据
对 FlinkCDC 抓取数据进行 ETL,有用的部分保留,没用的过滤掉,这里过滤的是type类型为delete的数据,也就打delete标签的数据。
这里为什么需要把delete标签的数据过滤掉,因为在mysql业务数据库中,删除的数据,在下游不需要对其进行处理,所以可以直接在这里进行过滤掉。
实现动态分流功能
由于 FlinkCDC 是把全部数据统一写入一个 Topic 中, 这样显然不利于日后的数据处理。所以需要把各个表拆开处理。但是由于每个表有不同的特点,有些表是维度表,有些表是事实表。
在实时计算中一般把维度数据写入存储容器,一般是方便通过主键查询的数据库比如HBase,Redis,MySQL 等。一般把事实数据写入流中,进行进一步处理,最终形成宽表。
- 在这里为什么没有选择Rides,因为维度数据数据量很大,特别是user维度,数据很大,所以选择使用HBase.也可以用户维度使用Hbase存储,其他的使用Rides,但是这样就复杂了。
- 为什么没有放在Mysql数据库,并发压力大,生产环境中,mysql是和后台打交道,用户的请求都来自mysql,mysql是相应用户的请求,如果我们这个时候去访问mysql,访问压力很大。
这样的配置不适合写在配置文件中(把上面kafka数据流分流操作的配置写入配置文件中),因为这样的话,配置文件在程序启动的时候,只会加载一次,如果修改表了或者业务端随着需求变化每增加一张表,就要修改配置重启计算程序。所以这里需要一种动态配置方案,把这种配置长期保存起来,一旦配置有变化,实时计算可以自动感知。
这种可以有两个方案实现
- 一种是用 Zookeeper 存储,写一个监听事件,通过 Watch 感知数据变化;
- 另一种是用 mysql 数据库存储,周期性的同步;每隔一段时间去查询mysql.
- 另一种是用 mysql 数据库存储,使用广播流。数据配置有变化,就广播到下游数据流中。
第二种方案是周期性同步,使用select语句去查询表,而第三种方案是用Flink cdc去监控配置文件,有变化的话,就广播到下游的所有流中。
这里选择第三种方案,主要是 MySQL 对于配置数据初始化和维护管理,使用 FlinkCDC读取配置信息表,将配置流作为广播流与主流进行连接。
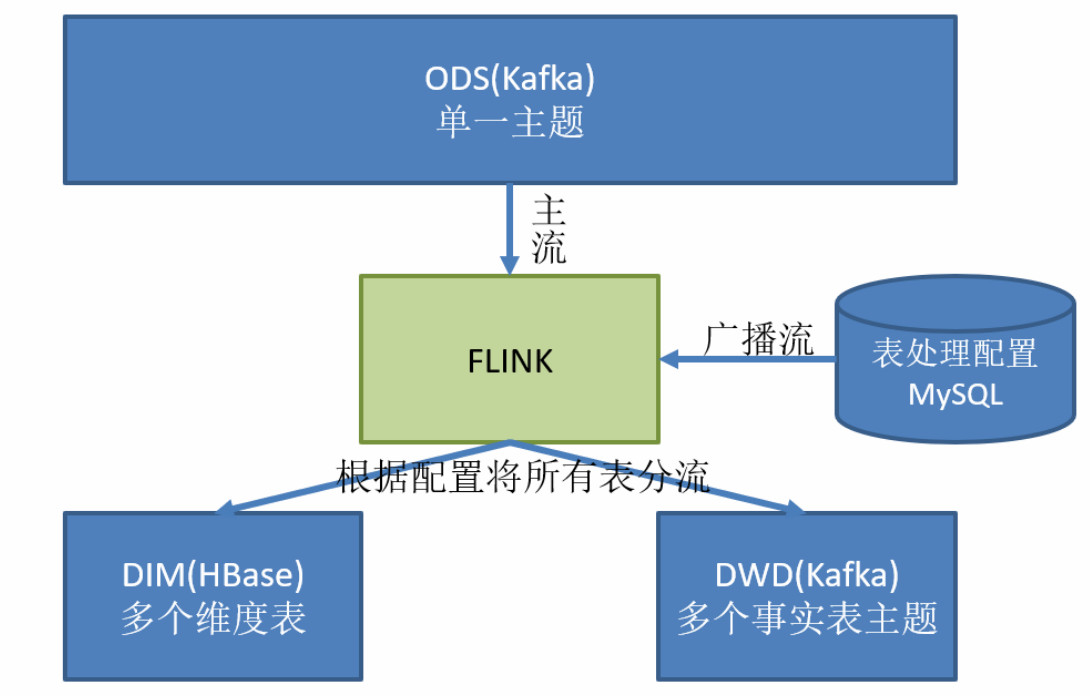
Flink cdc监控表处理配置文件,一旦发现有新的表加入,那么就把监控到的表数据广播流和Flink主流中的数据进行连接,然后根据配置将维度数据和实时数据分发到不同的位置。
但是配置表中的字段我们如何确定,这就需要根据业务进行分析,在本项目中,通过分析确定了如下字段:
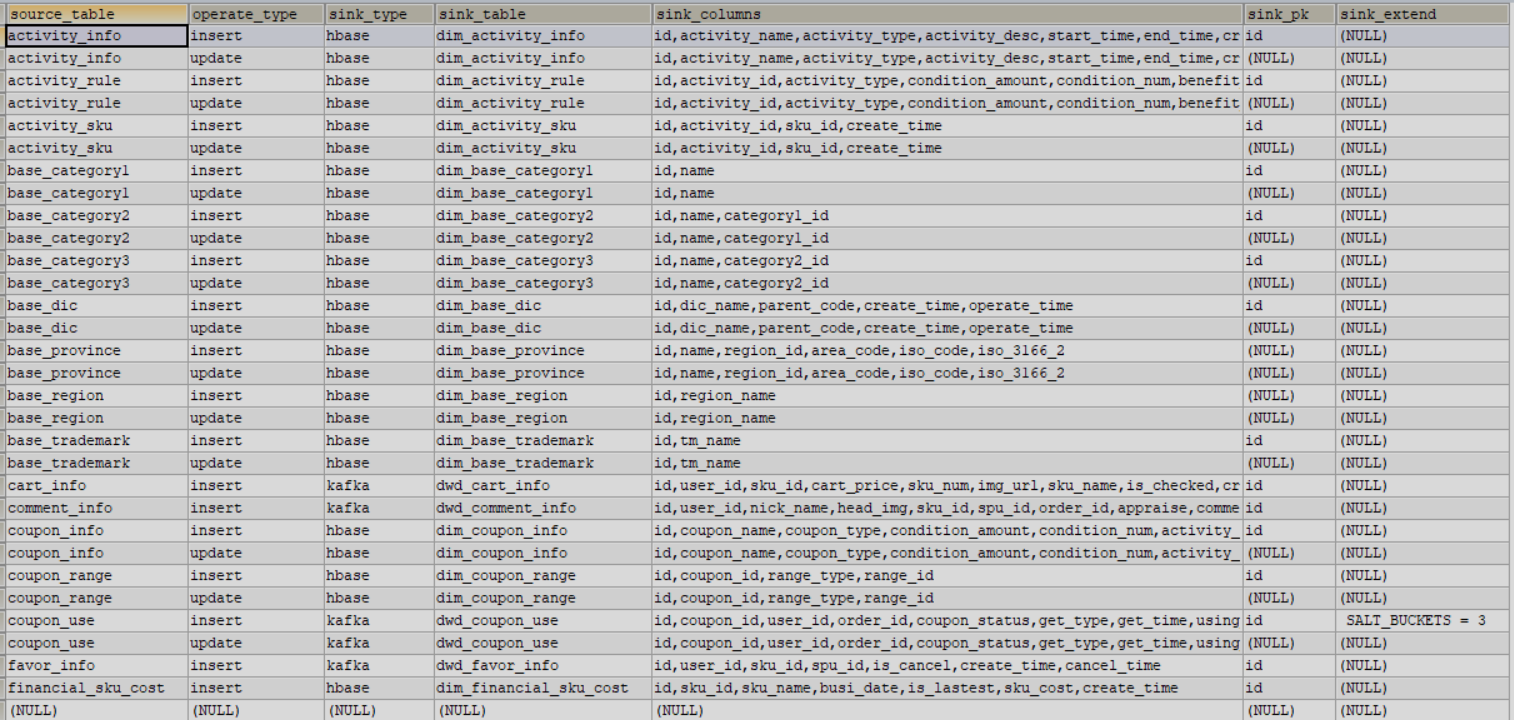

source_table:从kafka数据流中读取的表数据,也就是下游表的来源source。
operator_type:对表的操作类型,也就是说对这张表的插入,删除,更新哪一种类型操作进行监控,如果三种操作都要监控,那么需要添加三条配置信息。
sink_type:这个字段区分的就是维度表还是事实表,也就是将source数据存放在hbase数据库中还是发送到kafka主题当中。
sink_columns:新表中的字段,从source表中读取的数据有很多字段,在建立新表的时候,需要保留的字段,可以选择性的保留。
sink_table:下游表的名字
sink_extend:扩展字段。
把分好的流保存到对应表、主题中
业务数据保存到 Kafka 的主题中
维度数据保存到 HBase 的表中
接收 Kafka 数据,过滤空值数据
这里过滤的空值是过滤掉打了delete标记的数据。注意一点,为什么可以在这里对数据进行过滤,因为我们使用Flink cdc监控数据库中的表数据,如果发生变化之后,将数据读取过来后会重新进行封装,变为json对象,里面有一个type字段类型,说明这一条数据是什么类型的,我们可以根据该字段判断这一条数据是不是脏数据。既然已经打赏了delete的标记,也就没有必要将数据在发送到下游,直接过滤掉即可。
这里首先说明以下用户行为数据的格式
/**
* 封装的数据格式
* {
* "database":"",
* "tableName":"",
* "before":{"id":"","tm_name":""....},
* "after":{"id":"","tm_name":""....},
* "type":"c u d",
* //"ts":156456135615
* }
*/- database:数据库
- tableNmae:具体的表名字
- before:更新之前的数据
- after:更新之后的数据
- type:对数据的操作,delete,update,insert。
- ts:时间戳字段
//TODO 2.消费Kafka ods_base_db 主题数据创建流
String sourceTopic = "ods_base_db"; //消费数据的topic
String groupId = "base_db_app";//消费者组
DataStreamSource<String> kafkaDS = env.addSource(MyKafkaUtils.getKafkaConsumer(sourceTopic, groupId));
//TODO 3.将每行数据转换为JSON对象并过滤(delete) 主流
SingleOutputStreamOperator<JSONObject> jsonObjDS = kafkaDS.map(JSON::parseObject)//将数据转换位json对象
// 对脏数据进行过滤
.filter(new FilterFunction<JSONObject>() {
@Override
public boolean filter(JSONObject value) throws Exception {
//取出数据的操作类型
String type = value.getString("type");
return !"delete".equals(type);
}
});根据 MySQL 的配置表,动态进行分流
创建配置表 table_process
Mysql动态配置表说明
这里的主键是表+操作类型,可以唯一确定一条数据记录。
CREATE TABLE `table_process` (
`source_table` varchar(200) NOT NULL COMMENT '来源表',
`operate_type` varchar(200) NOT NULL COMMENT '操作类型 insert,update,delete',
`sink_type` varchar(200) DEFAULT NULL COMMENT '输出类型 hbase kafka',
`sink_table` varchar(200) DEFAULT NULL COMMENT '输出表(主题)',
`sink_columns` varchar(2000) DEFAULT NULL COMMENT '输出字段',
`sink_pk` varchar(200) DEFAULT NULL COMMENT '主键字段',
`sink_extend` varchar(200) DEFAULT NULL COMMENT '建表扩展',
PRIMARY KEY (`source_table`,`operate_type`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8主题字段是什么意思:
如果输出到hbase中,那么就代表输出的是表中
如果是输出到kafka中,那么就代表输出的是kafak的主题。
输出字段:
- 建表使用,也就是建表中的字段。在原始表中有很多字段,但是输出到hbase或者是kafka中我们一般不需要这么多的字段,那么这个sink_columns就可以控制需要保留多少个字段。
- 对主流中的数据做过滤,因为我建表可能是2个字段,但是主流中的数据有多个字段,所以要进行过滤,保留两个字段。
上面表中是配置信息,最终要给主流中的数据使用,所以把他映射位一个java bean对象更号处理。
创建配置表实体类
public class TableProcess {
//动态分流 Sink 常量
public static final String SINK_TYPE_HBASE = "hbase";
public static final String SINK_TYPE_KAFKA = "kafka";
public static final String SINK_TYPE_CK = "clickhouse";
//来源表
String sourceTable;
//操作类型 insert,update,delete
String operateType;
//输出类型 hbase kafka
String sinkType;
//输出表(主题)
String sinkTable;
//输出字段
String sinkColumns;
//主键字段
String sinkPk;
//建表扩展
String sinkExtend;
}使用FlinkCDC消费配置表并处理成广播流
//TODO 4.使用FlinkCDC消费配置表并处理成 广播流
DebeziumSourceFunction<String> sourceFunction = MySQLSource.<String>builder()
.hostname("hadoop102")
.port(3306)
.username("root")
.password("000000")
.databaseList("gmall-realtime")
.tableList("gmall-realtime.table_process")//监控的表
.startupOptions(StartupOptions.initial())
.deserializer(new CustomerDeserialization())
.build();
// 添加source
DataStreamSource<String> tableProcessStrDS = env.addSource(sourceFunction);
/**
* table_process表有那些字段
* tableName:需要根据表名进行分流
* type:类型,新增和变化的数据放在不同的位置
* sinktable:发送到diw层的表还是发送到dim层的表
*/
MapStateDescriptor<String, TableProcess> mapStateDescriptor = new MapStateDescriptor<String, TableProcess>("map-state", String.class, TableProcess.class);
// 对数据进行广播
BroadcastStream<String> broadcastStream = tableProcessStrDS.broadcast(mapStateDescriptor);连接主流和广播流
BroadcastConnectedStream<JSONObject, String> connectedStream = jsonObjDS.connect(broadcastStream);分流处理数据,广播流数据,主流数据(根据广播流数据进行处理)
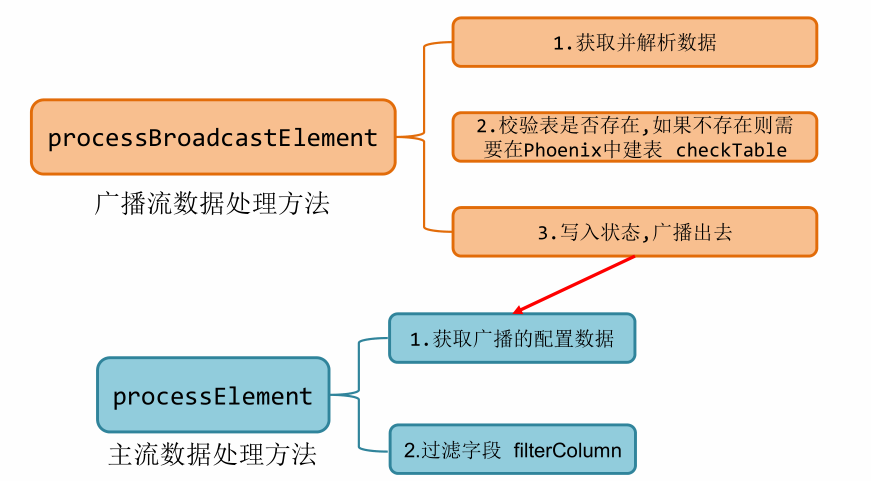
//从测输出流中获取hbase数据
OutputTag<JSONObject> hbaseTag = new OutputTag<JSONObject>("hbase-tag") {
};
SingleOutputStreamOperator<JSONObject> kafka = connectedStream.process(new TableProcessFunction(hbaseTag, mapStateDescriptor));定义一个项目中常用的配置常量类 GmallConfig
public class GmallConfig {
//Phoenix 库名
public static final String HBASE_SCHEMA = "GMALL2021_REALTIME";
//Phoenix 驱动
public static final String PHOENIX_DRIVER = "org.apache.phoenix.jdbc.PhoenixDriver";
//Phoenix 连接参数
public static final String PHOENIX_SERVER =
"jdbc:phoenix:hadoop102,hadoop103,hadoop104:2181";
}自定义函数 TableProcessFunction
自定义TableProcessFunction主要完成的功能是:分流处理数据 ,广播流数据,主流数据(根据广播流数据进行处理)。详情请参考代码。
提取Kafka流数据和HBase流数据
将维度表中的数据写入测输出流中。
DataStream<JSONObject> hbase = kafka.getSideOutput(hbaseTag);将Kafka数据写入Kafka主题,将HBase数据写入Phoenix表
//TODO 8.将Kafka数据写入Kafka主题,将HBase数据写入Phoenix表
kafka.print("Kafka>>>>>>>>");
hbase.print("HBase>>>>>>>>");
// 写入hnase和kafka需要我们自定义
hbase.addSink(new DimSinkFunction());
kafka.addSink(MyKafkaUtils.getKafkaProducer(new KafkaSerializationSchema<JSONObject>() {
@Override
public ProducerRecord<byte[], byte[]> serialize(JSONObject element, @Nullable Long timestamp) {
return new ProducerRecord<byte[], byte[]>(element.getString("sinkTable"),
element.getString("after").getBytes());
}
}));分流 Sink 之保存维度到 HBase(Phoenix)
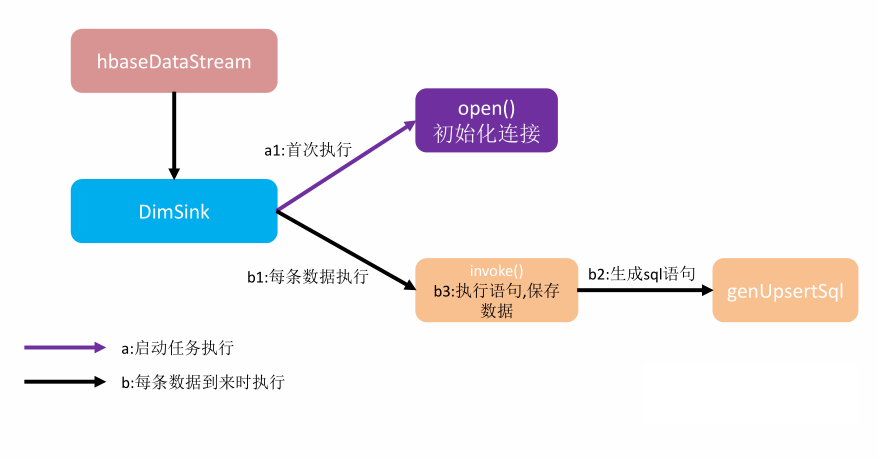
DimSink 继承了 RickSinkFunction,这个 function 得分两条时间线。
- 一条是任务启动时执行 open 操作(图中紫线),我们可以把连接的初始化工作放在此处一次性执行。
- 另一条是随着每条数据的到达反复执行 invoke()(图中黑线),在这里面我们要实现数据的保存,主要策略就是根据数据组合成 sql 提交给 hbase。
public class DimSinkFunction extends RichSinkFunction<JSONObject> {
// 声明一个链接
private Connection connection;
@Override
public void open(Configuration parameters) throws Exception {
// 获取链接
Class.forName(GmallConfig.PHOENIX_DRIVER);
connection = DriverManager.getConnection(GmallConfig.PHOENIX_SERVER);
connection.setAutoCommit(true);
}
//value:{"sinkTable":"dim_base_trademark","database":"gmall-210325-flink","before":{"tm_name":"atguigu","id":12},"after":{"tm_name":"Atguigu","id":12},"type":"update","tableName":"base_trademark"}
//SQL:upsert into db.tn(id,tm_name) values('...','...')
@Override
public void invoke(JSONObject value, Context context) throws Exception {
PreparedStatement preparedStatement = null;
try {
//获取SQL语句
String sinkTable = value.getString("sinkTable");
JSONObject after = value.getJSONObject("after");
String upsertSql = genUpsertSql(sinkTable,
after);
System.out.println(upsertSql);
//预编译SQL
preparedStatement = connection.prepareStatement(upsertSql);
//判断如果当前数据为更新操作,则先删除Redis中的数据,因为这里需要保存数据的一致性
// 在Rides中删除一个不存在的数据是不会报错的
if ("update".equals(value.getString("type"))){
DimUtil.delRedisDimInfo(sinkTable.toUpperCase(), after.getString("id"));
}
//执行插入操作
preparedStatement.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
} finally {
if (preparedStatement != null) {
preparedStatement.close();
}
}
}
//data:{"tm_name":"Atguigu","id":12}
//SQL:upsert into db.tn(id,tm_name,aa,bb) values('...','...','...','...')
private String genUpsertSql(String sinkTable, JSONObject data) {
Set<String> keySet = data.keySet();
Collection<Object> values = data.values();
//keySet.mkString(","); => "id,tm_name"
return "upsert into " + GmallConfig.HBASE_SCHEMA + "." + sinkTable + "(" +
StringUtils.join(keySet, ",") + ") values('" +
StringUtils.join(values, "','") + "')";
}
}在本项目中,只实现了插入和更新操作,不需要删除操作。
分流 Sink 之保存业务数据到 Kafka 主题
在 MyKafkaUtil 中添加属性定义 private static String DEFAULT_TOPIC = "dwd_default_topic";,将事实表中的数据保存到这个默认的主题当中。
两个创建 FlinkKafkaProducer 方法对比
- 前者给定确定的 Topic
- 而后者除了缺省情况下会采用 DEFAULT_TOPIC,一般情况下可以根据不同的业务 数据在 KafkaSerializationSchema 中通过方法实现。
public static <T> FlinkKafkaProducer<T> getKafkaProducer(KafkaSerializationSchema<T> kafkaSerializationSchema) {
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers);
return new FlinkKafkaProducer<T>(default_topic,
kafkaSerializationSchema,
properties,
FlinkKafkaProducer.Semantic.EXACTLY_ONCE);
}数据流
数据流:web/app -> nginx -> SpringBoot -> Mysql -> FlinkApp -> Kafka(ods) -> FlinkApp -> Kafka(dwd)/Phoenix(dim)
程 序:mockDb -> Mysql -> FlinkCDC -> Kafka(依赖ZK) -> BaseDBApp->Kafka(zk)/Phoenix(hbase,zk,hdfs)
现在来梳理以下BaseDBApp所作的事情
- 首先读取Kafka的ods_base_log主题中的数据。
- 将每行数据转换为JSON对象并过滤(delete) 主流,因为传输过来的是json字符串,所以可以转换为json对象格式,过滤数据,滤掉的是type类型为delete的数据,也就是打上了逻辑标记。
- 使用FlinkCDC消费配置表并处理成广播流,在这一步,我们做了下面的工作:
- 首先使用Flink cdc监控配置表。
- 创建一个map状态,键是json对象格式,值是字符串类型。
- 分流操作,实现TableProcessFunction()类,在这个类中,分别对主流kafka数据流和广播流配置表进行操作。
- 在广播流中:
- 首先解析我们的json字符串数据得到after这个数据。
- 建表,判断输出位置是hbase我们才需要建表。
- 写入状态,广播出去。
- 在主流中:
- 获取状态数据,首先获取状态,状态的key是:tableName-operatorType
- 过滤字段
- 分流
- 提取Kafka流数据和HBase流数据
- 将Kafka数据写入Kafka主题,将HBase数据写入Phoenix表
BaseDbAPP的逻辑:首先从ods_base_log中读取主的数据流,主数据流中包含所有的表信息
测输出流什么意思呢?假如我们从主输出流中读取一张表数据,这张表是维度数据,需要加载到hbase中,但是维度数据表又不需要那么多的字段,所以我们就建立一张配置表,这张配置表中保存的是需要建立的维度表的样子,也就是一些元数据信息,那么就把配置表广播到下游,建立一张表,然后插入数据。如果下游vhbase中有这张表,那么就不需要建立,如果数据变更,直接插入或者更新即可,如果下游每有这张维度表,那么就根据配置表在hbase数据库中建立这张表,然后插入或者更新数据。这里需要注意一点,并没有处理删除数据,也就是说如果在数据库中删除一条数据,那么在mysql数据库中这一条数据不存在,但是在hbade中数据还是存在呢,为什么不把hbase中的数据也删除,因为没有必要删除,因为不影响我们之后处理数据的统计,如果不删除数据,那么之后数据库中又插入这一条数据,那么在hbase中直接左更新即可。
写入kafka也是同样的逻辑,只不过不用建立表,而是写入kafka主题即可,写入到kafka中是以json对象形式写入,同样根据配置流中的信息,选取固定的字段,封装为json对象,然后写入kafka主题。
写入hbase后数据显示的格式:
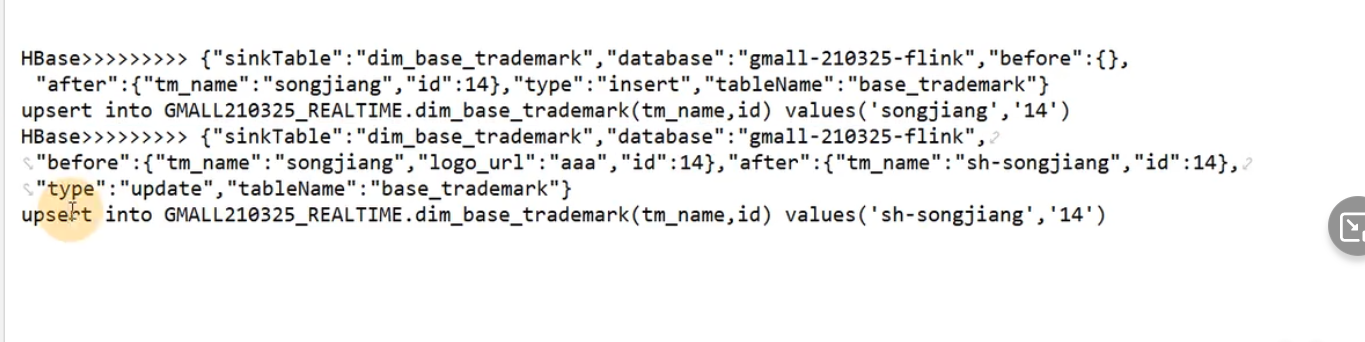
上面在hbase或者kafka中需要保存的字段,在配置表的sink_columns中保存。
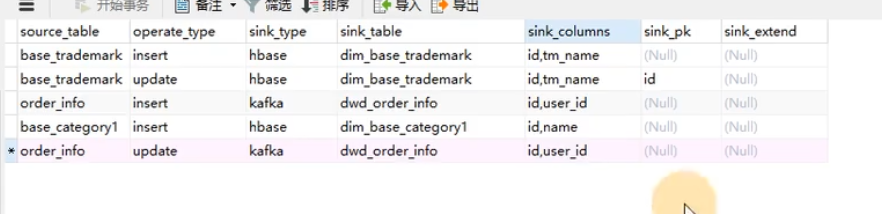
假如写入kafka主题,看上面的例子,Flinkcdc监控的order_info表中,后面对应的操作是insert,对应的sink_type是kafka也就是输出到kafka中,sink_table表示写入kafka的主题是:dwd_order_info,写入主题封装成json对象,对象的属性是sink_cloumns下面的字段,那么这一行数据表示,如果order_info表中的数据如果与insert插入操作,那么就会输出到kafka主题当中,如果是删除或者更新update数据那么就不会写入kafak主题,因为没有配置这两个字段,如果也想监控删除或者update数据,那么只需要添加一条配置信息,将operate_type修改为update或者delete即可,那么之后又更新或者删除数据,都会写入kafka主题中。也就是配置信息中表最后一行形式。
更新数据后,kafka显示的数据格式:

注意:
如果配置表中,没有配置某一张表监控的操作,那么会显示组合不存在信息:

总结
DWD 的实时计算核心就是数据分流,其次是状态识别。在开发过程中我们实践了几个灵活度较强算子,比如 RichMapFunction, ProcessFunction, RichSinkFunction。 那这几个我们什么时候会用到呢?如何选择?
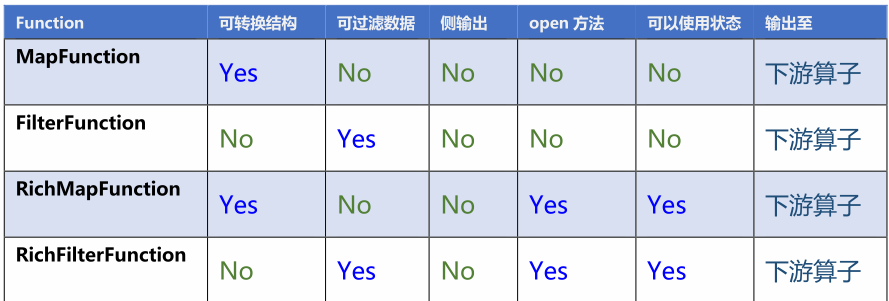
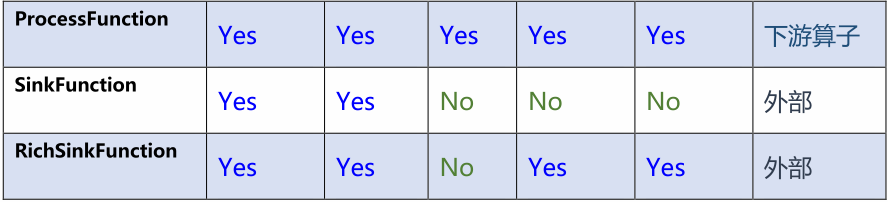
从对比表中能明显看出,Rich 系列能功能强大,ProcessFunction 功能更强大,但是相对的越全面的算子使用起来也更加繁琐。
RichMapFunction:new RichMapFunction<JSONObject, JSONObject>()新老用户校验这块,因为涉及状态编程,所以使用的是RichMapFunction函数。
RichSinkFunction:RichSinkFunction将分流后的维度表数据输出到hbase中使用了RichSinkFunction接口。
ODS
数据源:行为数据(日志数据),业务数据
架构分析:重点讲述
Flink CDC: DataStream/Flink sql对比 FlinkCDC/Maxwell/Canal对比
ODS层做了什么:
- 保持数据原貌,不做任何修改。
- 存储到kafka两个主题中:ods_base_log、ods_base_db
DWD-DIM
行为数据
存放位置:DWD(依赖于kafka)
做了什么工作
- 过滤藏数据--->使用测输出流技术,为了可以查看脏数据率指标
- 新老用户校验--->前台校验不准(新用户不准)
- 分流--->使用测输出流,分三个流(页面,启动,曝光),在离线数仓中,分5种数据流(页面,启动,曝光,动作日志,错误日志)
- 写入kafka系统。
业务数据
存放位置:DWD(依赖于kafka)、DIM(Phoenix/Hbase/Hdfs)
做了什么工作
过滤数据---> 过滤删除的数据,生产过程中,通常不是真正的删除,而是逻辑上的删除,也就是打一个标记。
读取配置表创建广播流
链接主流和广播流并处理
- 广播流数据:
- 解析数据
- Phoenix建表
- 写入状态广播
- 主流数据
- 读取数据
- 过滤字段
- 分流(添加sunkTable字段,方便后续处理)
- 广播流数据:
提取kafka和HBase流分别对应的位置
Hbase流:自定义sink
kafka流:自定义序列化方式
在本层中实现的类说明
BaseLogApp
- 消费 ods_base_log 主题数据创建流
- 将每行数据转换为JSON对象
- 新老用户校验 状态编程
- 分流 侧输出流 页面:主流 启动:侧输出流 曝光:侧输出流
- 提取测输出流数据,也就是脏数据,可以计算脏数据率。
- 将三个流进行打印并输出到对应的Kafka主题中
BaseDbApp
1、消费Kafka ods_base_db 主题数据创建流。
2、将每行数据转换为JSON对象并过滤(delete) 主流。
3、使用FlinkCDC消费配置表并处理成广播流。
4、连接主流和广播流。
5、分流处理数据,广播流数据,主流数据(根据广播流数据进行处理)。
6、提取Kafka流数据和HBase流数据。
7、将Kafka数据写入Kafka主题,将HBase数据写入Phoenix表。
TableProcess
封装了配置表属性信息
GmallConfig
封装Hbase数据库的一些配置信息。
DimSinkFunction
封装写入Hbase数据库的操作
TableProcessFunction
实现分流操作。
贡献者
 codingLab
codingLab版权所有
版权归属:
许可证: