8、SparkSql整合Hive和Jdbc
SpaqkSql整合Hive
概述
Spark SQL模块从发展来说,从Apache Hive框架而来,发展历程:Hive(MapReduce)-> Shark (Hive on Spark) -> Spark SQL(SchemaRDD -> DataFrame -> Dataset),
SparkSQL天然无缝集成Hive,可以加载Hive表数据进行分析。
HiveOnSpark和SparkOnHive
- HiveOnSpark:SparkSql诞生之前的Shark项目使用的,是把Hive的执行引擎换成Spark,剩下的使用Hive的,严重依赖Hive,早就淘汰了没有人用了
- SparkOnHive:SparkSQL诞生之后,Spark提出的,是仅仅使用Hive的元数据(库/表/字段/位置等信息...),剩下的用SparkSQL的,如:执行引擎,语法解析,物理执行计划,SQL优化
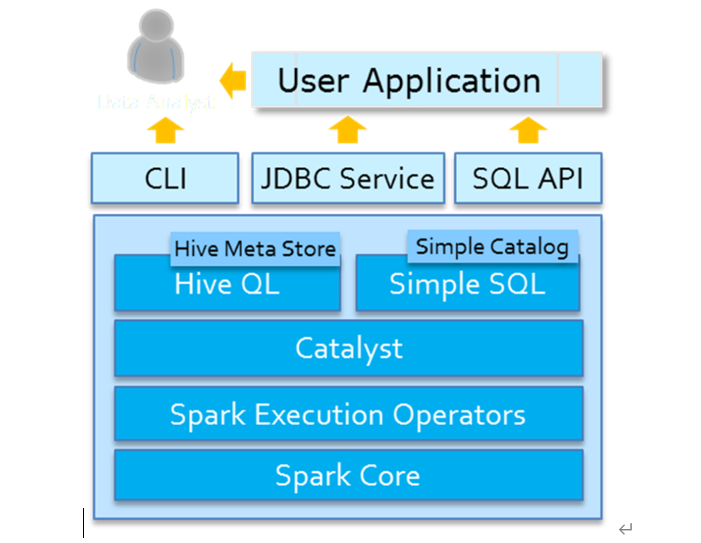
spark-sql中集成Hive
和文件的格式不同,Hive是一个外部的数据存储和查询引擎,所以说如果Spark需要访问Hive的话,就需要先整合HIve。
SparkSQL集成Hive本质就是:SparkSQL读取Hive的元数据MetaStore

配置SparksQL到HIve
拷贝hive-site.xml 到spark的conf目录下面。
拷贝hdfs的配置文件到spark。
[rzf@hadoop100 hadoop]$ cp core-site.xml /opt/module/spark/conf/
[rzf@hadoop100 hadoop]$ cp hdfs-site.xml /opt/module/spark/conf/- 启动Hive的元数据库服务
hive所在机器hadoop100上启动
nohup /export/server/hive/bin/hive --service metastore &注意:Spark3.0需要Hive2.3.7版本
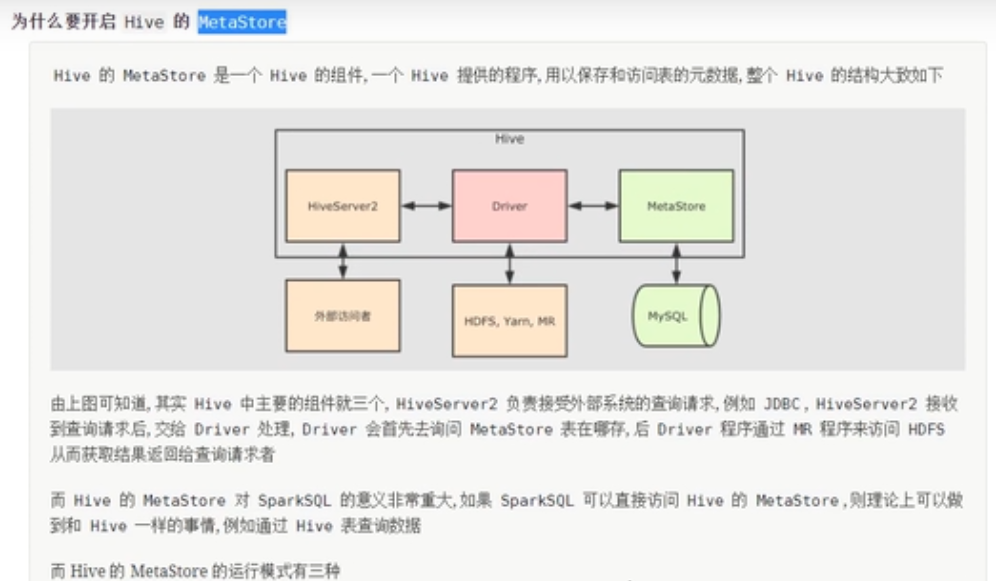
- 告诉SparkSQL:Hive的元数据库在哪里
哪一台机器需要使用spark-sql命令行整合,hive就把下面的配置放在哪一台
也可以将hive-site.xml分发到集群中所有Spark的conf目录,此时任意机器启动应用都可以访问Hive表数据。
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop100:3306/metastore?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
<description>
Enforce metastore schema version consistency.
True: Verify that version information stored in is compatible with one from Hive jars. Also disable automatic
schema migration attempt. Users are required to manually migrate schema after Hive upgrade which ensures
proper metastore schema migration. (Default)
False: Warn if the version information stored in metastore doesn't match with one from in Hive jars.
</description>
<property>
<name>datanucleus.readOnlyDatastore</name>
<value>false</value>
</property>
<property>
<name>datanucleus.fixedDatastore</name>
<value>false</value>
</property>
<property>
<name>datanucleus.autoCreateSchema</name>
<value>true</value>
</property>
<property>
<name>datanucleus.autoCreateTables</name>
<value>true</value>
</property>
<property>
<name>datanucleus.autoCreateColumns</name>
<value>true</value>
</property>
</property>
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
"hive-site.xml" 94L, 2379C 已写入
Enter password:
<name>datanucleus.readOnlyDatastore</name>
<value>false</value>
</property>
<property>
<name>datanucleus.fixedDatastore</name>
<value>false</value>
</property>
<property>
<name>datanucleus.autoCreateSchema</name>
<value>true</value>
</property>
<property>
<name>datanucleus.autoCreateTables</name>
<value>true</value>
</property>
<property>
<name>datanucleus.autoCreateColumns</name>
<value>true</value>
</property>
</property>
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
//配置matastore占用哪一个ip地址
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop100:9083</value>
</property>
//开启metaStore进程
[rzf@hadoop100 hive]$ nohup /opt/module/hive/bin/hive --service metastore 2>&1 >> /opt/module/hive/logs/log.log &SparkSql访问Hive表
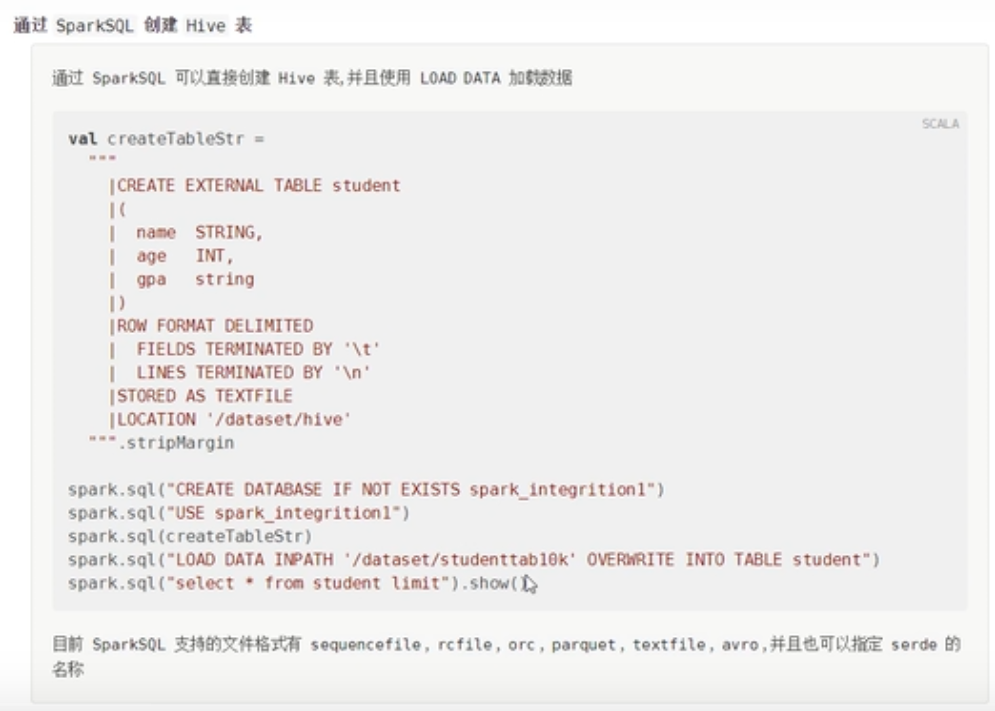
使用Hive创建表
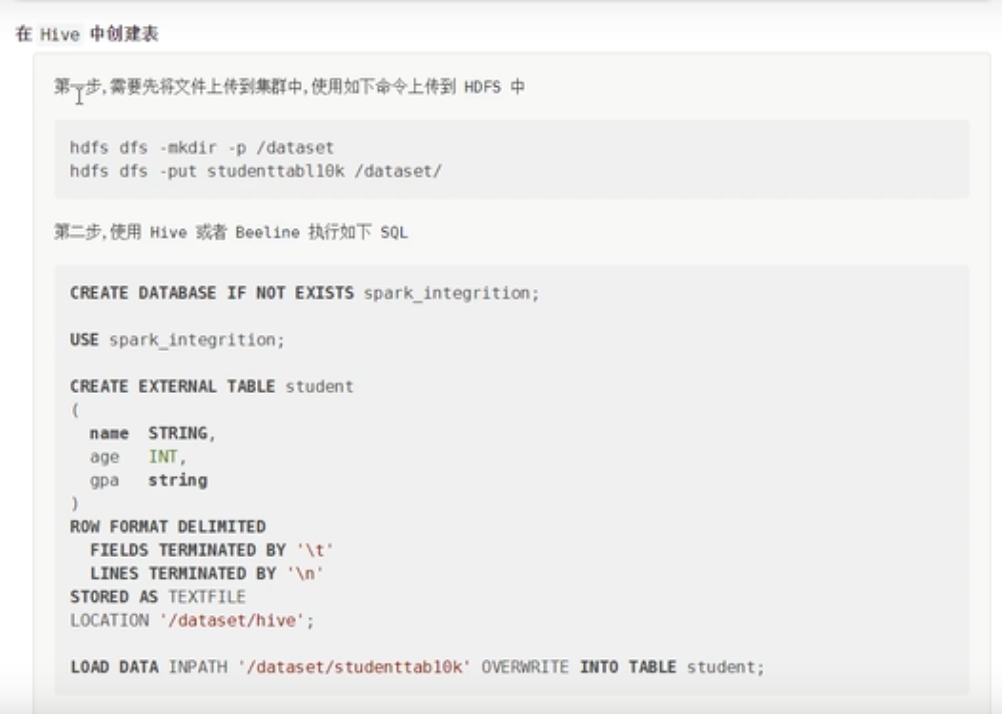
创建表
create external table stu
(name STRING,
age INT,
sex STRING)
row format delimited fields terminated by '\t'
lines terminated by '\n'
STORED as TEXTFILE;
//加载数据
LOAD DATA INPATH '/dataset/stud' overwrite into table stu;访问表
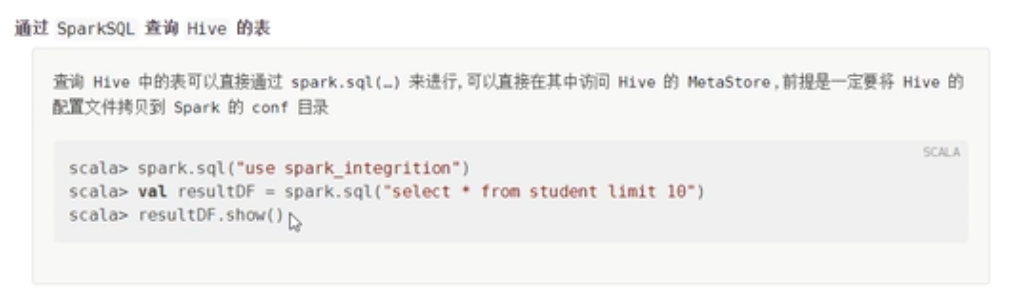
案例
spark.sql("use table")
val res=spark.sql("select * from student limit 10")
res.show()使用SparkSql创建表
SparkSql访问Hive
编写程序打成jar包放到集群中运行程序。
添加依赖
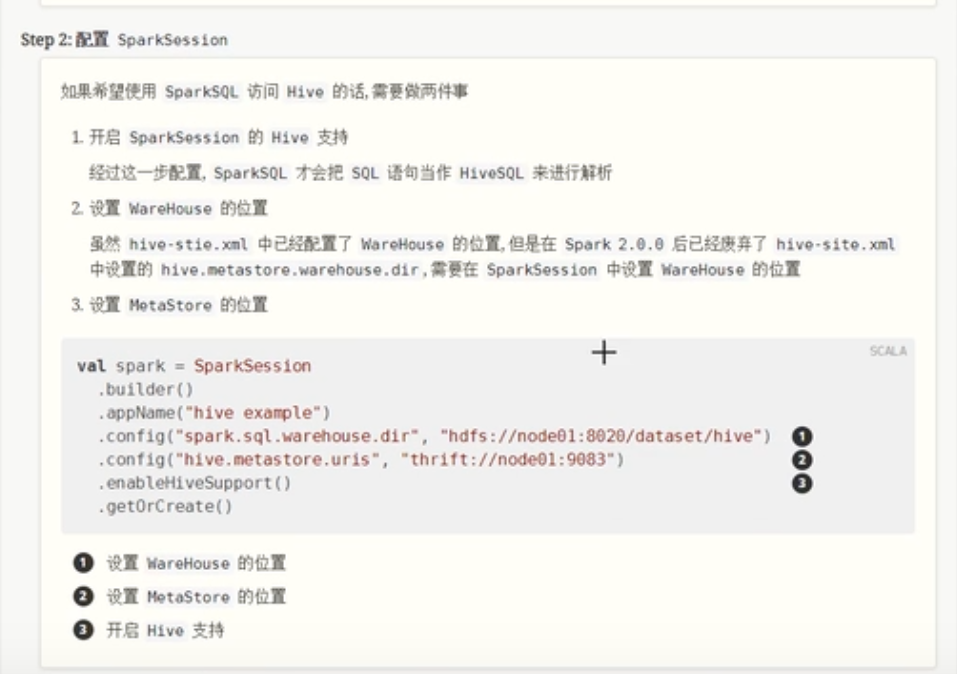
配置SparkSession
独立的spark程序
object HiveAccess {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder()
.appName("hive exam")
.config("spqrk.sql.warehouse.dir", "hdfs://hadoop100:9000/dataset/hive") //指定warehouse位置
.config("hive.metastore.uirs", "thrift://hadoop100:9083") //指定metastore的位置
.enableHiveSupport() //默认使用的是sparksql,需要但是这里使用的是hive,所以要支持hiveContext
.getOrCreate()
// 因为是放在集群中执行,所以不需要指定master
// 编些逻辑代码
// 1 读取数据,因为是要在集群中执行,没有办法保证程序在哪一台机器上执行,所以需要把程序上传到所有的机器上面,才可以读取本地文件
// 把文件上传到hdfs上面,这样所有的机器都可以读取到数据,他是一个外部系统
// 2 使用df读取数据
import spark.implicits._
//定义schema类型,类型是StructType
val schema: StructType = StructType(
//列表里面定义的是列的类型信息
List(
StructField("name",StringType),
StructField("age",IntegerType),
StructField("sex",StringType)
)
)
val df: DataFrame = spark.read
.option("delimiter", "\t") //数据的分隔符
.schema(schema)
.csv("hdfs///dataset/stud")
// 对df进行查询
val resdf: Dataset[Row] = df.where('age > 23)
// 写入数据,
resdf.write.mode(SaveMode.Overwrite).saveAsTable("spark03")
}
}Hive的SQL交互方式
- 方式1:交互式命令行(CLI)
- bin/hive,编写SQL语句及DDL语句
- 方式2:启动服务HiveServer2(Hive ThriftServer2)
- 将Hive当做一个服务启动(类似MySQL数据库,启动一个服务),端口为10000
- 交互式命令行,bin/beeline,CDH 版本HIVE建议使用此种方式,CLI方式过时
- JDBC/ODBC方式,类似MySQL中JDBC/ODBC方式
SparkSQL交互方式
SparkSQL模块从Hive框架衍生发展而来,所以Hive提供的所有功能(数据分析交互式方式)都支持
- 方式1: 上一章节已经学习了
- SparkSQL命令行或SparkSQL代码中访问
- 启动sparkSQL的thriftserver使用beeline或使用JDBC协议访问
补充 :sparksql的thriftserver
Spark Thrift Server将Spark Applicaiton当做一个服务运行,提供Beeline客户端和JDBC方式访问,与Hive中HiveServer2服务一样的。
在实际大数据分析项目中,使用SparkSQL时,往往启动一个ThriftServer服务,分配较多资源(Executor数目和内存、CPU),不同的用户启动beeline客户端连接,编写SQL语句分析数据。
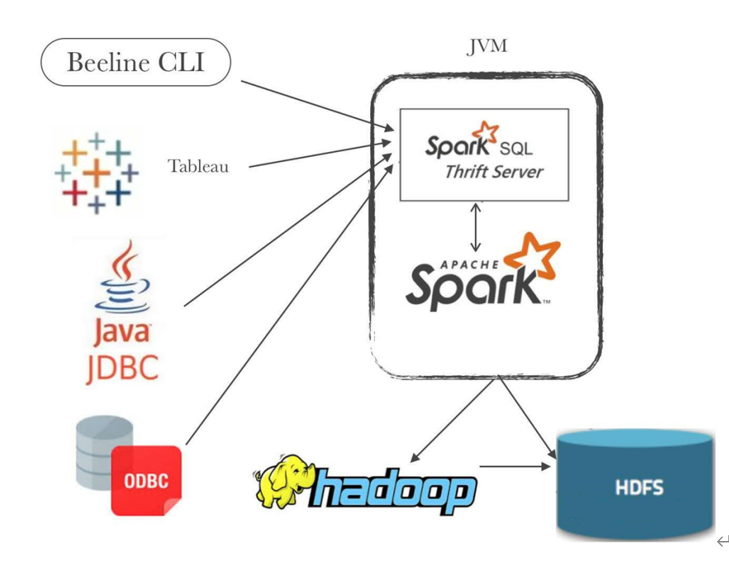
在$SPARK_HOME目录下的sbin目录,有相关的服务启动命令:
使用beeline 客户端连接
- 启动SaprkSQL的thriftserver--类似与Hive的HiveServer2
//在hadoop100节点上启动下面的服务
/export/server/spark/sbin/start-thriftserver.sh \
--hiveconf hive.server2.thrift.port=10000 \
--hiveconf hive.server2.thrift.bind.host=hadoop100 \
--master local[2]- 停止命令
/export/server/spark/sbin/stop-thriftserver.sh- 使用SparkSQL的beeline客户端命令行连接ThriftServer
/export/server/spark/bin/beeline
!connect jdbc:hive2://hadoop100:10000
root
123456- 查看web ui界面
http://hadoop100:4040/jobs/
SparkSql读写jdbc
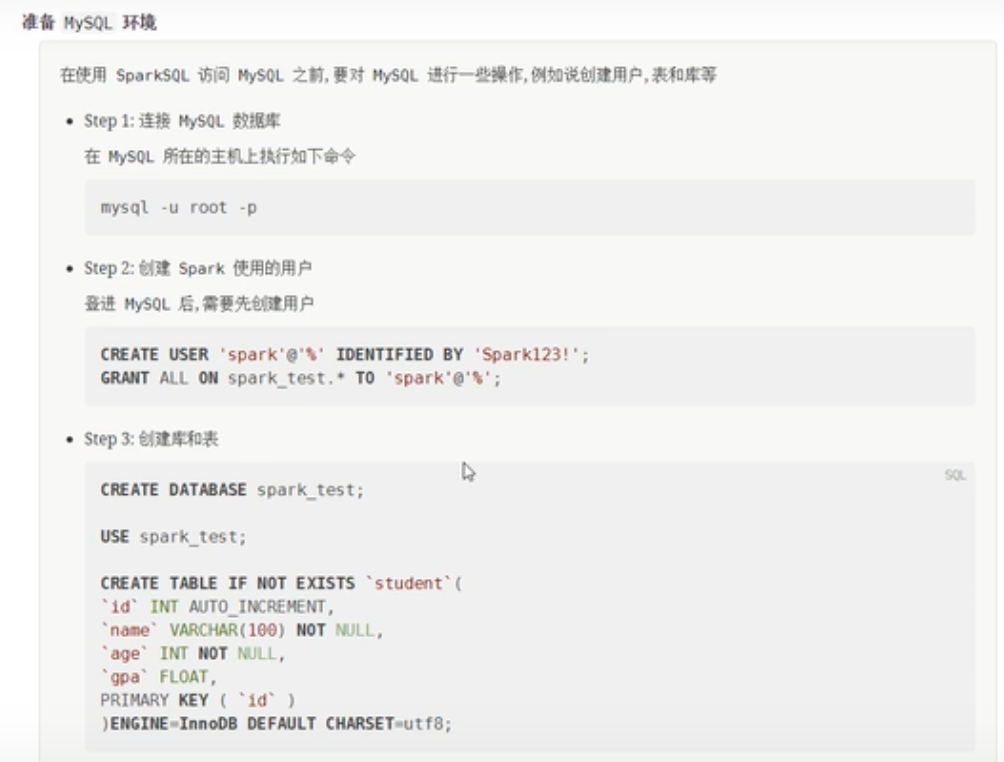
创建库和表
在mysql数据库上创建如下数据库和表。
向mysql中写入数据

添加mysql的驱动程序
//要正确读取数据,还需要添加mysql数据库的驱动程序
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql.connector-java</artifactId>
<version>5.1.47</version>
</dependency>写入数据
object MysqlWrite {
/**
* mysql的访问方式有两种,使用本地运行,提交到集群运行
* 在写入mysql数据的时候,使用本地运行的形式,读取的时候,使用集群的形式
*/
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder()
.appName("mysql exam")
.master("local[6]")
.getOrCreate()
import spark.implicits._
//定义schema类型,类型是StructType
val schema: StructType = StructType(
//列表里面定义的是列的类型信息
List(
StructField("name",StringType),
StructField("age",IntegerType),
StructField("sex",StringType)
)
)
//读取数据,创建df
val df: DataFrame = spark.read
.option("delimiter", "\t") //数据的分隔符
.schema(schema)
.csv("")
// 处理数据
val resdf: Dataset[Row] = df.where('age < 25)
// 落地数据
resdf.write
.format("jdbc")
.option("url","jdbc:mysql://hadoop100:3306/spark02")
.option("dbtable","stu")//指定数据库
.option("user","spark03")//指定用户名
.option("password","root")//指定密码
.mode(SaveMode.Overwrite)
.save()
}
}贡献者
 codingLab
codingLab版权所有
版权归属:
许可证: