6、SparkSql数据处理
数据操作
有类型的转换算子
map&flatMap&mapPartitions
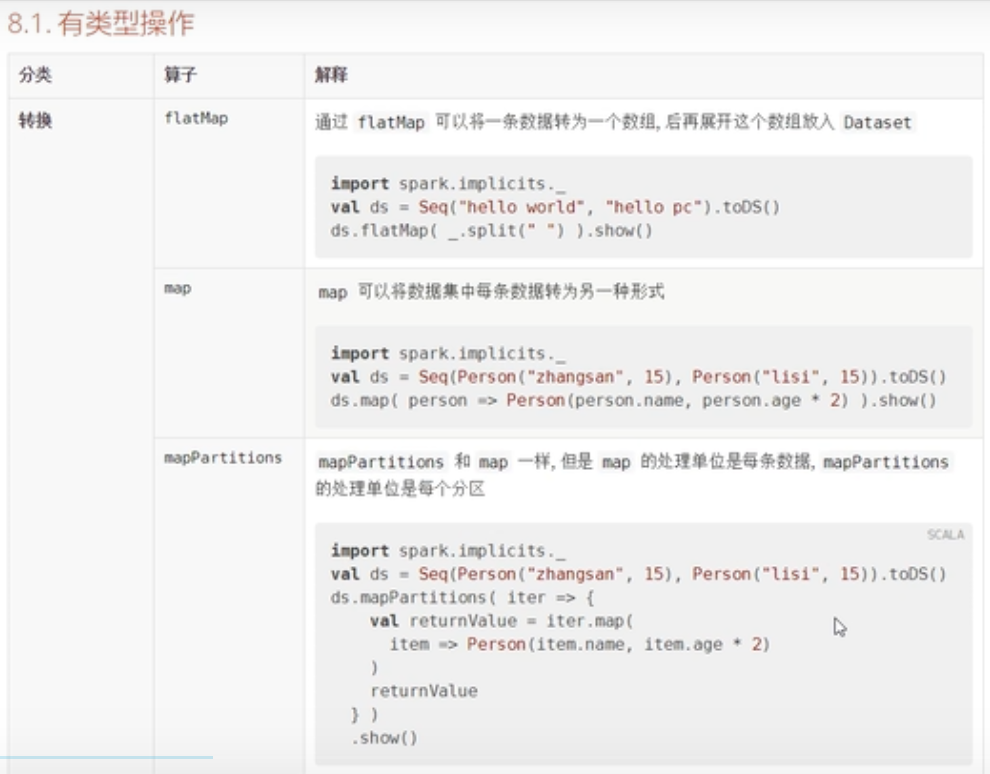
案例
object Test23 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[6]")
.appName("typed")
.getOrCreate()
import spark.implicits._
val ds: Dataset[String] = Seq("hello spark", "hello flink").toDS()
//1 flatMap算子操作
ds.flatMap(item => item.split(" ")).show()
//2 map算子操作
val ds1: Dataset[Person] = Seq(Person(1, "xiaomign", 24), Person(2, "xiaohong", 25)).toDS()
// 使用map算子做一个转换操作
ds1.map(person => Person(person.id,person.name,person.age*2)).show()
//3 mapPartitions
//mapPartitions算子作用于每一个分区,而map算子是作用于每一条数据,可以提高执行的效率
//如果一个分区的数据可以放进内存中,才可以进行mapPartitions操作,否则是不能进行mapPartitions操作的
ds1.mapPartitions(
//接受的是一个集合,但是这个集合不能超过内存的大小,否则就会发生内存溢出
//对每一个集合中的元素进行转换,然后生成一个新的集合
iter=>{
//这个map算子是scala中的算子
val res: Iterator[Person] = iter.map(person => Person(person.id, person.name, person.age * 2))
res
}
).show()
// 关闭资源
spark.stop()
}
case class Person(id:Int,name:String,age:Int)
}transform
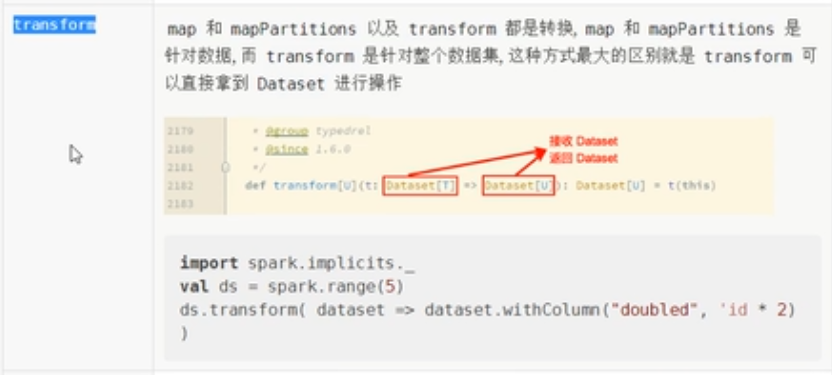
案例
object Test23 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[6]")
.appName("typed")
.getOrCreate()
import spark.implicits._
val data: Dataset[lang.Long] = spark.range(10)
//doubled是定义新的列的列明
data.transform(dataset => dataset.withColumn("doubled",'id*2)).show()
// 关闭资源
spark.stop()
}
}as

案例
object Test24 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[6]")
.appName("typed")
.getOrCreate()
import spark.implicits._
//定义schema类型,类型是StructType
val schema: StructType = StructType(
//列表里面定义的是列的类型信息
List(
StructField("name",StringType),
StructField("age",IntegerType),
StructField("sex",StringType)
)
)
//把类型给为Dataset,里面存放的是Row类型
//val df: Dataset[Row] = spark.read
val df: DataFrame= spark.read
.option("delimiter", "\t") //数据的分隔符
.schema(schema)
.csv("")
/**
* 下面的转换,本质上进行的是:DataSet[Row].as[Student]==>DataSet[Student]的转换
*/
//转换,把df通过as 转换为另一种类型
val ds: Dataset[Student] = df.as[Student]
spark.stop()
}
case class Student(name:String,age:Int)
}Filter

对数据进行过滤操作
object Test25 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[6]")
.appName("typed")
.getOrCreate()
import spark.implicits._
val ds: Dataset[Student] = Seq(Student("ziaorui", 25), Student("xiaoming",15)).toDS()
ds.filter(person => person.age>20).show()
spark.stop()
}
case class Student(name:String,age:Int)
}groupByKey
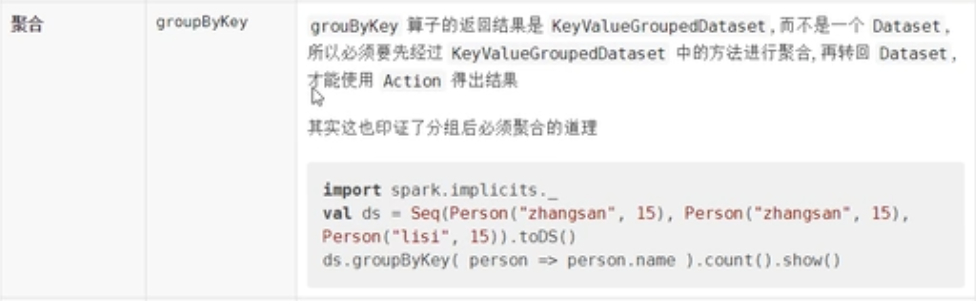
案例
object Test26 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[6]")
.appName("typed")
.getOrCreate()
import spark.implicits._
val ds: Dataset[Student] = Seq(Student("ziaorui", 25), Student("xiaoming",15),Student("lisi", 35)).toDS()
//算子里面的函数返回key信息,
val grouped: KeyValueGroupedDataset[String, Student] = ds.groupByKey(person => person.name)
//通过count()方法,返回的是Dataset类型,这里通过grouped的聚合方法,将其转换为DataSet类型
val res: Dataset[(String, Long)] = grouped.count()
res.show()
spark.stop()
}
case class Student(name:String,age:Int)
}randomSplit
如何将一个数据集切分为多个数据集,如何从一个数据集中抽出一个比较小的数据集
案例
object Test27 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[6]")
.appName("typed")
.getOrCreate()
import spark.implicits._
val ds: Dataset[lang.Long] = spark.range(15)
//randomSplit 切多少分,权重是多少
//切分为3分,因为数组中传入了3个权重信息,数组中的权重并不代表数据的数目,依然采用随机分配数据,并不是按照严格的比例分配
val array: Array[Dataset[lang.Long]] = ds.randomSplit(Array(5, 2, 3))
array.foreach(_.show())
//采样数据,withReplacement表示有放回的抽样,采样比例是0.4
ds.sample(withReplacement=false,fraction = 0.4)
spark.stop()
}
case class Student(name:String,age:Int)
}OrderBy&sort
案例
object Test28 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[6]")
.appName("typed")
.getOrCreate()
import spark.implicits._
val ds: Dataset[Student] = Seq(Student("ziaorui", 25), Student("xiaoming",15),Student("lisi", 35)).toDS()
//ds.orderBy("age")
//默认是按照升序排列
ds.orderBy('age.desc).show()//使用orderBy就是为了配合sql语句
//使用sort算子
ds.sort('age).show()
spark.stop()
}
case class Student(name:String,age:Int)
}distinct&dropDuplicates
案例
object Test29 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[6]")
.appName("typed")
.getOrCreate()
import spark.implicits._
val ds: Dataset[Student] = Seq(Student("ziaorui", 25), Student("xiaoming",15),Student("zhangsan", 35),Student("lisi", 35),Student("lisi", 35)).toDS()
ds.distinct().show()
//针对某一个列进行去重操作
ds.dropDuplicates("age").show()
spark.stop()
}
case class Student(name:String,age:Int)
}集合操作
object Test30 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[6]")
.appName("typed")
.getOrCreate()
import spark.implicits._
//定义两个集合
val coll1: Dataset[lang.Long] = spark.range(1, 10)
val coll2: Dataset[lang.Long] = spark.range(5, 15)
//计算差集
coll1.except(coll2).show()
//计算交集
coll1.intersect(coll2).show()
//计算并集
coll1.union(coll2).show()
//limit()的使用
coll1.limit(3).show()
spark.stop()
}
case class Student(name:String,age:Int)
}无类型的转换算子
选择
object Test31 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[6]")
.appName("typed")
.getOrCreate()
import spark.implicits._
val ds: Dataset[Student] = Seq(Student("ziaorui", 25), Student("xiaoming",15),Student("lisi", 35)).toDS()
//选中某一列进行输出,在dataset当中,select可以在任何的位置调用
ds.select('name).show()
//表达式的写法,计算年龄的累加和
ds.selectExpr("count(age)").show()
import org.apache.spark.sql.functions._
//使用函数的方式调用
ds.select(expr("sum(age)")).show()
spark.stop()
}
case class Student(name:String,age:Int)
}新建列
object Test32 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[6]")
.appName("typed")
.getOrCreate()
import spark.implicits._
val ds: Dataset[Student] = Seq(Student("ziaorui", 25), Student("xiaoming",15),Student("lisi", 35)).toDS()
import org.apache.spark.sql.functions._
/**
* 如果想使用函数功能
* 1 使用functions.xxx的形式
* 2 使用表达式,可以使用expr("xxx")形式,随时就可以编写
*/
//新添加一列,值是后面的表达式,产生随机值
ds.withColumn("random",expr("rand()")).show()
//对某一列进行重新命名,但是是重新创建一列,列的内容使用的是name列的内容,
ds.withColumn("name_new",'name).show()
//创建列的时候,也可以对列进行操作
ds.withColumn("name_new1",'name+" ").show()
//给列重新命名
ds.withColumnRenamed("name","joy_name").show()
spark.stop()
}
case class Student(name:String,age:Int)
}剪除&聚合
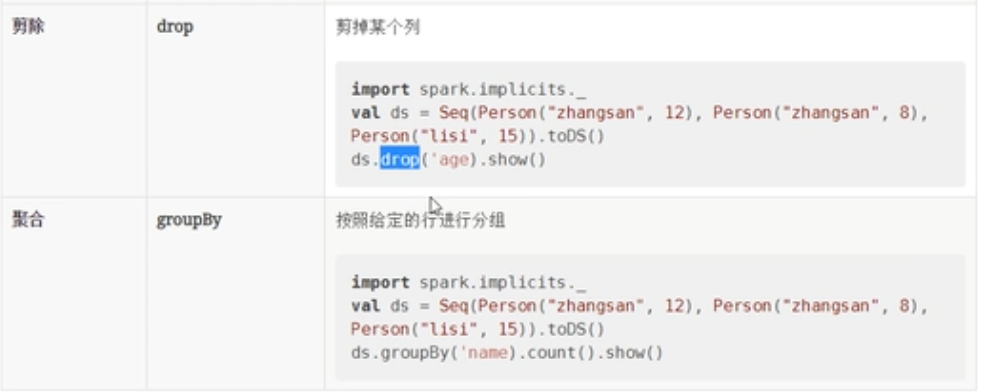
案例
object Test33 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[6]")
.appName("typed")
.getOrCreate()
import spark.implicits._
val ds: Dataset[Student] = Seq(Student("ziaorui", 25), Student("xiaoming",15),Student("lisi", 35)).toDS()
import org.apache.spark.sql.functions._
/**
* 为什么groupByKey()是有类型的
* groupByKey()对数据分组后,必须调用聚合函数,、也就是说groupByKey()生成的对象,里面的算子是有类型的
*/
ds.groupByKey(item => item.name)
/**
* groupBy()是没有类型的,可以按照某一列进行分组
* 主要是groupBy生成的对象的算子是无类型的
*/
//按照名字分组,然后取年龄的平均值
ds.groupBy('name).agg(mean("age")).show()
spark.stop()
}
case class Student(name:String,age:Int)
}Column对象
Column对象的创建

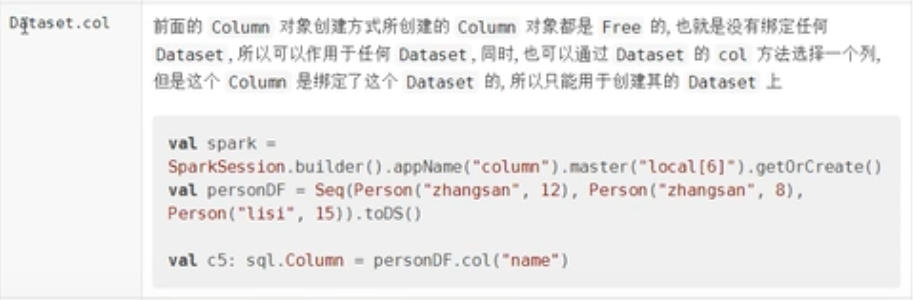
案例
object Test34 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[6]")
.appName("typed")
.getOrCreate()
import spark.implicits._
val ds: Dataset[Student] = Seq(Student("ziaorui", 25), Student("xiaoming",15),Student("lisi", 35)).toDS()
val ds1: Dataset[Student] = Seq(Student("ziaorui", 25), Student("xiaoming",15),Student("lisi", 35)).toDS()
val df: Dataset[Row] = Seq(("ziaorui", 25), ("xiaoming",15),("lisi", 35)).toDF("name","age")
import org.apache.spark.sql.functions._
//创建Column对象
/**
* 使用 ' 创建对象,必须导入spark的隐式转换
* Symbol类似于java的internal,internal类型对象会放入常量池中
* 隐式转换:implicit def symbolToColumn(s: Symbol): ColumnName = new ColumnName(s.name)
*/
val column: Symbol = 'name
/**
* $"name" 创建column,必须导入隐式转换
* $也是一个隐式转换,在底层会转换为ColumnName类型
*/
val column1:ColumnName = $"name"
/**
* col 方式创建column,但是必须先导入functions
*/
val column2: Column = col("name")
/*
column方式创建column,但是必须先导入functions
*/
val column3: Column = column("name")
//上面的四种创建方式,都没关联任何的dataset,但是可以直接使用
//column没有关联ds,但是这里可以直接使用
ds.select(column).show()
df.select(column).show()
//select算子可以使用column对象来选中某一个列,其他的算子也可以进行这样的操作
df.where(column ==="xiaoming").show()
/*
dataset.col()
下面的创建方式有什么区别,都是通过dataset进行创建,只不过两个column对象绑定了不同的dataset
使用dataset获取某一个column对象,会和某一个dataset进行绑定,在逻辑执行计划中,会有不同的表现
为什么要和dataset进行绑定呢?因为在进行连接的时候,要具体指明是哪一个dataset的列进行连接
*/
val column4: Column = ds.col("name")
val column5: Column = ds1.col("name")
//但是不能在一个dataset中去使用另外一个dataset的column对象
//ds.select(column5).show() 这样使用会报错
/*
dataset.apply()创建column对象,通过ds对象的apply()方法进行创建
下面的这两种写法等价
*/
val column6: Column = ds.apply("name")
val column7: Column = ds("name")
spark.stop()
}
case class Student(name:String,age:Int)
}- column对象有四种创建方式
- column对象可以作用于Dataset和DataFrame当中
- column可以和命令式的弱类型的api配合使用,比如select,where
- column对象的创建分为两大类:
- 有绑定的,有绑定方式,都一样,
- 无绑定的,四种创建方式都一样
操作

案例
object Test35 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[6]")
.appName("typed")
.getOrCreate()
import spark.implicits._
val ds: Dataset[Student] = Seq(Student("ziaorui", 25), Student("xiaoming",15),Student("lisi", 35)).toDS()
//给某一列添加别名
ds.select('name.as("new_name")).show()
//列的数据类型转换
ds.select('age.as[Long]).show()
spark.stop()
}
case class Student(name:String,age:Int)
}方法
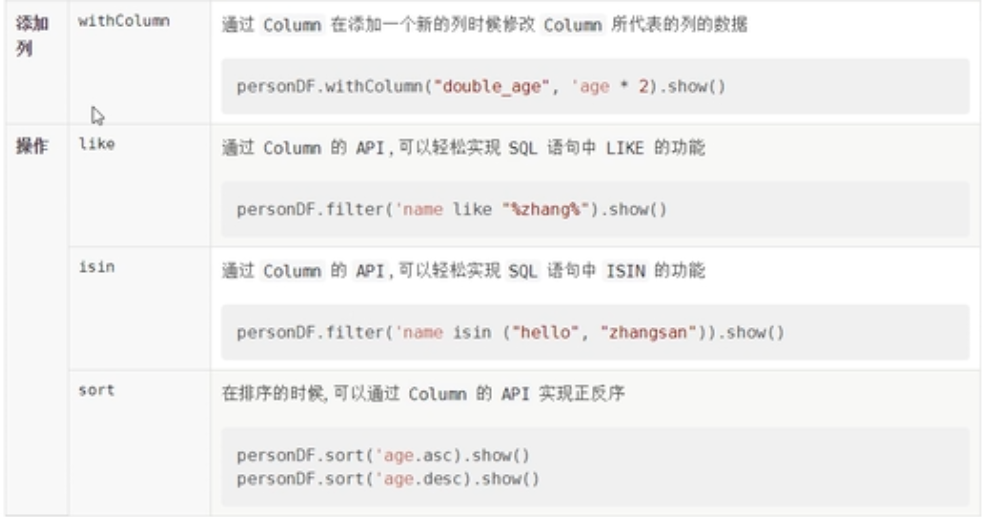
案例
object Test36 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[6]")
.appName("typed")
.getOrCreate()
import spark.implicits._
val ds: Dataset[Student] = Seq(Student("zhangsan", 25), Student("xiaoming",15),Student("lisi", 35)).toDS()
//新添加一列
//age*2本质上是将一个表达式附着到column对象上面,表达式在执行的时候,对应于每一条数据进行执行操作
ds.withColumn("doubledAge",'age*2).show()
//模糊查询:like
ds.where('name like "li%").show()
//对数据进行排序
ds.sort('age desc).show()
//枚举判断
ds.where('name isin("lisi","zhangsan")).show()
spark.stop()
}
case class Student(name:String,age:Int)
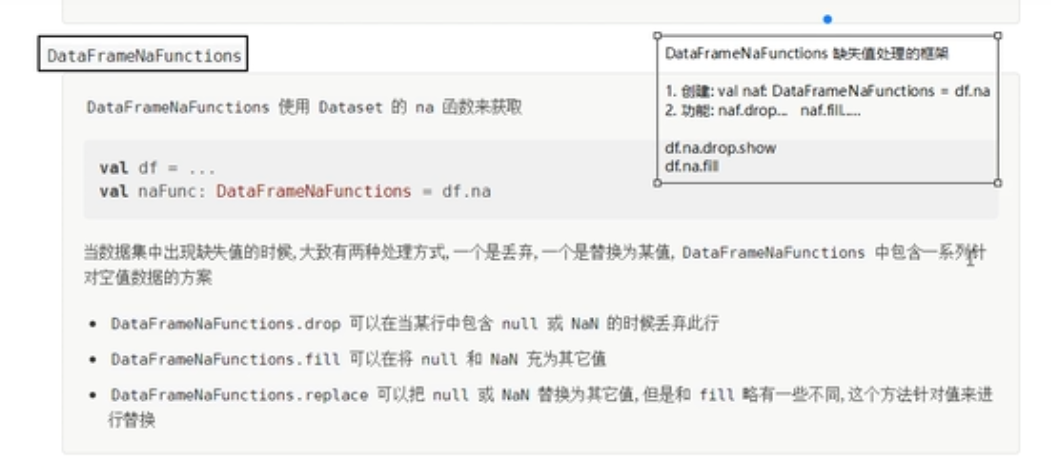
}缺失值处理
缺失值的产生

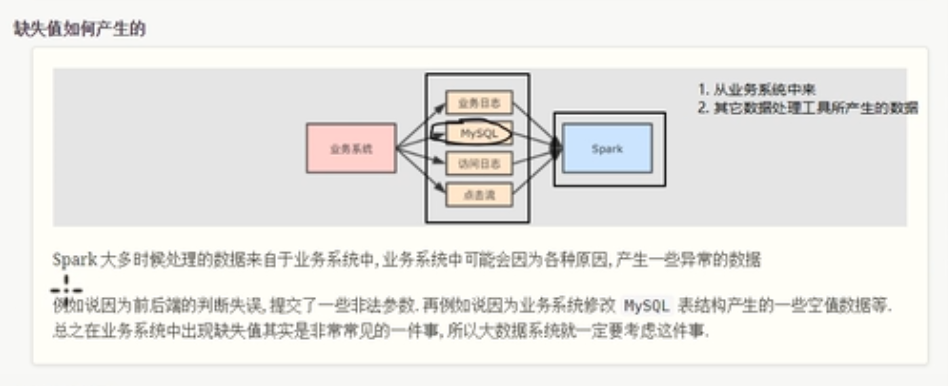
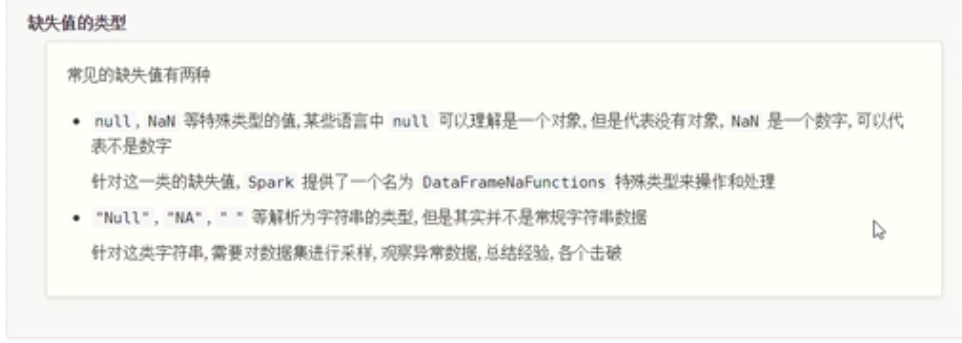
缺失值的处理
NaN&NULL缺失值处理
数据的读取
object Test37 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[6]")
.appName("typed")
.getOrCreate()
import spark.implicits._
/**
* 1 读取数据,通过spark.csv()自动推断类型进行读取
* 下面这种读取方式存在问题,推断数字的时候,会将nan这种值推断为字符串,导致整个列都变为字符串
*/
//spark.read
// .option("header",true)
// .option("inferSchema",true)//自动推断schema进行数据的读取
// .csv()
//2 直接读取为字符串,然后使用map算子转换类型
spark.read.csv("").map(row=>{row.anyNull})
//3 指定schema,不要进行自动类型推断,
//创建schema
val schema=StructType(
List(
StructField("id",LongType),
StructField("year",IntegerType),
StructField("month",IntegerType),
StructField("day",IntegerType),
StructField("season",IntegerType),
StructField("pm",DoubleType),
)
)
//通过指定列的类型,如果在读取数据的时候,某一列有nan数值,那么就会转换为当前列数据类型下的nan类型
//Double.NaN
spark.read
.option("header",true)
.schema(schema)
.csv("")
spark.stop()
}
case class Student(name:String,age:Int)
}第一种处理策略---丢弃

案例
object Test37 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[6]")
.appName("typed")
.getOrCreate()
import spark.implicits._
/**
* 1 读取数据,通过spark.csv()自动推断类型进行读取
* 下面这种读取方式存在问题,推断数字的时候,会将nan这种值推断为字符串,导致整个列都变为字符串
*/
//spark.read
// .option("header",true)
// .option("inferSchema",true)//自动推断schema进行数据的读取
// .csv()
//2 直接读取为字符串,然后使用map算子转换类型
spark.read.csv("").map(row=>{row.anyNull})
//3 指定schema,不要进行自动类型推断,
//创建schema
val schema=StructType(
List(
StructField("id",LongType),
StructField("year",IntegerType),
StructField("month",IntegerType),
StructField("day",IntegerType),
StructField("season",IntegerType),
StructField("pm",DoubleType),
)
)
//通过指定列的类型,如果在读取数据的时候,某一列有nan数值,那么就会转换为当前列数据类型下的nan类型
//Double.NaN
val source: DataFrame = spark.read
.option("header", true)
.schema(schema)
.csv("")
/*
丢弃的规则:
2019,12,12,60.0
1 any:数据中,只要某一列为nan就丢弃数据记录
2 all:所有都是nan的行才丢弃
3 针对某些列丢弃
*/
//使用any()处理缺失值,
//source.na返回的是一个DataFrameNaFunctions对象,不能直接调用show()算子,必须先进行缺失值处理,才可以show
//val na: DataFrameNaFunctions = source.na
source.na.drop("any").show()//默认也是使用any
//使用all
source.na.drop("all").show()
//针对某一些列的规则,
//也就是说只要list集合中的某一列为null,就执行丢弃操作,此时的any只是作用于list集合中的列
source.na.drop("any",List("year","month","day")).show()
/*
缺失值的填充:
1 针对所有列数据的默认值填充
2 针对特定的列进行填充
*/
//针对所有列数据进行填充,把所有的缺失值填充为0
source.na.fill(0).show()
//针对特定的列进行填充
source.na.fill(0,List("month","year"))
spark.stop()
}
case class Student(name:String,age:Int)
}字符串类型缺失值处理

案例
object Test39 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[6]")
.appName("typed")
.getOrCreate()
import spark.implicits._
/**
* 1 读取数据,通过spark.csv()自动推断类型进行读取
* 下面这种读取方式存在问题,推断数字的时候,会将nan这种值推断为字符串,导致整个列都变为字符串
*/
val source: DataFrame = spark.read
.option("header", true)
.option("inferSchema", true) //自动推断schema进行数据的读取
.csv()
//1 丢弃策略
source.where('PM_Dongsi =!= "NA").show()
//2 替换策略
/*
在select 语句中可以使用when ..... then 语句
select name,age,grade from table
when....then
when....then
else...
*/
import org.apache.spark.sql.functions._
source.select('No as("id"),'year,'month,'day,when('PM_Dongsi === "NA",Double.NaN)
.otherwise('PM_Dongsi cast(DoubleType))
.as("pm")).show()
//使用replace()方法替换
//但是原来的类型和转换过后的类型必须一致
source.na.replace("PM_Dongsi",Map("NA"-> "NAN","NULL"->"null")).show()
spark.stop()
}
case class Student(name:String,age:Int)
}聚合操作
数据操作的一般步骤
- 读取数据
- 数据操作
- 类型转换,数据清洗
- 落地数据
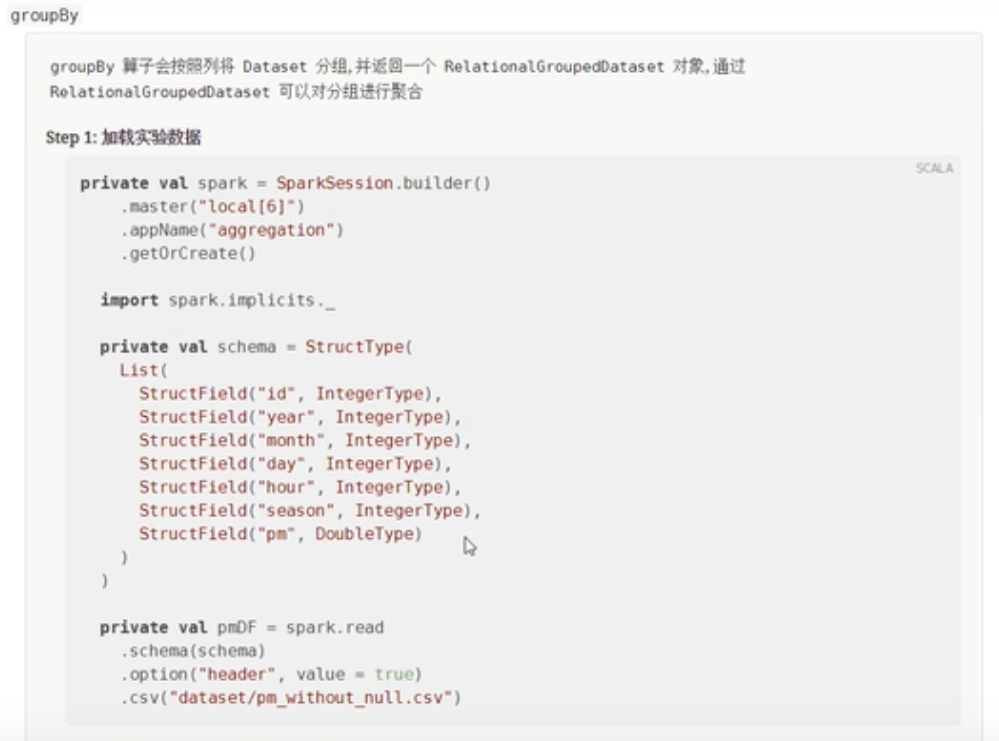
groupBy
案例
object Test40 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[6]")
.appName("typed")
.getOrCreate()
import spark.implicits._
import org.apache.spark.sql.functions._
//创建schema
val schema=StructType(
List(
StructField("id",LongType),
StructField("year",IntegerType),
StructField("month",IntegerType),
StructField("day",IntegerType),
StructField("season",IntegerType),
StructField("pm",DoubleType),
)
)
val source: DataFrame = spark.read
.option("header", true)
.schema(schema)
.csv()
//首先对数据进行清洗
source.where('pm =!=Double.NaN).show()
//对数据进行分组操作,先按照年进行分组,在按照月进行分组
val dataset: RelationalGroupedDataset = source.groupBy('year, $"month")
//使用functions函数完成聚合操作
//avg本质上定义了一个操作,把操作设置给pm列中的所有数据
//select avg(pm) from table group by
dataset.agg(avg('pm).as("pm_avg"))
.orderBy('pm_avg.desc)//按照降序排列
.show()
//直接使用RelationalGroupedDataset的avg算子进行聚合操作
dataset.avg("pm")
.orderBy("avg(pm)")
.show()
//在这里还可以求出其他的统计量:mean(),max(),min(),sum(),stddev()方差
spark.stop()
}
case class Student(name:String,age:Int)
}多维聚合
需求一:
- 不同来源的pm统计
- 在同一个月,不同来源的pm值是多少
- 在同一年,不同来源的pm值平均是多少
- 整体来看,不同来源的pm值是多少
什么是多维聚合,多维聚合就是在一个统计结果中,包含总计,小计,
案例
object Test41 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[6]")
.appName("typed")
.getOrCreate()
import org.apache.spark.sql.functions._
import spark.implicits._
//创建schema
val schema=StructType(
List(
//这里新增加一列,表示统计pm值的来源
StructField("source",StringType),
StructField("id",LongType),
StructField("year",IntegerType),
StructField("month",IntegerType),
StructField("day",IntegerType),
StructField("season",IntegerType),
StructField("pm",DoubleType),
)
)
val source: DataFrame = spark.read
.option("header", true)
.schema(schema)
.csv()
//不同年,不同来源,pm值的平均数
//select source,year,avg(pm) as pmfrom table group by source,year
val frame: DataFrame = source.groupBy('source, 'year)
.agg(avg('pm).as("pm"))
//在整个数据集中,按照不同来源统计pm值的平均数
val frame1: DataFrame = source.groupBy('source)
.agg(avg('pm).as("pm"))
.select('source,lit(null) as "year",'pm)//lit的含义是新添加一列,内容是null
//把上面的两个统计结果合并在一个数据集中
frame.union(frame1)
.sort('source,'year.asc_nulls_last,'pm)
.show()
spark.stop()
}
case class Student(name:String,age:Int)
}
rollup
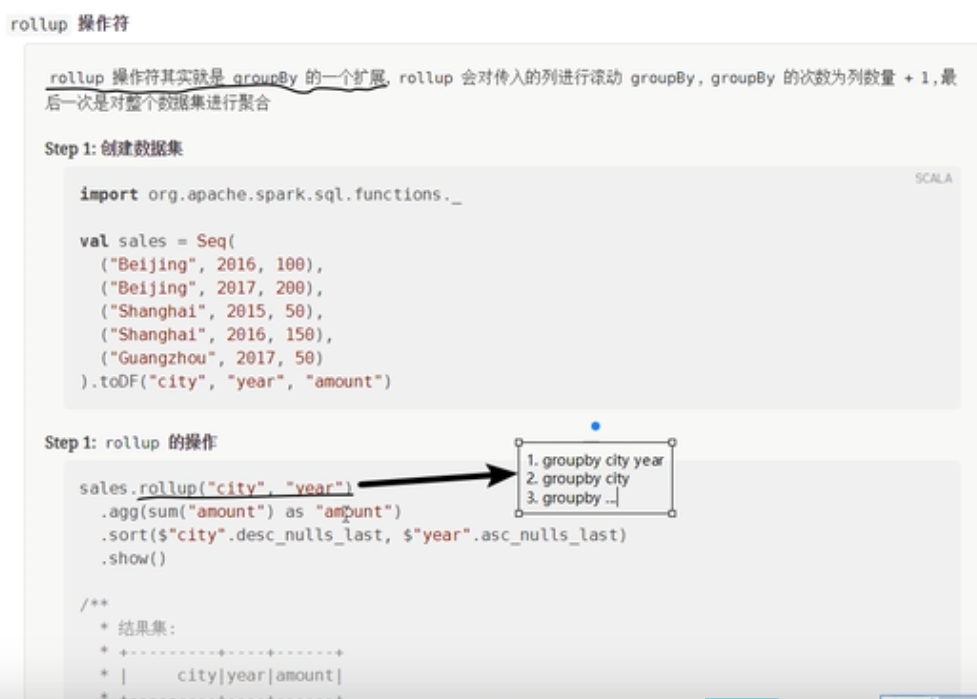
简单来说就是进行多次的分组操作,第一次先按照所有指定的字段进行分组,每次减少一个字段进行分组,直到剩下一个字段为止,对全局进行一个分组。
案例
object Test42 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[6]")
.appName("typed")
.getOrCreate()
import org.apache.spark.sql.functions._
import spark.implicits._
val source=Seq(
("beijing",2016,100),
("beijing",2017,200),
("shanghai",2015,50),
("shanghai",2016,150),
("guangzhou",2015,50),
).toDF("city","year","amount")
//统计每一个城市每一年的消费额
//统计每一个城市总共的消费额
//总体的销售额
/**
* 滚动分组 A,B==>最终会生成AB , A, NULL的分组结果,分完组后,还要对最终的结果进行聚合操作
*/
source.rollup('city,'year)
.agg(sum('amount).as("amount"))
.sort('city.asc_nulls_last,'year.asc_nulls_last)//表示这一列的空值排列在最后
.show()
/*
+---------+----+------+
| city|year|amount|
+---------+----+------+
| beijing|2016| 100| 按照city,year统计的结果
| beijing|2017| 200|
| beijing|null| 300| 按照city进行统计,北京全部的销售额
|guangzhou|2015| 50|
|guangzhou|null| 50|
| shanghai|2015| 50|
| shanghai|2016| 150|
| shanghai|null| 200|
| null|null| 550| 按照全部把整个数据加起来,整个公司所有年份的销售额
+---------+----+------+
*/
spark.stop()
}
case class Student(name:String,age:Int)
}案例二
object Test43 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[6]")
.appName("typed")
.getOrCreate()
import org.apache.spark.sql.functions._
import spark.implicits._
//创建schema
val schema=StructType(
List(
//这里新增加一列,表示统计pm值的来源
StructField("source",StringType),
StructField("id",LongType),
StructField("year",IntegerType),
StructField("month",IntegerType),
StructField("day",IntegerType),
StructField("season",IntegerType),
StructField("pm",DoubleType),
)
)
val source: DataFrame = spark.read
.option("header", true)
.schema(schema)
.csv()
/**
* 需求一:每一个pm统计者,一年pm值统计的平均值,按照source year进行分组
* 需求二:每一个pm统计者,整体上pm的平均值,按照source进行分组
* 需求三:全局所有的pm统计者,和日期的pm平均值,按照null进行分组
*/
source.rollup('source,'year)
.agg(avg('pm.as("pm")))
.sort('source.asc_nulls_last,'year.asc_nulls_last)
.show()
spark.stop()
}
case class Student(name:String,age:Int)
}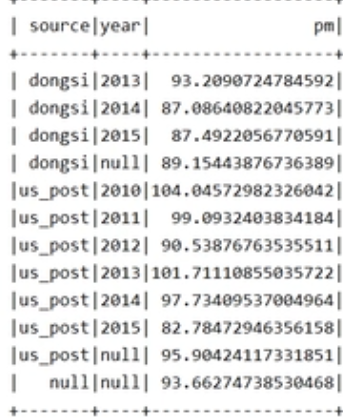
产生的问题

如果把source和year相互交换位置,产生的结果会一样么?明显不一样,因为在第二次分组时候,产生了分歧,rollup分组会按照指定的第一列为支点进行分组操作。所以可以使用cube进行弥补。
cube
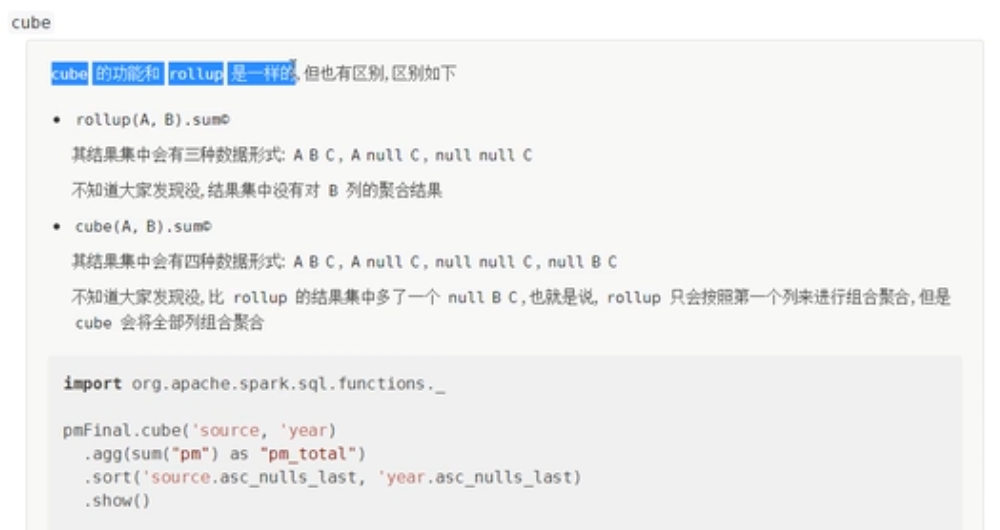
案例
object Test44 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[6]")
.appName("typed")
.getOrCreate()
import org.apache.spark.sql.functions._
import spark.implicits._
//创建schema
val schema=StructType(
List(
//这里新增加一列,表示统计pm值的来源
StructField("source",StringType),
StructField("id",LongType),
StructField("year",IntegerType),
StructField("month",IntegerType),
StructField("day",IntegerType),
StructField("season",IntegerType),
StructField("pm",DoubleType),
)
)
val source: DataFrame = spark.read
.option("header", true)
.schema(schema)
.csv()
source.cube('source,'year)
.agg(avg('pm.as("pm")))
.sort('source.asc_nulls_last,'year.asc_nulls_last)
.show()
spark.stop()
}
case class Student(name:String,age:Int)
}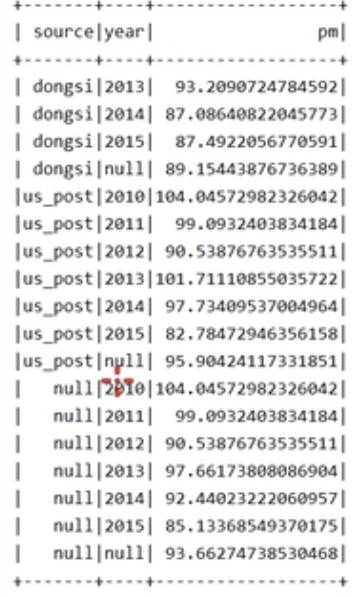
最明显的结果是最后把每一年的平均值也统计出来了。
使用sql语句完成
object Test45 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[6]")
.appName("typed")
.getOrCreate()
import org.apache.spark.sql.functions._
import spark.implicits._
//创建schema
val schema=StructType(
List(
//这里新增加一列,表示统计pm值的来源
StructField("source",StringType),
StructField("id",LongType),
StructField("year",IntegerType),
StructField("month",IntegerType),
StructField("day",IntegerType),
StructField("season",IntegerType),
StructField("pm",DoubleType),
)
)
val source: DataFrame = spark.read
.option("header", true)
.schema(schema)
.csv()
source.cube('source,'year)
.agg(avg('pm.as("pm")))
.sort('source.asc_nulls_last,'year.asc_nulls_last)
.show()
//使用sql语句完成
//创建一个临时的表
source.createOrReplaceTempView("pm_final")
val res: DataFrame = spark.sql("select source,year,avg(pm) as pm from pm_final group by source,year grouping sets((source,year),(source),(year),())"
+ "order by source asc nulls last,year asc nulls last")
res.show()
spark.stop()
}
case class Student(name:String,age:Int)
}groupBy,cube,rollup返回的结果都是RelationalGroupedDataset类型。
RelationalGroupedDataset
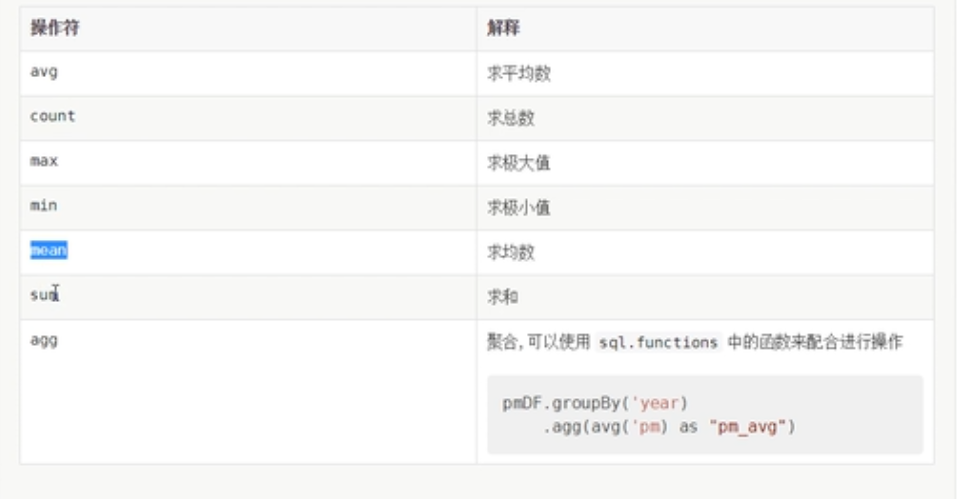
RelationalGroupedDataset是一个分过组的数据集。
连接操作
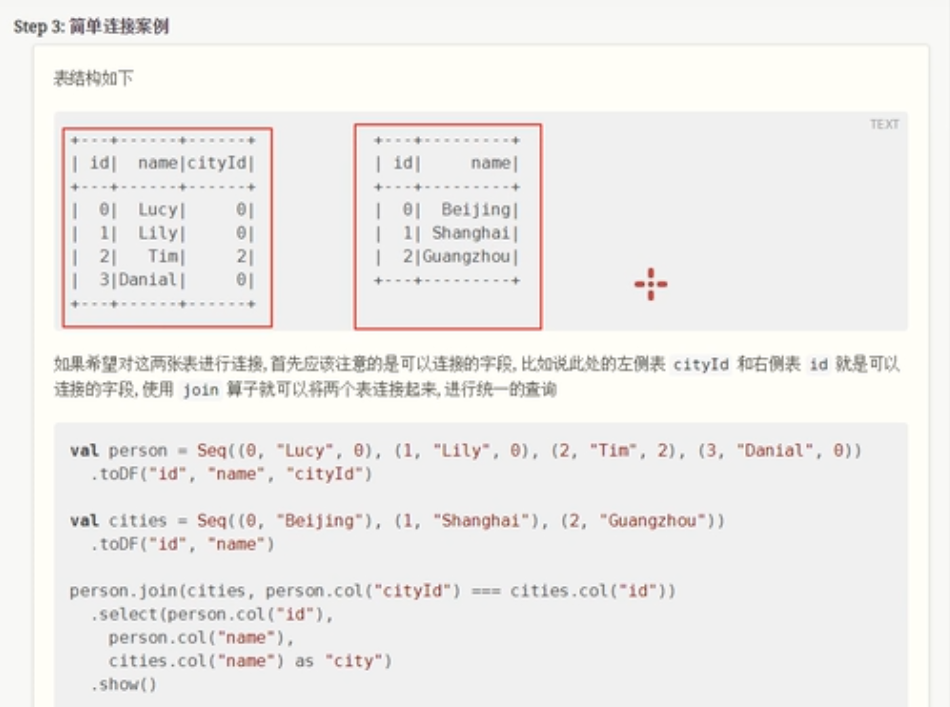
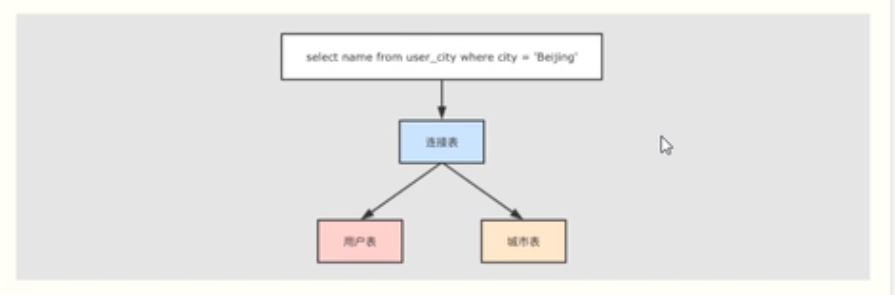
案例
object Test46 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[6]")
.appName("typed")
.getOrCreate()
import org.apache.spark.sql.functions._
import spark.implicits._
val df: DataFrame = Seq((0, "Lucy", 0), (1, "lily", 0), (2, "Tim", 2), (3, "Danial", 0)).toDF("id", "name", "cityId")
val city: DataFrame = Seq((0, "beijing"), (1, "shanghai"), (2, "guangzhou")).toDF("id", "name")
val person=df.join(city,df.col("cityId") === city.col("id"))
.select(df.col("id"),df.col("name"),city.col("name").as("city"))
person.createOrReplaceTempView("per_city")
spark.sql("select id,name,city from per_city where city='beijing'").show()
spark.stop()
}
}
+---+------+-------+
| id| name| city|
+---+------+-------+
| 0| Lucy|beijing|
| 1| lily|beijing|
| 3|Danial|beijing|
+---+------+-------+交叉连接
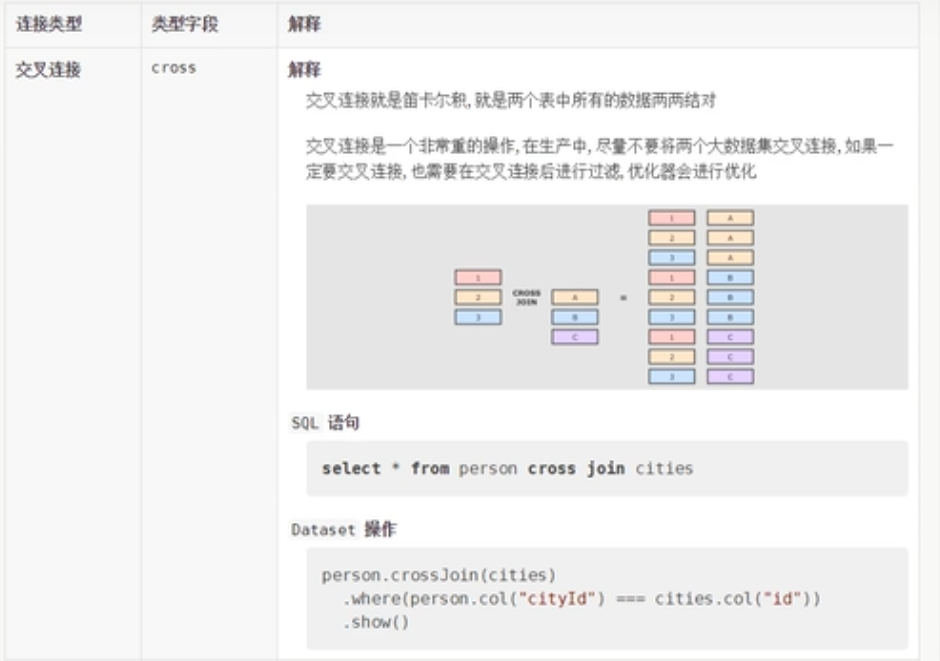
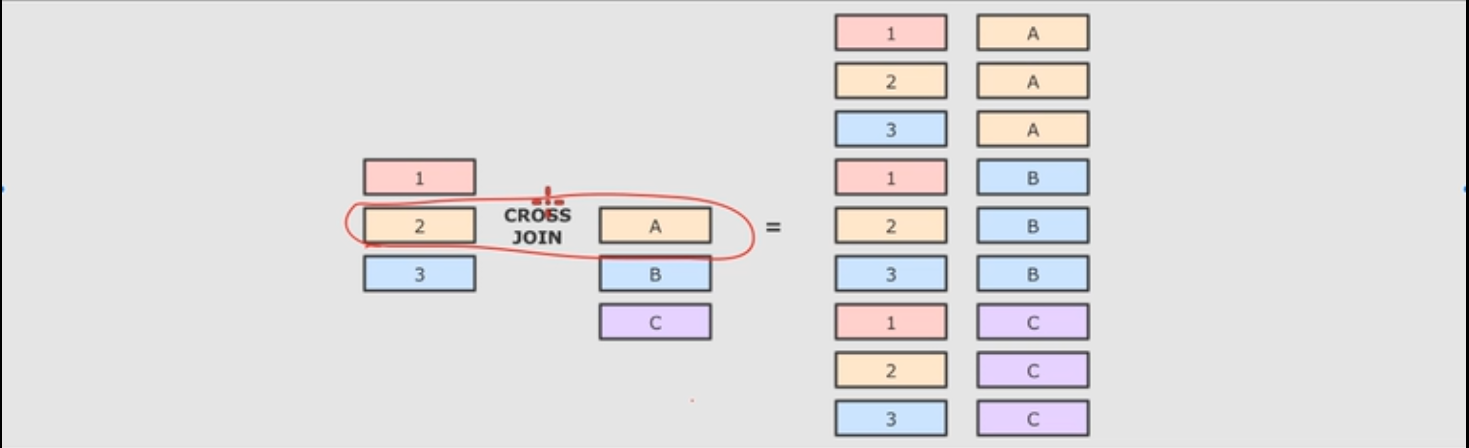
交叉连接,可以认为是笛卡尔积操作。
object Test47 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[6]")
.appName("typed")
.getOrCreate()
import spark.implicits._
val df: DataFrame = Seq((0, "Lucy", 0), (1, "lily", 0), (2, "Tim", 2), (3, "Danial", 0)).toDF("id", "name", "cityId")
val city: DataFrame = Seq((0, "beijing"), (1, "shanghai"), (2, "guangzhou")).toDF("id", "name")
//交叉连接,添加限定条件准确的说是内连接
df.crossJoin(city)
.where(df.col("cityId")===city.col("id"))
.show()
df.createOrReplaceTempView("df")
city.createOrReplaceTempView("city")
//使用sql语句写
spark.sql("select u.id,u.name,c.name from df u cross join city c where u.cityId = c.id").show()
spark.stop()
}
}内连接

案例
object Test48 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[6]")
.appName("typed")
.getOrCreate()
import spark.implicits._
val df: DataFrame = Seq((0, "Lucy", 0), (1, "lily", 0), (2, "Tim", 2), (3, "Danial", 3)).toDF("id", "name", "cityId")
val city: DataFrame = Seq((0, "beijing"), (1, "shanghai"), (2, "guangzhou")).toDF("id", "name")
df.createOrReplaceTempView("p")
city.createOrReplaceTempView("c")
//内连接,最后一个参数指定的是连接的方式
df.join(city,df.col("cityId")===city.col("id"),"inner").show()
//使用sql表达
spark.sql("select p.id,p.name,c.name from p inner join c on p.cityId = c.id").show()
spark.stop()
}
}全外连接

案例
object Test49 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[6]")
.appName("typed")
.getOrCreate()
import spark.implicits._
val df: DataFrame = Seq((0, "Lucy", 0), (1, "lily", 0), (2, "Tim", 2), (3, "Danial", 3)).toDF("id", "name", "cityId")
val city: DataFrame = Seq((0, "beijing"), (1, "shanghai"), (2, "guangzhou")).toDF("id", "name")
df.createOrReplaceTempView("p")
city.createOrReplaceTempView("c")
//内连接,最后一个参数指定的是连接的方式
df.join(city,df.col("cityId")===city.col("id"),"full").show()
//使用sql表达
spark.sql("select p.id,p.name,c.name from p full outer join c on p.cityId = c.id").show()
spark.stop()
}
}左外连接

案例
object Test50 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[6]")
.appName("typed")
.getOrCreate()
import spark.implicits._
val df: DataFrame = Seq((0, "Lucy", 0), (1, "lily", 0), (2, "Tim", 2), (3, "Danial", 3)).toDF("id", "name", "cityId")
val city: DataFrame = Seq((0, "beijing"), (1, "shanghai"), (2, "guangzhou")).toDF("id", "name")
df.createOrReplaceTempView("p")
city.createOrReplaceTempView("c")
//内连接,最后一个参数指定的是连接的方式
df.join(city,df.col("cityId")===city.col("id"),"left").show()
//使用sql表达
spark.sql("select p.id,p.name,c.name from p left join c on p.cityId = c.id").show()
spark.stop()
}
}右外连接
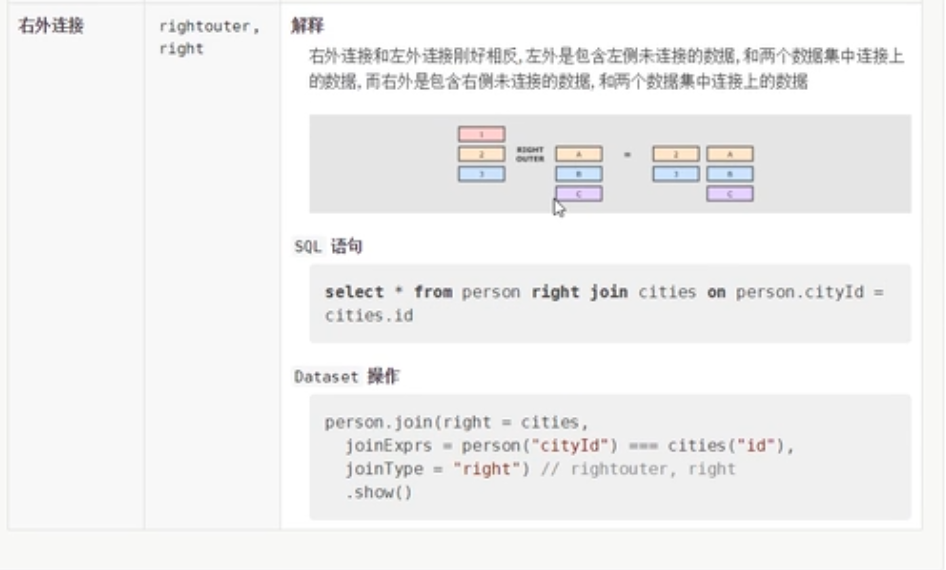
案例
object Test50 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[6]")
.appName("typed")
.getOrCreate()
import spark.implicits._
val df: DataFrame = Seq((0, "Lucy", 0), (1, "lily", 0), (2, "Tim", 2), (3, "Danial", 3)).toDF("id", "name", "cityId")
val city: DataFrame = Seq((0, "beijing"), (1, "shanghai"), (2, "guangzhou")).toDF("id", "name")
df.createOrReplaceTempView("p")
city.createOrReplaceTempView("c")
//内连接,最后一个参数指定的是连接的方式
df.join(city,df.col("cityId")===city.col("id"),"right").show()
//使用sql表达
spark.sql("select p.id,p.name,c.name from p right join c on p.cityId = c.id").show()
spark.stop()
}
}LeftAnti
显示两个表没有连接上的部分,右侧表不显示


案例
object Test51 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[6]")
.appName("typed")
.getOrCreate()
import spark.implicits._
val df: DataFrame = Seq((0, "Lucy", 0), (1, "lily", 0), (2, "Tim", 2), (3, "Danial", 3)).toDF("id", "name", "cityId")
val city: DataFrame = Seq((0, "beijing"), (1, "shanghai"), (2, "guangzhou")).toDF("id", "name")
df.createOrReplaceTempView("p")
city.createOrReplaceTempView("c")
//内连接,最后一个参数指定的是连接的方式
df.join(city,df.col("cityId")===city.col("id"),"leftanti").show()
//使用sql表达,因为不显示右边的数据,所以查询不到c.name
spark.sql("select p.id,p.name from p left anti join c on p.cityId = c.id").show()
/*
+---+------+
| id| name|
+---+------+
| 3|Danial|
+---+------+
*/
spark.stop()
}
}LeftSemi
显示连接上的部分,右侧表不显示

案例
object Test52 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[6]")
.appName("typed")
.getOrCreate()
import spark.implicits._
val df: DataFrame = Seq((0, "Lucy", 0), (1, "lily", 0), (2, "Tim", 2), (3, "Danial", 3)).toDF("id", "name", "cityId")
val city: DataFrame = Seq((0, "beijing"), (1, "shanghai"), (2, "guangzhou")).toDF("id", "name")
df.createOrReplaceTempView("p")
city.createOrReplaceTempView("c")
//内连接,最后一个参数指定的是连接的方式
df.join(city,df.col("cityId")===city.col("id"),"leftsemi").show()
//使用sql表达,因为不显示右边的数据,所以查询不到c.name
spark.sql("select p.id,p.name from p left semi join c on p.cityId = c.id").show()
/*
+---+----+
| id|name|
+---+----+
| 0|Lucy|
| 1|lily|
| 2| Tim|
+---+----+
*/
spark.stop()
}
}函数
案例
object Test53 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[6]")
.appName("typed")
.getOrCreate()
import spark.implicits._
import org.apache.spark.sql.functions._
val source = Seq(
("Thin", "Cell phone", 6000),
("normal", "Tablet", 1500),
("Mini", "Tablet", 5500),
("Ultra thin", "Cell phone", 5500),
("Very thin", "Cell phone", 6000),
("Big", "Tablet", 2500),
("Bendable", "Cell phone", 3000),
("Foldable", "Cell phone", 3000),
("Pro", "Tablet", 4500),
("Pro2", "Tablet", 6500)
).toDF("product","category","revenue")
//聚合每一个类别的总价,先分组,然后对每一组的数据进行聚合操作
source.groupBy('category)
.agg(sum('revenue))
.show()
//把名称变为小写
//注意:functions下面的函数,会作用于一列数据,然后在返回新的一列
source.select(lower('product)).show()
//把价格变为字符串的形式
//注册自定义函数
val toStrUDF: UserDefinedFunction = udf(toStr(_))
source.select('product,'category,toStrUDF('revenue)).show()
spark.stop()
}
//自定义函数
def toStr(reveine:Long):String={
(reveine/1000)+"k"
}
}窗口函数
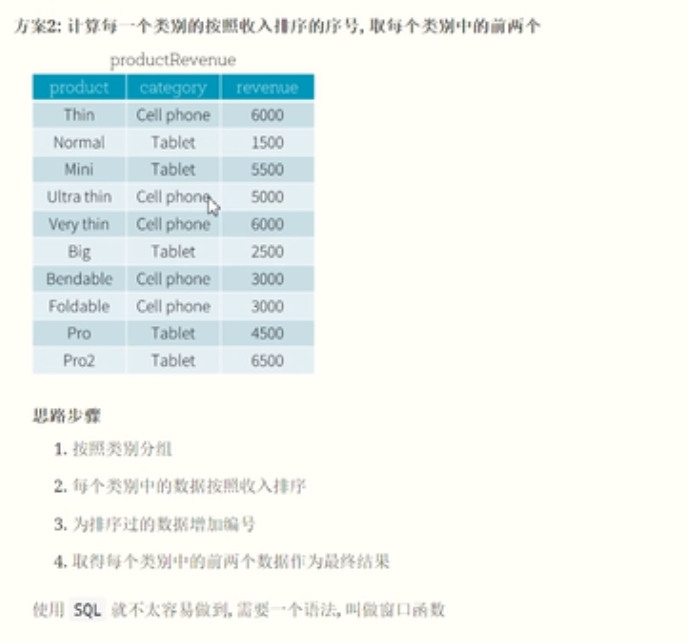
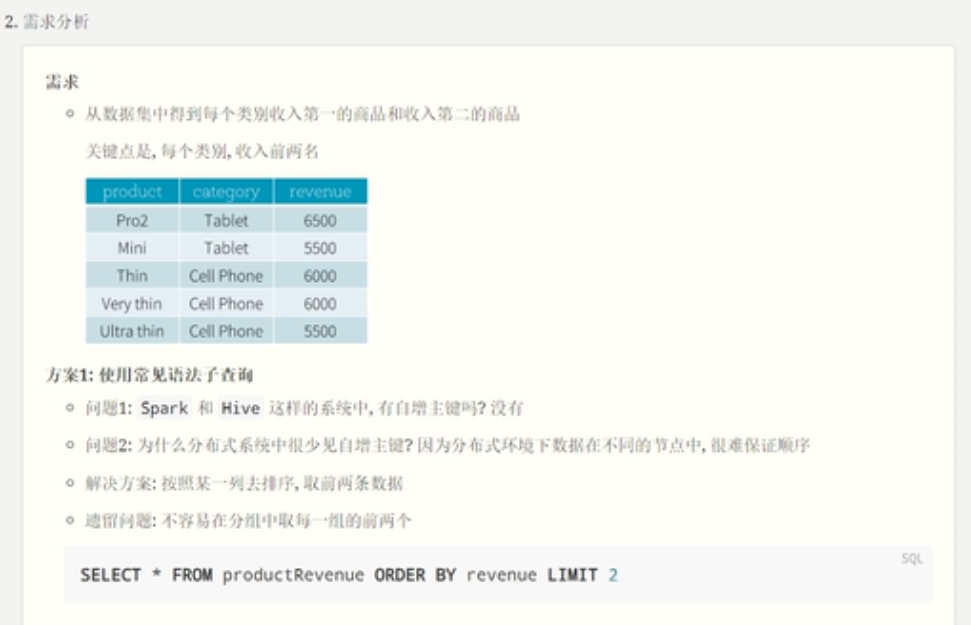
案例
object Test54 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[6]")
.appName("typed")
.getOrCreate()
import org.apache.spark.sql.functions._
import spark.implicits._
val source = Seq(
("Thin", "Cell phone", 6000),
("normal", "Tablet", 1500),
("Mini", "Tablet", 5500),
("Ultra thin", "Cell phone", 5500),
("Very thin", "Cell phone", 6000),
("Big", "Tablet", 2500),
("Bendable", "Cell phone", 3000),
("Foldable", "Cell phone", 3000),
("Pro", "Tablet", 4500),
("Pro2", "Tablet", 6500)
).toDF("product","category","revenue")
//1 定义窗口
val win: WindowSpec = Window.partitionBy('category)
.orderBy('revenue.desc)
//dense_rank会生成编号,根据生成的win进行排序
source.select('product,'category,dense_rank().over(win).as("rank"))
.where('rank <= 2)
.show()
//使用sql完成
source.createOrReplaceTempView("tab")
//spark.sql("select product,category,revenue from (select *,dense_rank() " +
// "over (partitionBy category order by revenue desc as rank) from tab) where rank <=2")
//统计每一个商品,和此品类商品最贵商品之间的差值
spark.stop()
}
}从逻辑上讲,窗口函数的执行大致分为以下步骤
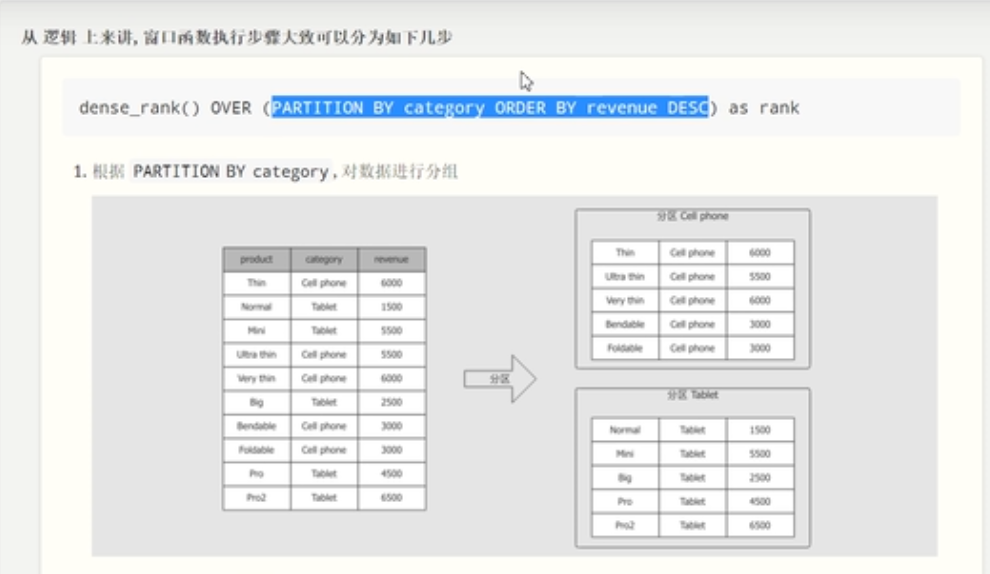
开辟窗口函数,使用over函数,over函数里面的内容表示如何开辟窗口函数。
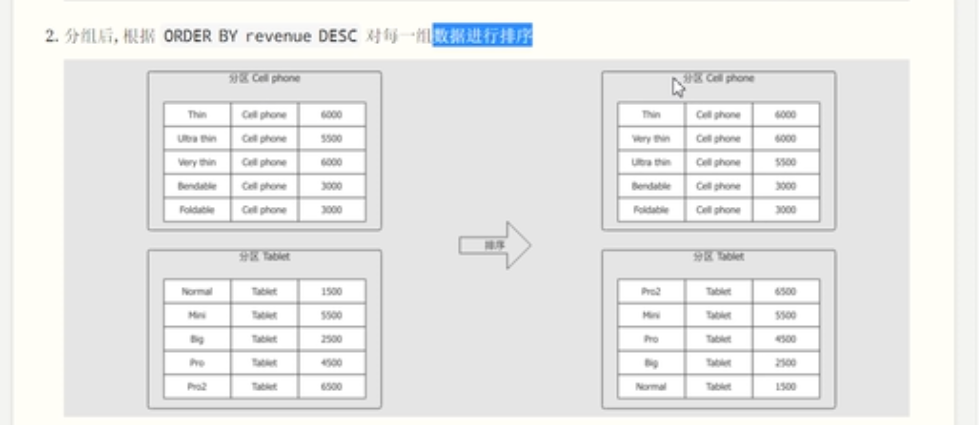
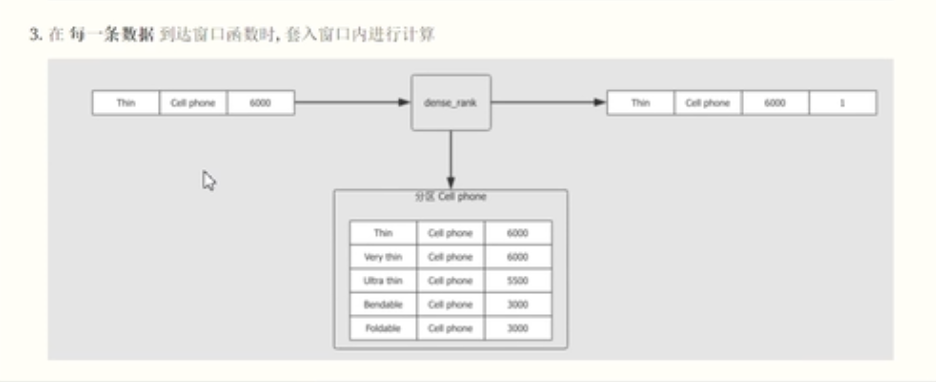
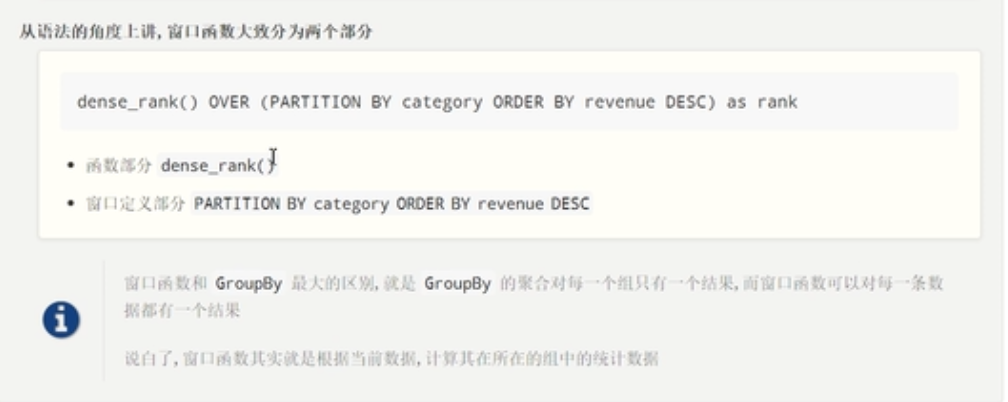
函数部分为作用于窗口的函数。
窗口的定义部分
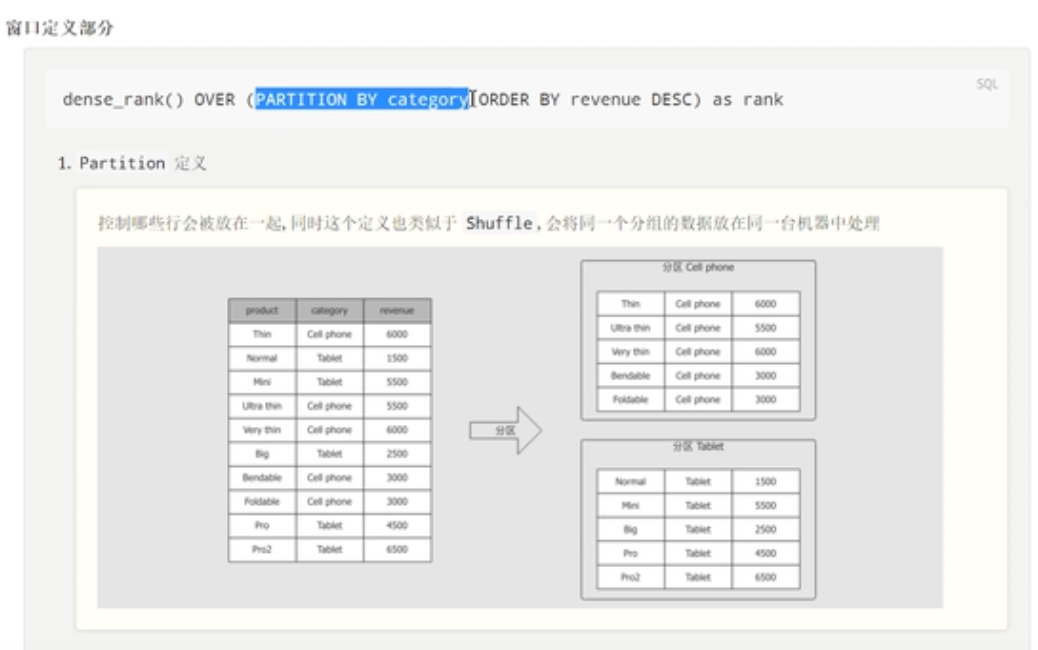
窗口的定义使用partitionBy()函数,就是对数据进行分区操作。

定义每一个分区或者窗口内部数据的顺序。


函数部分
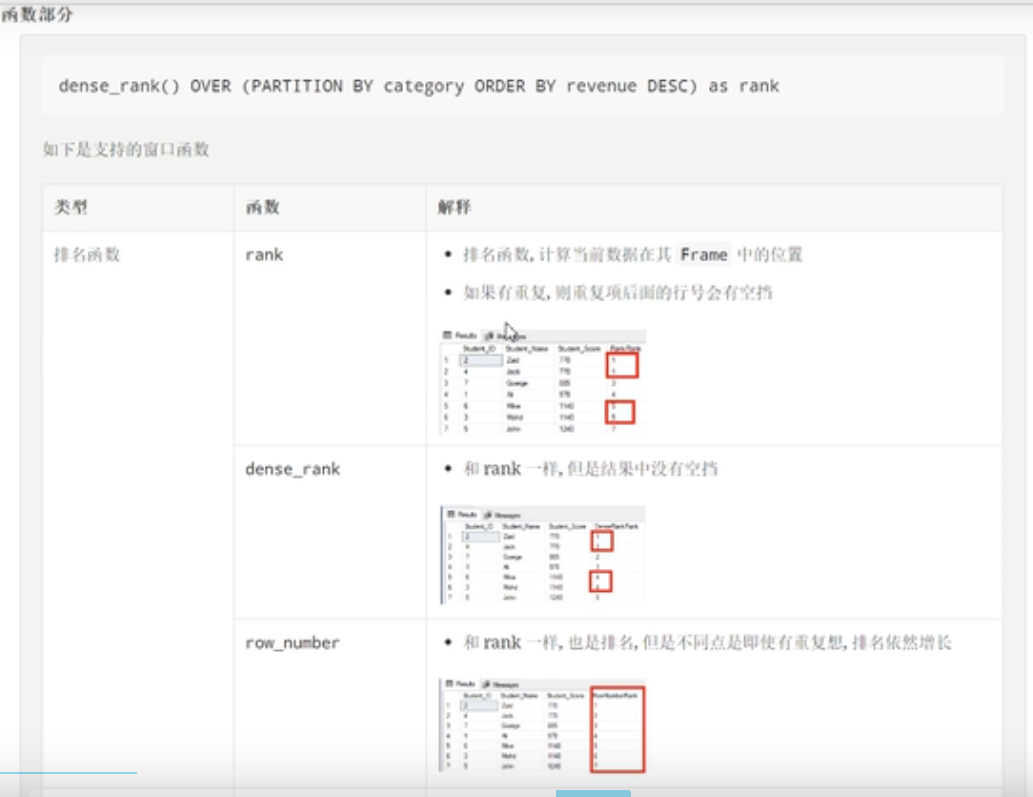
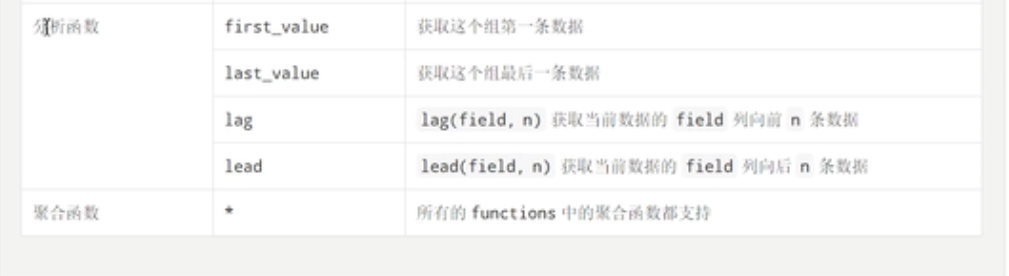
统计每一个商品,和此品类商品最贵商品之间的差值
object Test55 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[6]")
.appName("typed")
.getOrCreate()
import spark.implicits._
import org.apache.spark.sql.functions._
val source = Seq(
("Thin", "Cell phone", 6000),
("normal", "Tablet", 1500),
("Mini", "Tablet", 5500),
("Ultra thin", "Cell phone", 5500),
("Very thin", "Cell phone", 6000),
("Big", "Tablet", 2500),
("Bendable", "Cell phone", 3000),
("Foldable", "Cell phone", 3000),
("Pro", "Tablet", 4500),
("Pro2", "Tablet", 6500)
).toDF("product","category","revenue")
//统计每一个商品,和此品类商品最贵商品之间的差值
//1 定义窗口,按照分类进行倒序排列
val win: WindowSpec = Window.partitionBy('category)
.orderBy('revenue.desc)
//2 找到最贵商品价格,根据窗口,找到最大值
//max是作用于窗口的函数,win是开辟好的窗口
val maxPrice:Column=max('revenue) over(win)
//3 获取结果
source.select('product,'category,'revenue,(maxPrice-'revenue).as("reve_diff"))
.show()
spark.stop()
}
}贡献者
 codingLab
codingLab版权所有
版权归属:
许可证: