3、SparkSql概述
概述
数据分析方式
命令式
sc.textFile("...")
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
.collect()命令式的优点
- 操作粒度更细,能够控制数据的每一个处理环节
- 操作更明确,步骤更清晰,容易维护
- 支持半/非结构化数据的操作
命令式的缺点
- 需要一定的代码功底
- 写起来比较麻烦
简单来说命令式就是借助了函数式编程的思想。
SQL
对于一些数据科学家/数据库管理员/DBA, 要求他们为了做一个非常简单的查询, 写一大堆代码, 明显是一件非常残忍的事情, 所以SQL on Hadoop 是一个非常重要的方向.
SELECT
name,
age,
school
FROM students
WHERE age > 10SQL的优点
- 表达非常清晰, 比如说这段 SQL 明显就是为了查询三个字段,条件是查询年龄大于 10 岁的
SQL的缺点
- 试想一下3层嵌套的 SQL维护起来应该挺力不从心的吧
- 试想一下如果使用SQL来实现机器学习算法也挺为难的吧
小结
- SQL 擅长数据分析和通过简单的语法表示查询,命令式操作适合过程式处理和算法性的处理.
- 在 Spark 出现之前,对于结构化数据的查询和处理, 一个工具一向只能支持命令式如MR或者只能使用SQL如Hive,开发者被迫要使用多个工具来适应两种场景,并且多个工具配合起来比较费劲.
- 而 Spark 出现了以后,提供了两种数据处理范式:RDD的命令式和SparkSQL的SQL式,是一种革新性的进步!
Spark Sql历史
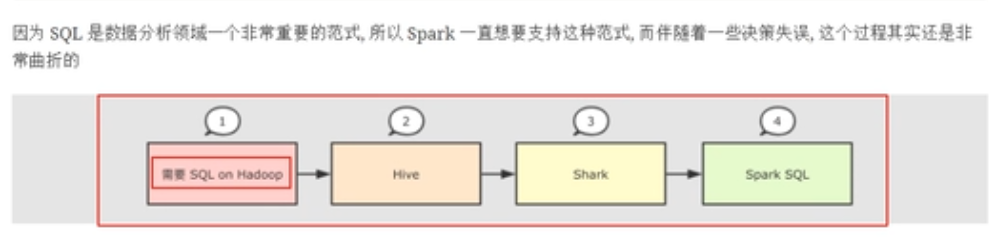
Hive

Hive延迟太高,因为其底层式基于MapReduce计算框架。
Hive是基于进程并行的,因为MapReduce是基于进程并行执行,spark是基于线程并行执行。
Shark
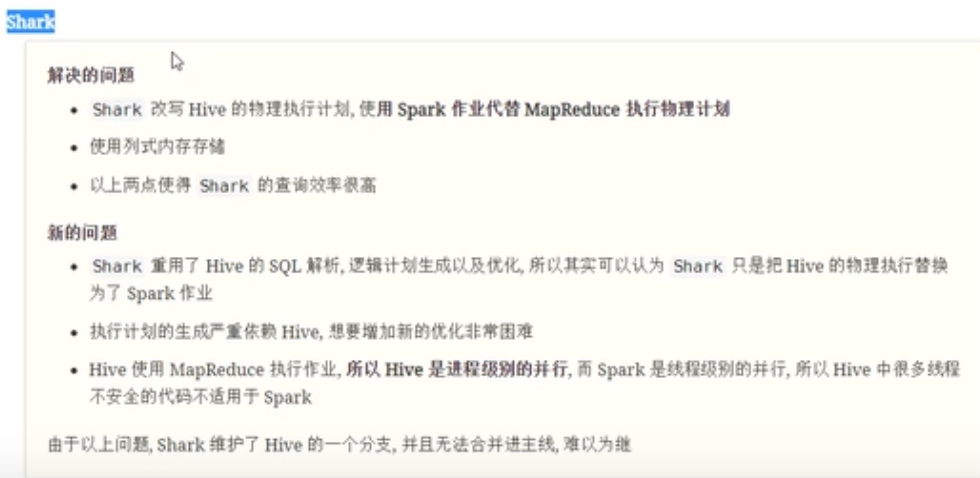
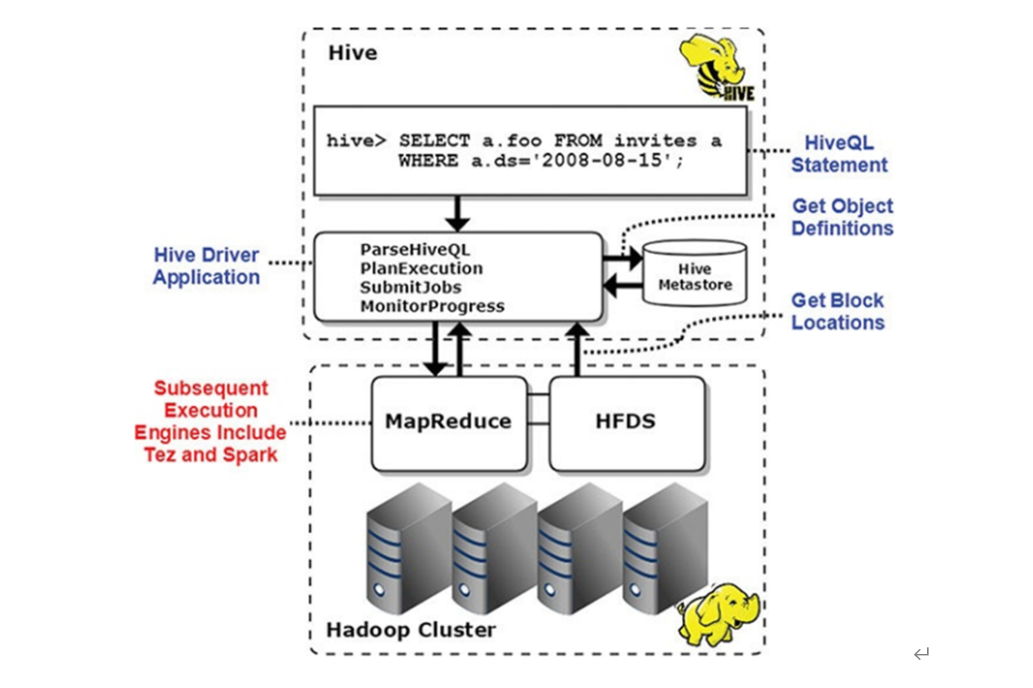
可以发现Hive框架底层就是MapReduce,所以在Hive中执行SQL时,往往很慢很慢。
Spark SQL的前身是Shark,它发布时Hive可以说是SQL on Hadoop的唯一选择(Hive负责将SQL编译成可扩展的MapReduce作业),鉴于Hive的性能以及与Spark的兼容,Shark由此而生。Shark即Hive on Spark,本质上是通过Hive的HQL进行解析,把HQL翻译成Spark上对应的RDD操作,然后通过Hive的Metadata获取数据库里表的信息,实际为HDFS上的数据和文件,最后有Shark获取并放到Spark上计算。 但是Shark框架更多是对Hive的改造,替换了Hive的物理执行引擎,使之有一个较快的处理速度。然而不容忽视的是Shark继承了大量的Hive代码,因此给优化和维护带来大量的麻烦。为了更好的发展,Databricks在2014年7月1日Spark Summit上宣布终止对Shark的开发,将重点放到SparkSQL模块上。
Spark sql

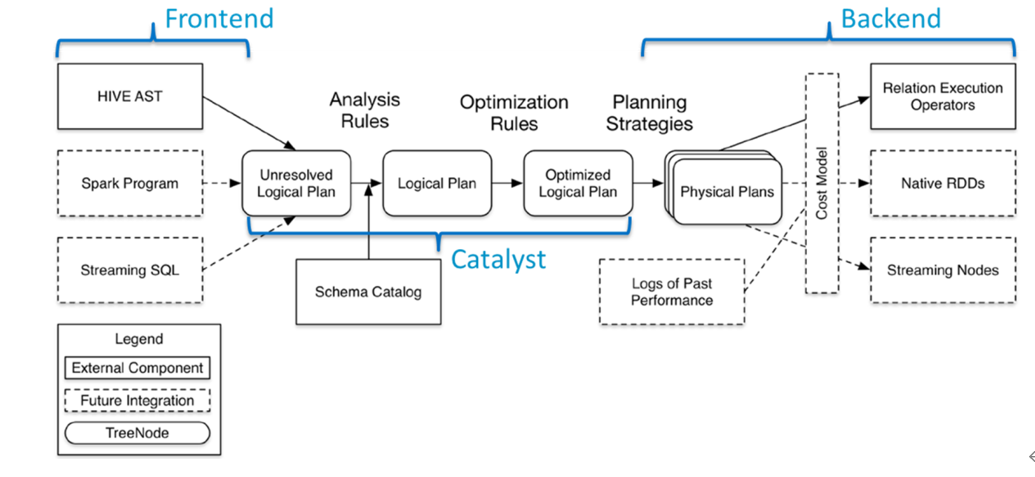
SparkSQL模块主要将以前依赖Hive框架代码实现的功能自己实现,称为Catalyst引擎。
DataSet

现在spark sql不仅支持命令式api,还支持声明式api操作。
Spark sql的重要性
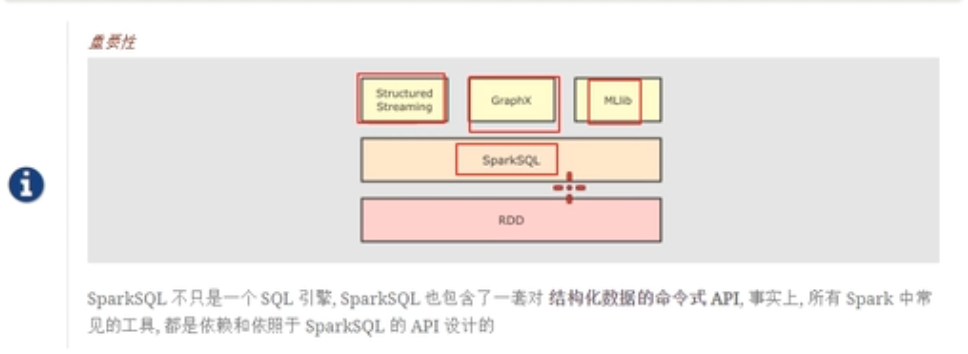
可以看到,spark streaming,Graphs和MLIBS都是基于spark sql的api进行实现的。spark sql底层是RDD。
Spark sql的应用场景
数据集的分类
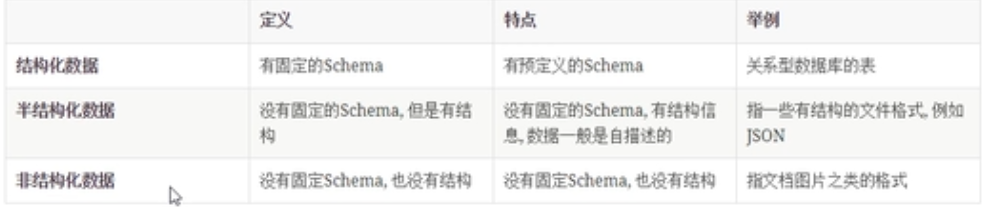
结构化数据
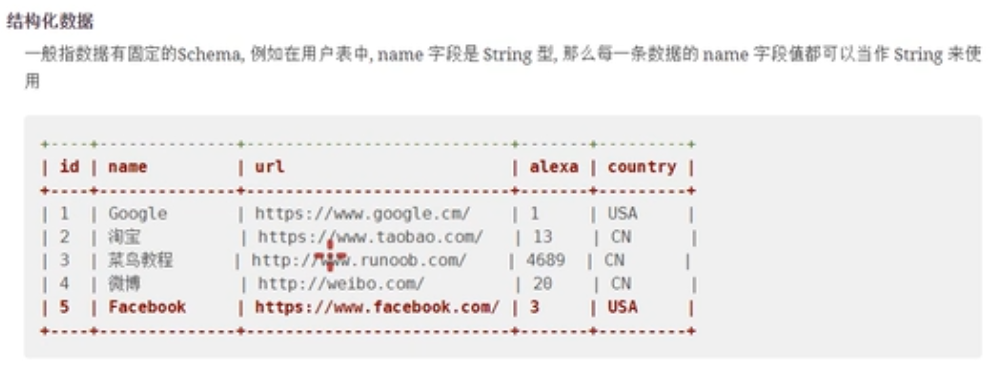
- 字段有约束
- 字段类型也有约束
特指关系数据库中的表
半结构化数据

- 有列
- 列有类型
- 但是没有严格的约束,可以任意的修改

非结构化数据
音频视频数据都是非结构化的数据,没有固定的格式和约束。
Spark Sql
spark sql用于处理什么类型的数据?

虽然Spark sql是基于RDD的,但是SparkSql的速度比RDD快很多。spark sql在编写的时候可以通过更方便的结构化的api来进行更好的操作。
SparkSql主要用于处理结构化数据

sparksession
- 因为老的sparkcontext已经不适用于sparksql,读取数据没有结构信息。
- sparksql需要读取更多的数据源,更多的数据写入。
DataFrame&Dataset
就易用性而言,对比传统的MapReduce API,Spark的RDD API有了数量级的飞跃并不为过。然而,对于没有MapReduce和函数式编程经验的新手来说,RDD API仍然存在着一定的门槛。
另一方面,数据科学家们所熟悉的R、Pandas等传统数据框架虽然提供了直观的API,却局限于单机处理,无法胜任大数据场景。
为了解决这一矛盾,Spark SQL 1.3在Spark1.0原有SchemaRDD的基础上提供了与R和Pandas风格类似的DataFrame API。
新的DataFrame AP不仅可以大幅度降低普通开发者的学习门槛,同时还支持Scala、Java与Python三种语言。更重要的是,由于脱胎自SchemaRDD,DataFrame天然适用于分布式大数据场景。
DataFrame是什么

在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。
DataFrame与RDD的主要区别在于,前者带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。
注意:
DataFrame它不是Spark SQL提出来的,而是早在R、Pandas语言中就已经有了的。
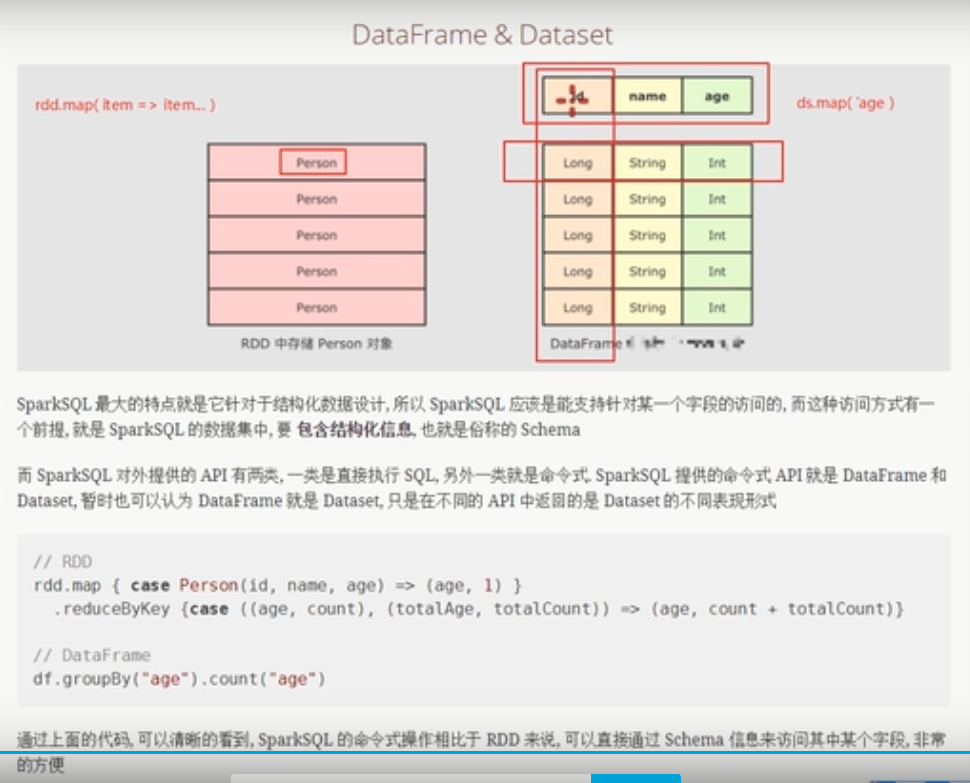
rdd中存储的对象,只能把person当做一个整体来看待,无法操作对象的属性信息,但是对于dataset和dataframe来说,可以直接操作Person中的某一个属性信息。
命令式API使用
object Test01 {
def main(args: Array[String]): Unit = {
//构建者模式
//Create SparkConf() And Set AppName
val spark= SparkSession.builder()
.appName("Spark Sql basic example")
.config("spark.some.config.option", "some-value")
.master("local[6]")
.getOrCreate()
val ss= SparkSession.builder()
.appName("Spark Sql basic example")
.config("spark.some.config.option", "some-value")
.master("local[6]")
.getOrCreate()
//导入隐式转换
import spark.implicits._
//import ss.implicits._
// 通过SparkSession对象使用sparkcontext对象
val sourceRDD: RDD[Person] = spark.sparkContext.parallelize(Seq(Person("zhangsan", 12), Person("lisi", 24)))
//toDS()是一个隐式转换,其实就是一个dataSet对象
val personDs: Dataset[Person] = sourceRDD.toDS()
val value: Dataset[String] = personDs.where('age > 10)
.where('age < 20)
.select('name)//可以拿到某一列
.as[String]
value.show()
}
case class Person(name:String,age: Int)
}声明式api的使用
也就是使用sql语句查询
object Test02 {
def main(args: Array[String]): Unit = {
//构建者模式
//Create SparkConf() And Set AppName
val spark= SparkSession.builder()
.appName("Spark Sql basic example")
.config("spark.some.config.option", "some-value")
.master("local[6]")
.getOrCreate()
//导入隐式转换
import spark.implicits._
// 通过SparkSession对象使用sparkcontext对象
val sourceRDD: RDD[Person] = spark.sparkContext.parallelize(Seq(Person("zhangsan", 12), Person("lisi", 24)))
//toDS()是一个隐式转换,其实就是一个dataSet对象
val dsData: Dataset[Person] = sourceRDD.toDS()
val dfData: DataFrame = sourceRDD.toDF()
//首先创建一个临时表
dfData.createOrReplaceTempView("personTemp")
val res: DataFrame = spark.sql("select * from personTemp where age >10 and age < 20")
res.show()
}
case class Person(name:String,age: Int)
}
下面图说明RDD,Dataset和DataFrame三者的结构
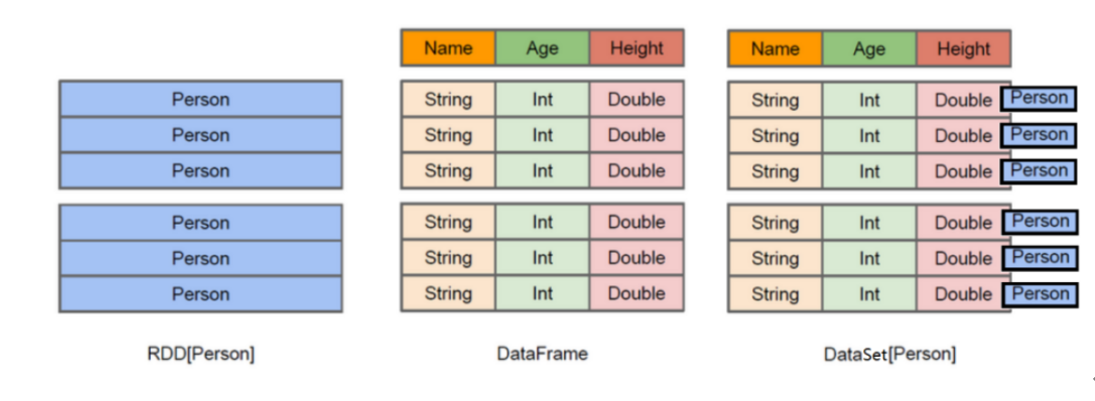
上图中左侧的RDD[Person]虽然以Person为类型参数,但Spark框架本身不了解Person类的内部结构。
而中间的DataFrame却提供了详细的结构信息,使得Spark SQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。了解了这些信息之后,Spark SQL的查询优化器就可以进行针对性的优化。后者由于在编译期有详尽的类型信息,编译期就可以编译出更加有针对性、更加优化的可执行代码。
Schema 信息
查看DataFrame中Schema是什么,执行如下命令:
df.schema
//我们可以看到,schema是StructType类型,schema定义在Row中
def schema: StructType = nullSchema信息封装在StructType中,包含很多StructField对象
spark提供了sql和命令式api两种不同的方式访问结构化数据,并且他们之间可以无缝衔接
Catasyst优化器
什么是catasyst优化器

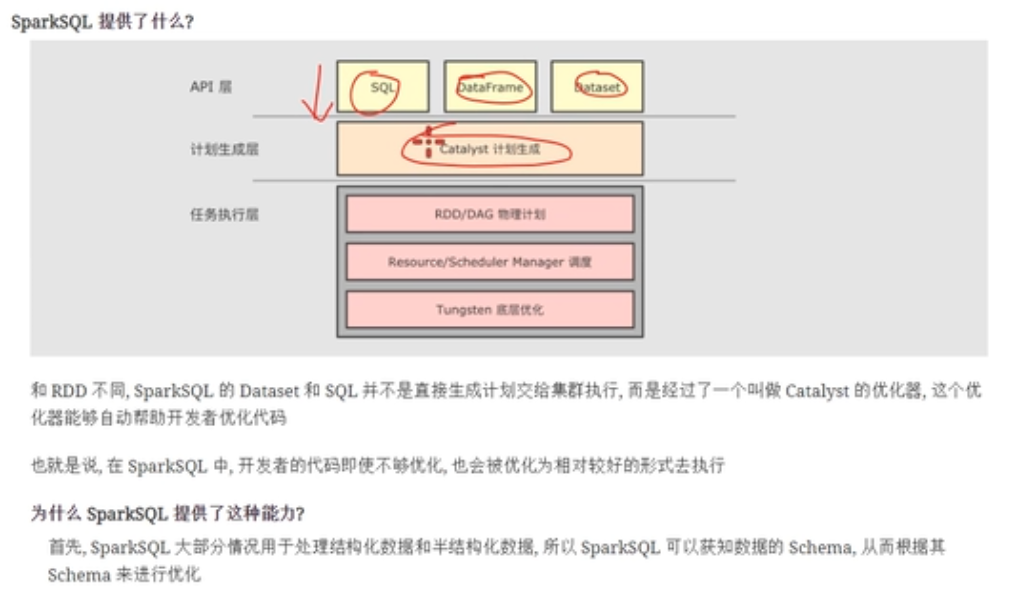
catasyst的优化步骤
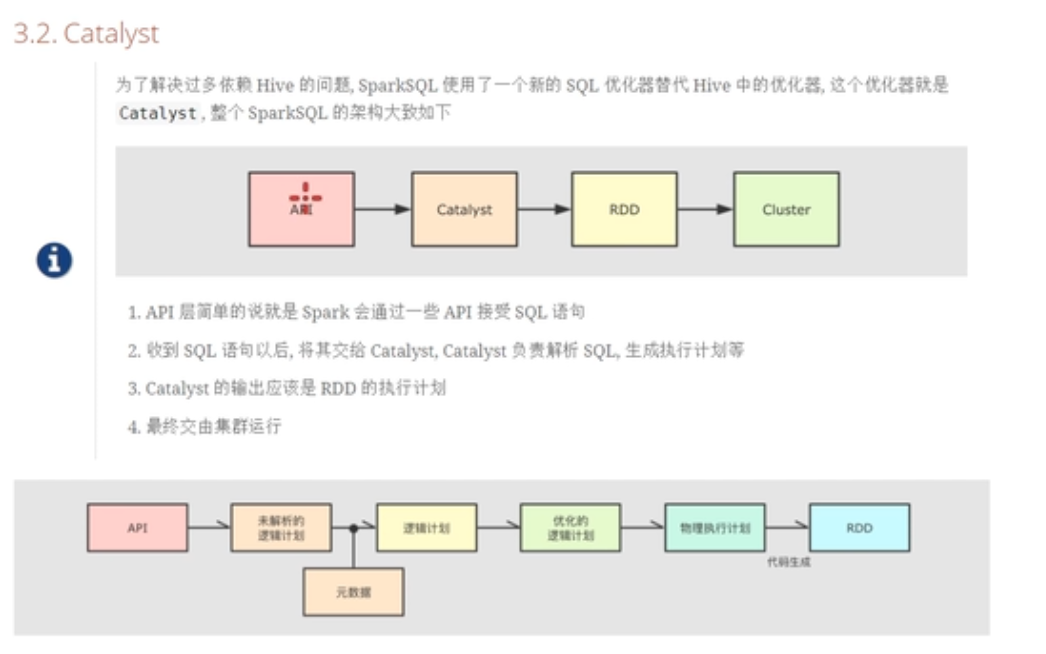
执行计划的生成经过四个阶段:解析,优化,生成物理计划,运行,
- 解析:将用户的代码解析为语法树
- 优化:按照一定的优化规则对语法树进行优化
- 生成物理计划,在这之前生成的计划都是逻辑计划,没办法直接执行,需要转换为物理计划。
- 提交到集群执行
第一步
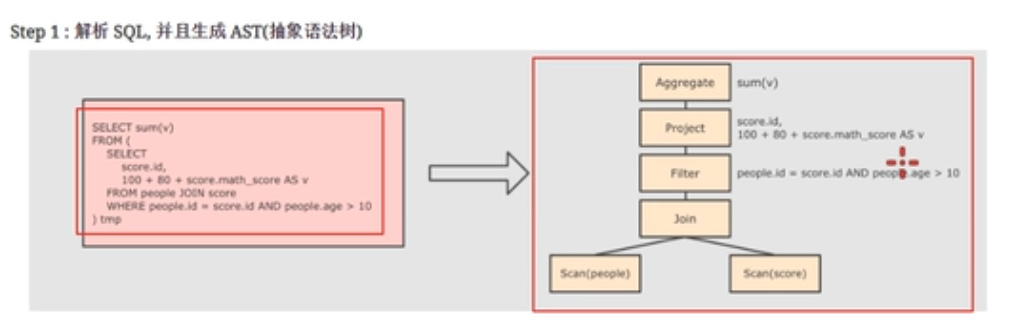
不管什么语言,编译器在进行编译的时候,首先是进行解析工作,解析为语法树。
第二步
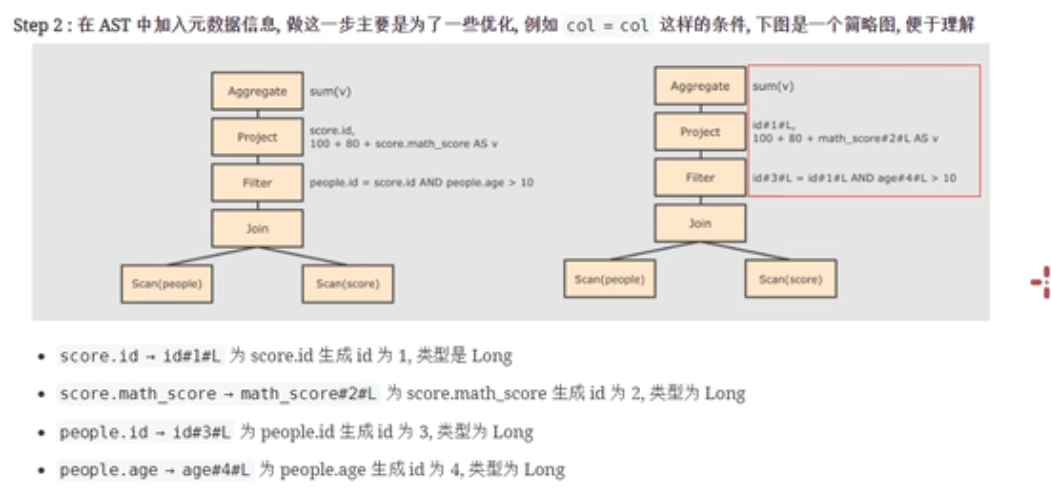
生成元数据信息,也就是给相应的数据添加类型信息,进行数据类型的绑定和函数的绑定。
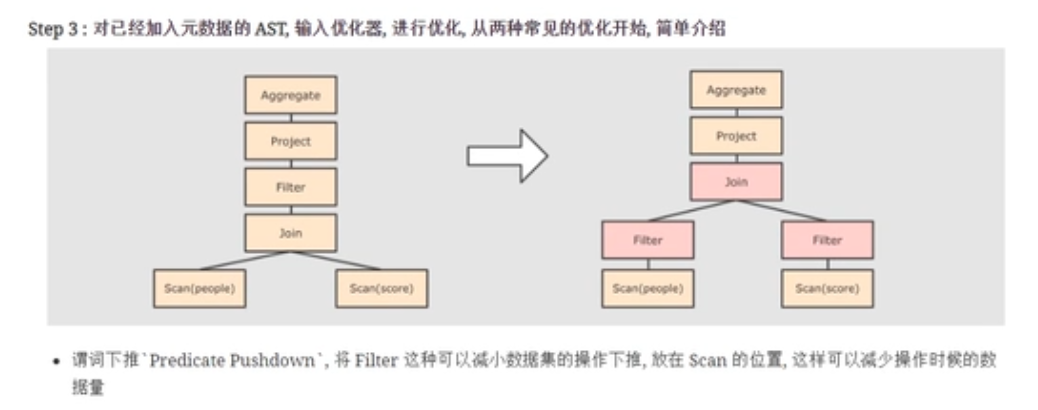
第三步
优化,按照一定的规则进行优化
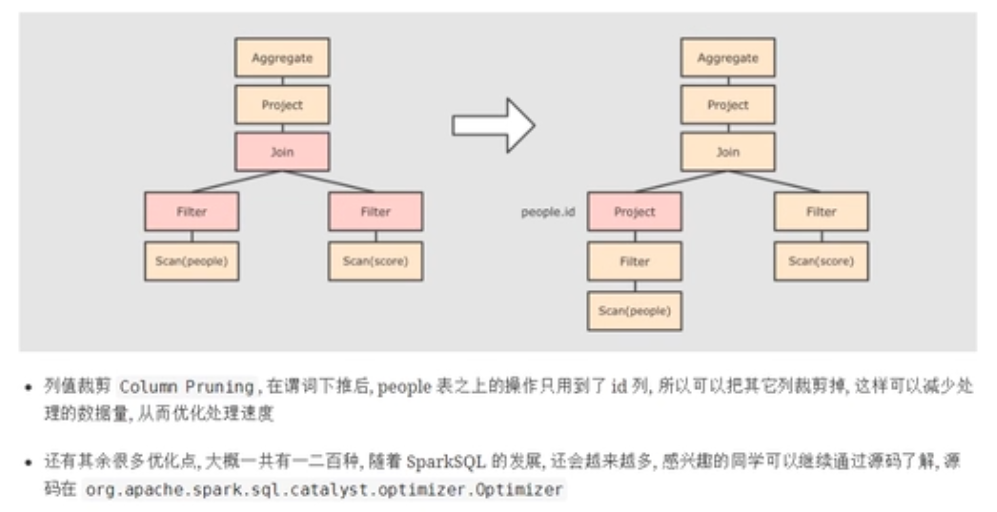
第四步

整个过程中,会生成多个物理计划,最终通过成本模型选择一个最优的物理计划执行。
查看逻辑执行计划
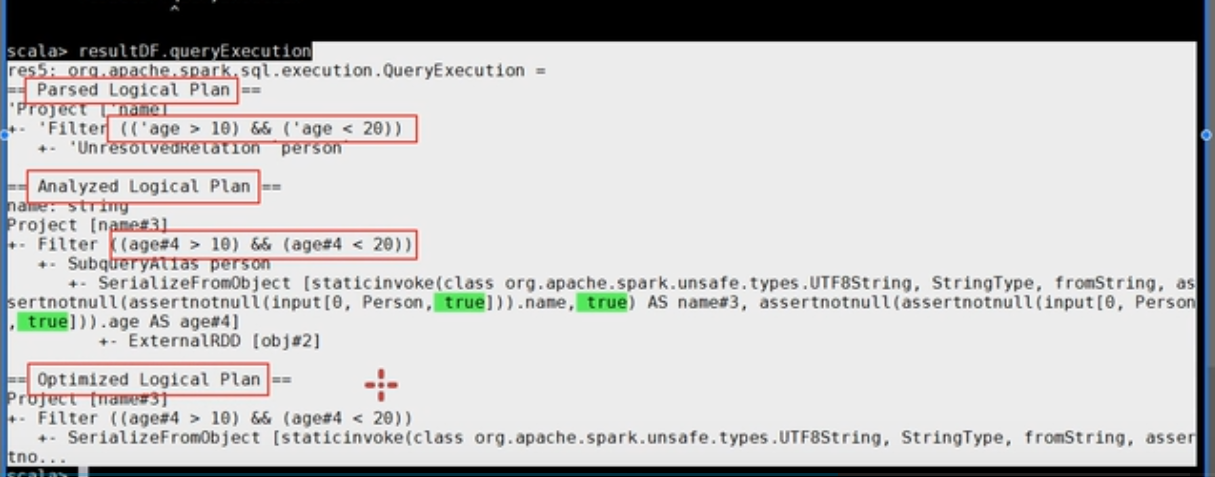
查看物理执行计划

贡献者
 codingLab
codingLab版权所有
版权归属:
许可证: