5、SparkSql扩展
SparkSql扩展
在SparkSQL模块,提供一套完成API接口,用于方便读写外部数据源的的数据(从Spark 1.4版本提供),框架本身内置外部数据源:
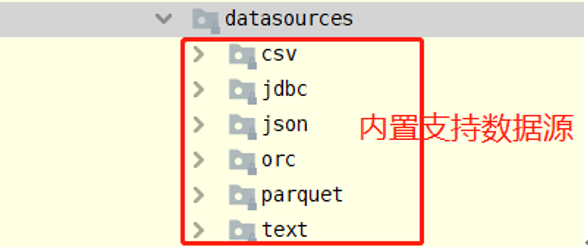
数据源与格式
数据分析处理中,数据可以分为结构化数据、非结构化数据及半结构化数据。

结构化数据(Structured)
- 结构化数据源可提供有效的存储和性能。例如,Parquet和ORC等柱状格式使从列的子集中提取值变得更加容易。
- 基于行的存储格式(如Avro)可有效地序列化和存储提供存储优势的数据。然而,这些优点通常以灵活性为代价。如因结构的固定性,格式转变可能相对困难。
非结构化数据(UnStructured)
- 相比之下,非结构化数据源通常是自由格式文本或二进制对象,其不包含标记或元数据以定义数据的结构。
- 报纸文章,医疗记录,图像,应用程序日志通常被视为非结构化数据。这些类型的源通常要求数据周围的上下文是可解析的。
半结构化数据(Semi-Structured)
- 半结构化数据源是按记录构建的,但不一定具有跨越所有记录的明确定义的全局模式。每个数据记录都使用其结构信息进行扩充。
- 半结构化数据格式的好处是,它们在表达数据时提供了最大的灵活性,因为每条记录都是自我描述的。但这些格式的主要缺点是它们会产生额外的解析开销,并且不是特别为ad-hoc(特定)查询而构建的。
DataFrameReader
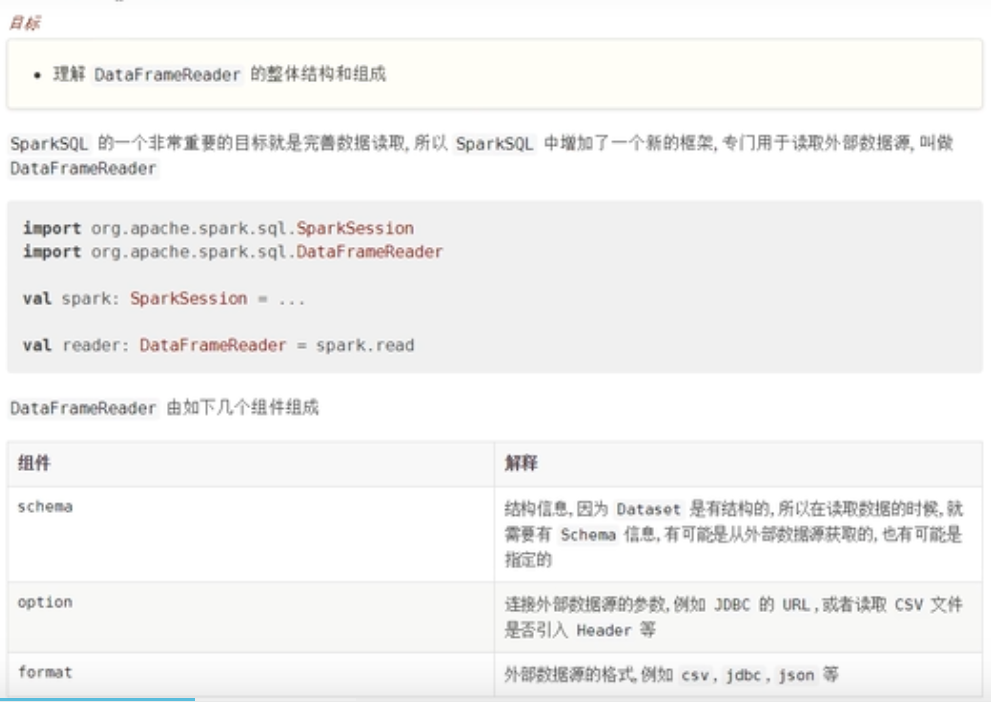
读取文件,至少设置以下内容:
- 文件地址
- 文件类型(format)
- 读取数据的参数(option)
- 结构信息(schema)
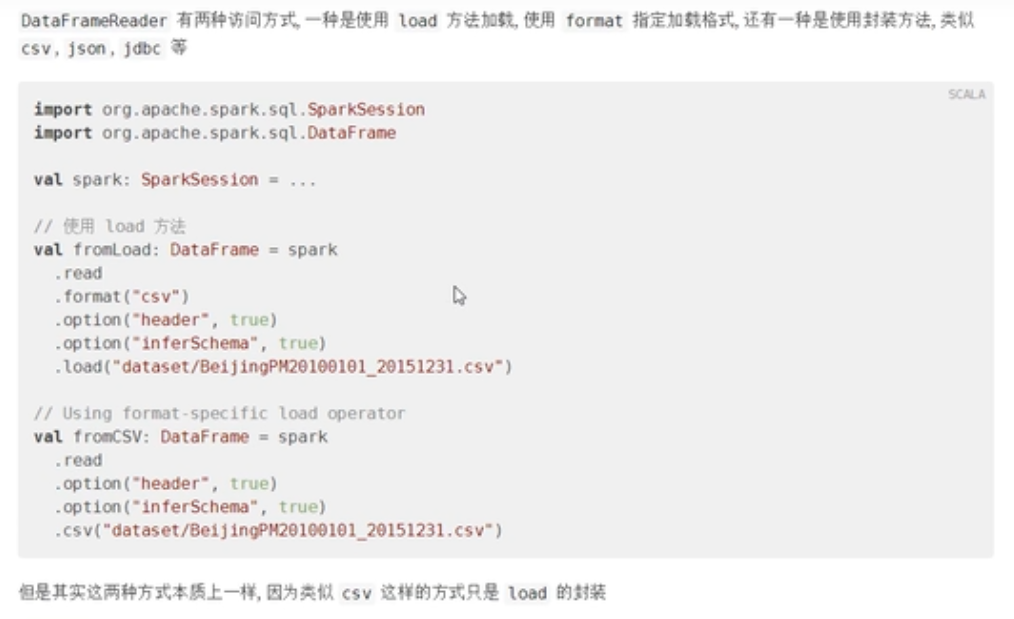
text数据读取
SparkSession加载文本文件数据,提供两种方法,返回值分别为DataFrame和Dataset
object Test20 {
def main(args: Array[String]): Unit = {
//1.准备SparkSQL开发环境
val spark: SparkSession = SparkSession.builder().appName("hello").master("local[*]").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
val frame: DataFrame = spark.read.text("D:\\soft\\idea\\work\\work04\\src\\main\\resources\\person")
spark.read
.format("text")
.load("D:\\soft\\idea\\work\\work04\\src\\main\\resources\\person")
.show(3)
//frame.show(3)
//5.关闭资源
sc.stop()
spark.stop()
}
}可以查看一下底层源码
//text方法返回的是DataFrame
def text(path: String): DataFrame = {
// This method ensures that calls that explicit need single argument works, see SPARK-16009
text(Seq(path): _*)
}
可以看出textFile方法底层还是调用text方法,先加载数据封装到DataFrame中,再使用as[String]方法将DataFrame转换为Dataset,实际中推荐使用textFile方法,从Spark 2.0开始提供。
无论是text方法还是textFile方法读取文本数据时,一行一行的加载数据,每行数据使用UTF-8编码的字符串,列名称为【value】。
Json数据读取
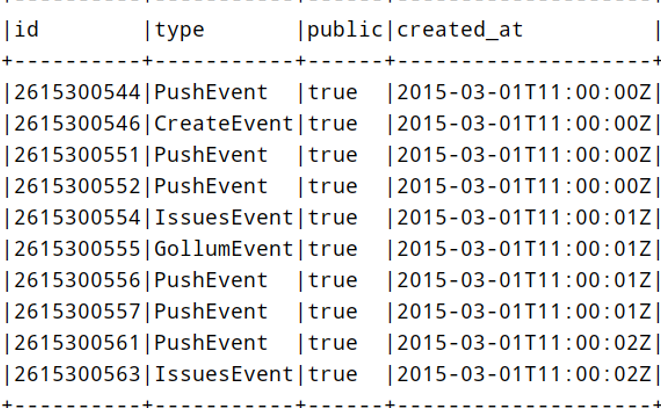
实际项目中,有时处理数据以JSON格式存储的,尤其后续结构化流式模块:StructuredStreaming,从Kafka Topic消费数据很多时间是JSON个数据,封装到DataFrame中,需要解析提取字段的值。以读取github操作日志JSON数据为例,数据结构如下:
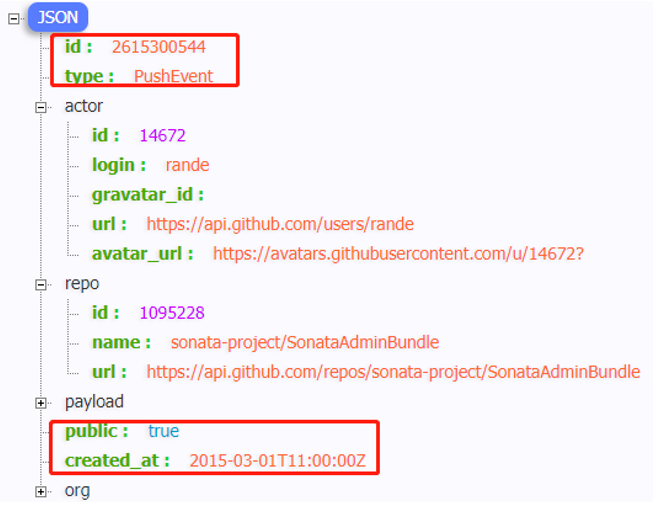
使用textFile加载数据,对每条JSON格式字符串数据,使用SparkSQL函数库functions中自带get_json_obejct函数提取字段:id、type、public和created_at的值。
函数:get_json_obejct使用说明

object Test21 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[*]")
// 通过装饰模式获取实例对象,此种方式为线程安全的
.getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
import spark.implicits._
// TODO: 从LocalFS上读取json格式数据(压缩)
val jsonDF: DataFrame = spark.read.json("data/input/2015-03-01-11.json.gz")
//jsonDF.printSchema()
jsonDF.show(5, truncate = true)
println("===================================================")
val githubDS: Dataset[String] = spark.read.textFile("data/input/2015-03-01-11.json.gz")
//githubDS.printSchema() // value 字段名称,类型就是String
githubDS.show(5,truncate = true)
// TODO:使用SparkSQL自带函数,针对JSON格式数据解析的函数
import org.apache.spark.sql.functions._
// 获取如下四个字段的值:id、type、public和created_at
val gitDF: DataFrame = githubDS.select(
get_json_object($"value", "$.id").as("id"),
get_json_object($"value", "$.type").as("type"),
get_json_object($"value", "$.public").as("public"),
get_json_object($"value", "$.created_at").as("created_at")
)
gitDF.printSchema()
gitDF.show(10, truncate = false)
// 应用结束,关闭资源
spark.stop()
}
}运行结果展示
CSV格式
在机器学习中,常常使用的数据存储在csv/tsv文件格式中,所以SparkSQL中也支持直接读取格式数据,从2.0版本开始内置数据源。关于CSV/TSV格式数据说明:

SparkSQL中读取CSV格式数据,可以设置一些选项,重点选项:
分隔符:sep
默认值为逗号,必须单个字符
数据文件首行是否是列名称:header
默认值为false,如果数据文件首行是列名称,设置为true
是否自动推断每个列的数据类型:inferSchema
默认值为false,可以设置为true
当读取CSV/TSV格式数据文件首行是否是列名称,读取数据方式(参数设置)不一样的
- 行是列的名称,如下方式读取数据文件
// TODO: 读取TSV格式数据
val ratingsDF: DataFrame = spark.read
// 设置每行数据各个字段之间的分隔符, 默认值为 逗号
.option("sep", "\t")
// 设置数据文件首行为列名称,默认值为 false
.option("header", "true")
// 自动推荐数据类型,默认值为false
.option("inferSchema", "true")
// 指定文件的路径
.csv("datas/ml-100k/u.dat")
ratingsDF.printSchema()
ratingsDF.show(10, truncate = false)- 首行不是列的名称,如下方式读取数据(设置Schema信息)
// 定义Schema信息
val schema = StructType(
StructField("user_id", IntegerType, nullable = true) ::
StructField("movie_id", IntegerType, nullable = true) ::
StructField("rating", DoubleType, nullable = true) ::
StructField("timestamp", StringType, nullable = true) :: Nil
)
// TODO: 读取TSV格式数据
val mlRatingsDF: DataFrame = spark.read
// 设置每行数据各个字段之间的分隔符, 默认值为 逗号
.option("sep", "\t")
// 指定Schema信息
.schema(schema)
// 指定文件的路径
.csv("datas/ml-100k/u.data")
mlRatingsDF.printSchema()
mlRatingsDF.show(5, truncate = false)- 将DataFrame数据保存至CSV格式文件,演示代码如下:
mlRatingsDF
// 降低分区数,此处设置为1,将所有数据保存到一个文件中
.coalesce(1)
.write
// 设置保存模式,依据实际业务场景选择,此处为覆写
.mode(SaveMode.Overwrite)
.option("sep", ",")
// TODO: 建议设置首行为列名
.option("header", "true")
.csv("datas/ml-csv-" + System.nanoTime())案例
object Test22 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[*]")
// 通过装饰模式获取实例对象,此种方式为线程安全的
.getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
import spark.implicits._
/**
* 实际企业数据分析中
* csv\tsv格式数据,每个文件的第一行(head, 首行),字段的名称(列名)
*/
// TODO: 读取CSV格式数据
val ratingsDF: DataFrame = spark.read
// 设置每行数据各个字段之间的分隔符, 默认值为 逗号
.option("sep", "\t")
// 设置数据文件首行为列名称,默认值为 false
.option("header", "true")
// 自动推荐数据类型,默认值为false
.option("inferSchema", "true")
// 指定文件的路径
.csv("data/input/rating_100k_with_head.data")
ratingsDF.printSchema()
ratingsDF.show(10, truncate = false)
println("=======================================================")
// 定义Schema信息
val schema = StructType(
StructField("user_id", IntegerType, nullable = true) ::
StructField("movie_id", IntegerType, nullable = true) ::
StructField("rating", DoubleType, nullable = true) ::
StructField("timestamp", StringType, nullable = true) :: Nil
)
// TODO: 读取CSV格式数据
val mlRatingsDF: DataFrame = spark.read
// 设置每行数据各个字段之间的分隔符, 默认值为 逗号
.option("sep", "\t")
// 指定Schema信息
.schema(schema)
// 指定文件的路径
.csv("data/input/rating_100k.data")
mlRatingsDF.printSchema()
mlRatingsDF.show(10, truncate = false)
println("=======================================================")
/**
* 将电影评分数据保存为CSV格式数据
*/
mlRatingsDF
// 降低分区数,此处设置为1,将所有数据保存到一个文件中
.coalesce(1)
.write
// 设置保存模式,依据实际业务场景选择,此处为覆写
.mode(SaveMode.Overwrite)
.option("sep", ",")
// TODO: 建议设置首行为列名
.option("header", "true")
.csv("data/output/ml-csv-" + System.currentTimeMillis())
// 关闭资源
spark.stop()
}
}Parquet数据
SparkSQL模块中默认读取数据文件格式就是parquet列式存储数据,通过参数【spark.sql.sources.default】设置,默认值为【parquet】。
object SparkSQLParquet {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[*]")
// 通过装饰模式获取实例对象,此种方式为线程安全的
.getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
import spark.implicits._
// TODO: 从LocalFS上读取parquet格式数据
val usersDF: DataFrame = spark.read.parquet("data/input/users.parquet")
usersDF.printSchema()
usersDF.show(10, truncate = false)
println("==================================================")
// SparkSQL默认读取文件格式为parquet
val df = spark.read.load("data/input/users.parquet")
df.printSchema()
df.show(10, truncate = false)
// 应用结束,关闭资源
spark.stop()
}
}结果

jdbc数据
回顾在SparkCore中读取MySQL表的数据通过JdbcRDD来读取的,在SparkSQL模块中提供对应接口,提供三种方式读取数据:
- 单分区模式

- 多分区模式,可以设置列的名称,作为分区字段及列的值范围和分区数目

- 高度自由分区模式,通过设置条件语句设置分区数据及各个分区数据范围

当加载读取RDBMS表的数据量不大时,可以直接使用单分区模式加载;当数据量很多时,考虑使用多分区及自由分区方式加载。
从RDBMS表中读取数据,需要设置连接数据库相关信息,基本属性选项如下:

代码演示
// 连接数据库三要素信息
val url: String = "jdbc:mysql://node1.itcast.cn:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true"
val table: String = "db_shop.so"
// 存储用户和密码等属性
val props: Properties = new Properties()
props.put("driver", "com.mysql.cj.jdbc.Driver")
props.put("user", "root")
props.put("password", "123456")
// TODO: 从MySQL数据库表:销售订单表 so
// def jdbc(url: String, table: String, properties: Properties): DataFrame
val sosDF: DataFrame = spark.read.jdbc(url, table, props)
println(s"Count = ${sosDF.count()}")
sosDF.printSchema()
sosDF.show(10, truncate = false)可以使用option方法设置连接数据库信息,而不使用Properties传递,代码如下:
// TODO: 使用option设置参数
val dataframe: DataFrame = spark.read
.format("jdbc")
.option("driver", "com.mysql.cj.jdbc.Driver")
.option("url", "jdbc:mysql://node1.itcast.cn:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true")
.option("user", "root")
.option("password", "123456")
.option("dbtable", "db_shop.so")
.load()
dataframe.show(5, truncate = false)数据读取框架案例
object Test10 {
def main(args: Array[String]): Unit = {
// 1 创建sparksession
val spark: SparkSession = SparkSession.builder()
.appName("dataframe")
.master("local[6]")
.getOrCreate()//创建sparksession的对象
//第一种读取形式
spark.read
.format("csv")//设置文件的格式
.option("header",true)//设置表头信息
.option("inferScheme",value = true)//设置自动推断数据类型,也就是说schema是来自csv文件当中的
.load("")//读取数据的路径
.show(10)//查看10条数据
// 第二种读取形式
spark.read
.option("header",true)//设置表头信息
.option("inferScheme",value = true)//设置自动推断数据类型,也就是说schema是来自csv文件当中的
.csv("")
.show(10)
}
}但是这两种方法本质上是一致的,因为类似csv这样的方式只是load()方法的封装。可以从下面的源码看出来:
def csv(paths: String*): DataFrame = format("csv").load(paths : _*)如果使用load()方式加载数据,但是没有指定format的话,默认是按照Parquet的格式读取文件。
也就是说sparksql默认读取文件的格式是Parquet格式。
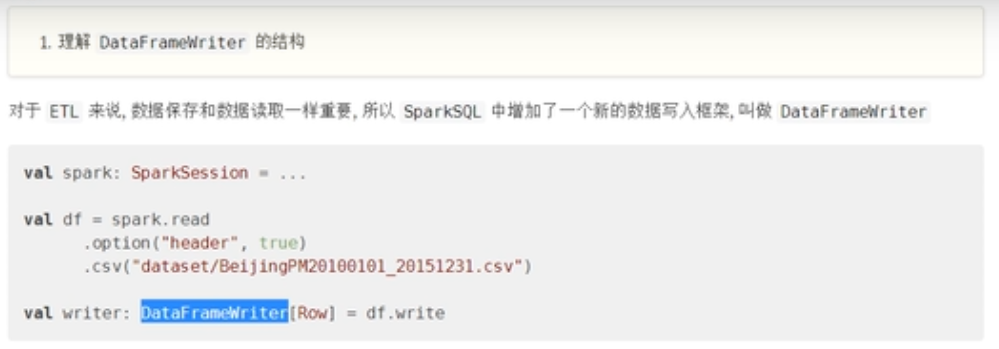
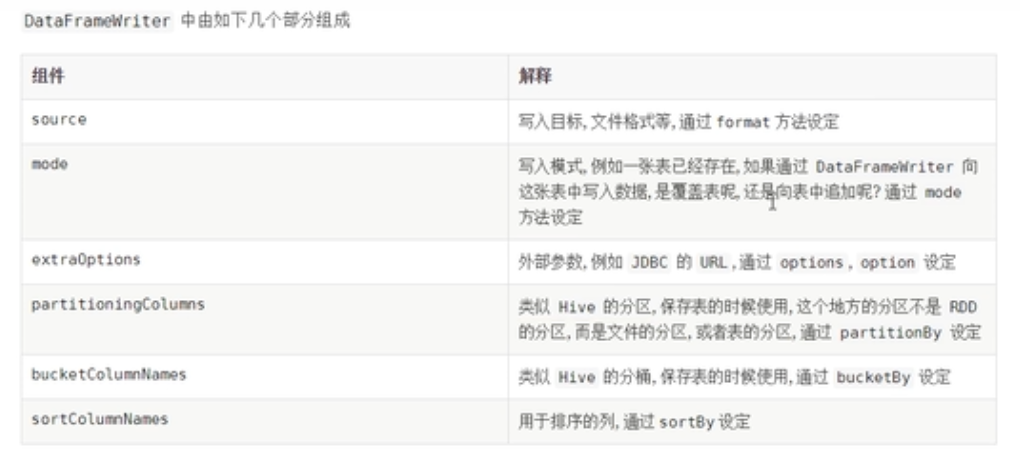
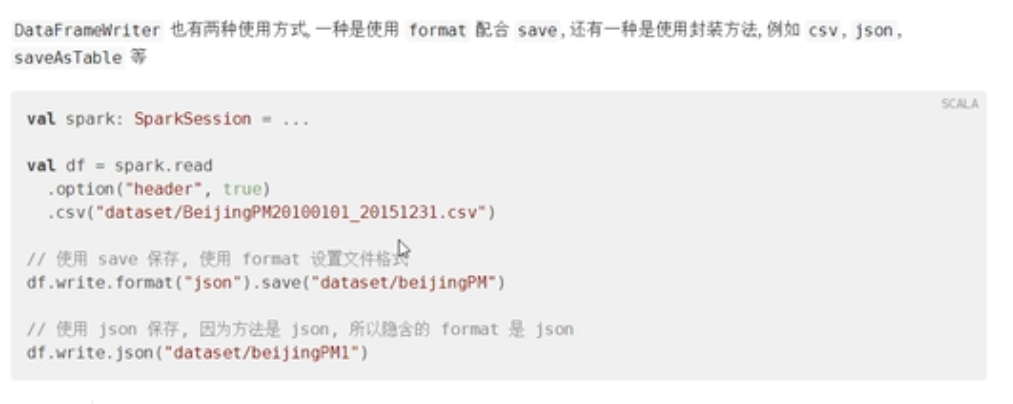
DataFrameWriter
SparkSQL提供一套通用外部数据源接口,方便用户从数据源加载和保存数据,例如从MySQL表中既可以加载读取数据:load/read,又可以保存写入数据:save/write。

由于SparkSQL没有内置支持从HBase表中加载和保存数据,但是只要实现外部数据源接口,也能像上面方式一样读取加载数据。
写入模式
案例
object Test11 {
def main(args: Array[String]): Unit = {
// 1 创建sparksession
val spark: SparkSession = SparkSession.builder()
.appName("dataframe")
.master("local[6]")
.getOrCreate()//创建sparksession的对象
//读取一个文件
val df: DataFrame = spark.read
.format("csv") //设置文件的格式
.option("header", true) //设置表头信息
.load("")//读取数据的路径
// 写入文件
val json: Unit = df.write
.json("")
// 第二种写入方式
df.write
.format("json")
.save("")
}
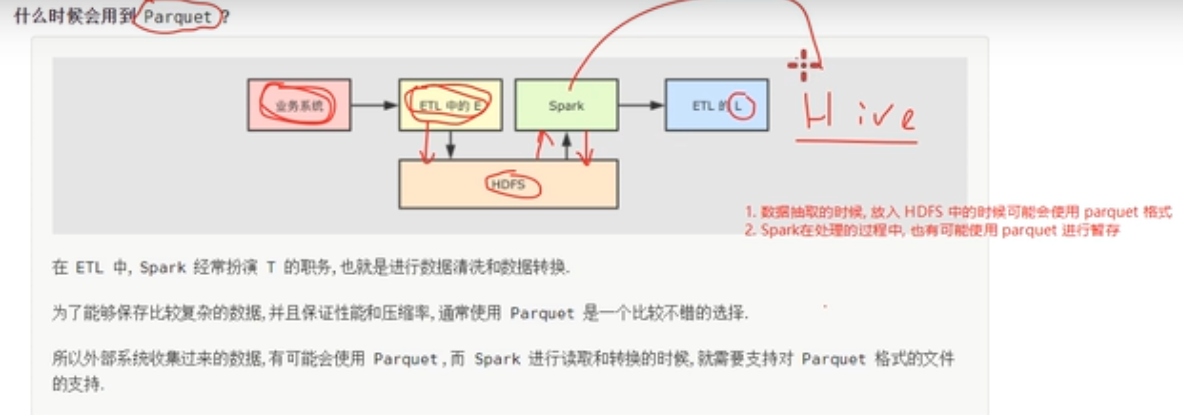
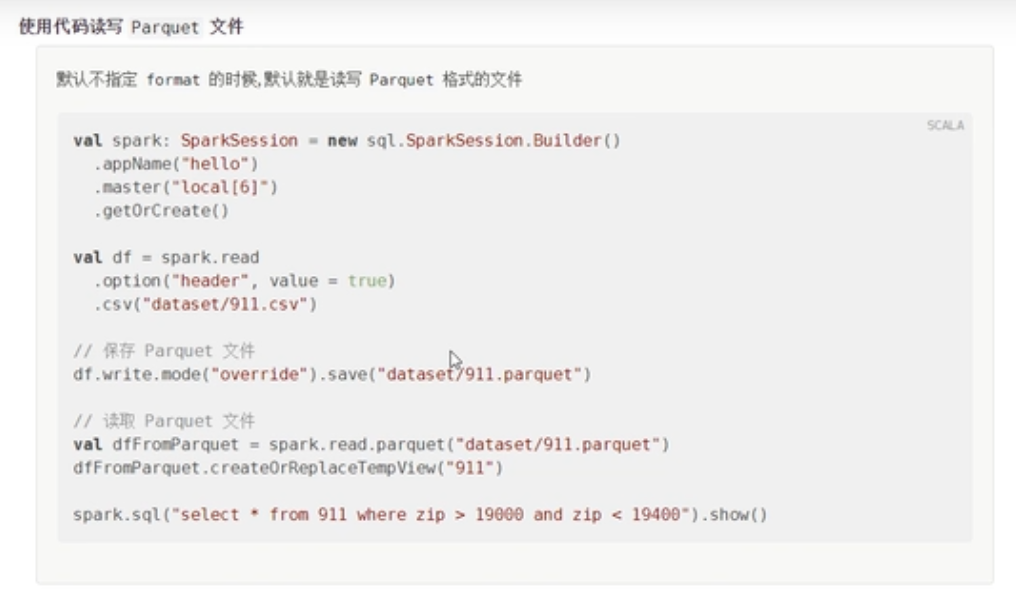
}Parquet文件格式
Parquet文件
文件的读取
object Test12 {
def main(args: Array[String]): Unit = {
// 1 创建sparksession
val spark: SparkSession = SparkSession.builder()
.appName("dataframe")
.master("local[6]")
.getOrCreate()//创建sparksession的对象
val df: DataFrame = spark.read
.option("header", true)
.csv("")
// 数据存储为parquet格式
df.write//spark默认写入文件的格式是parquet格式
.mode(SaveMode.Overwrite)//指定写入模式为重写
.format("parquet").save("")
// 读取parquet格式的文件
// 默认的读取格式也是parquet格式文件
// 可以读取文件夹
spark.read
.format("json")
.load("")
}
}spark默认读取和写入的都是parquet格式的文件。
在写入的时候,会写入文件夹内,因为spark是支持分区操作单位,每一个分区会写入一个文件夹内。
读取数据的时候也是按照分区进行读取的,逐个文件夹进行遍历读取操作。
写入文件指定分区
为什么要进行分区?

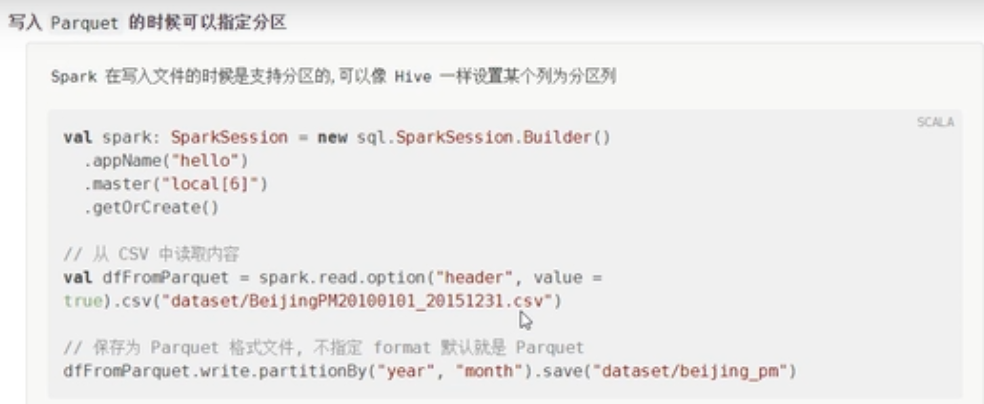
表分区不仅在parquet格式的文件上面有,在其他格式的文件也有分区。
object Test13 {
def main(args: Array[String]): Unit = {
// 1 创建sparksession
val spark: SparkSession = SparkSession.builder()
.appName("dataframe")
.master("local[6]")
.getOrCreate()//创建sparksession的对象
val df: DataFrame = spark.read
.option("header", true)
.csv("")
// 写文件,表分区
// 写分区表的时候,分区列不会包含在生成的文件中,仅仅显示在文件夹上面
// 读取的时候,自然也读取不到分区信息
df.write
//这里是按照列进行分区操作
.partitionBy("year","month")//按照年和月进行分区
.save("")
// 读取文件,自行发现分区
// 如果读取的时候没有指定具体的分区,而是指定分区的文件夹,那么会自动的发现分区,这个时候
// 分区列也会输出在文件中
spark.read
.parquet("")//这里需要指定具体分区的路径
.printSchema()//打印表头信息
}
}JSON格式文件
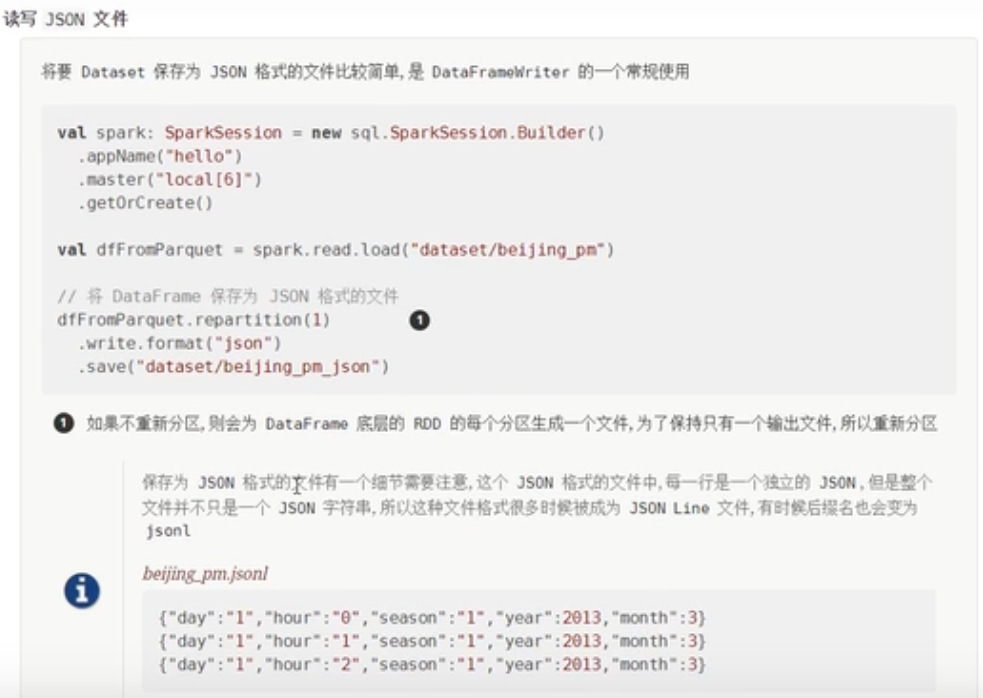
object Test14 {
def main(args: Array[String]): Unit = {
// 1 创建sparksession
val spark: SparkSession = SparkSession.builder()
.appName("dataframe")
.master("local[6]")
.getOrCreate()//创建sparksession的对象
val df: DataFrame = spark.read
.option("header", true)
.csv("")
// 写入外部的时候,以json方式写入
//但是写入的不是标准格式的json文件
df.write
.json("")
}
}处理json文件格式的小技巧
- toJSON():可以将一个DataFrame(里面存储的是对象)转换为JSON格式的DataFrame(也就是json字符串)
- toJSON()应用场景:处理完数据之后,DataFrame中如果是一个对象,如果其他的系统只支持json格式的数据,sparksql和这种系统进行整合的时候,那么就需要这种形式的转换。
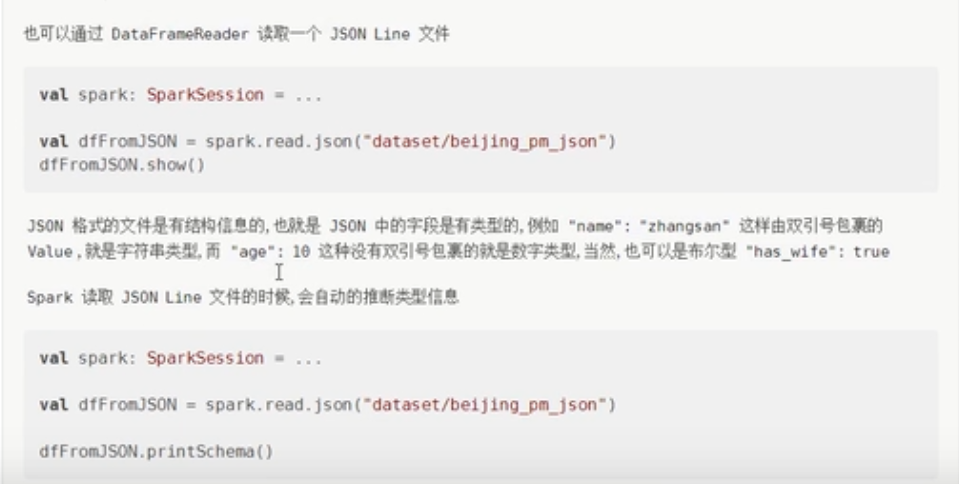
df.toJSON.show()- 可以直接从RDD读取JSON格式的DataFrame
//将json格式的数据转换为一个RDD
val rdd: RDD[String] = df.toJSON.rdd
//从rdd中读取出一个dataframe
val frame: DataFrame = spark.read.json(rdd)
加载/保存数据-API
SparkSQL提供一套通用外部数据源接口,方便用户从数据源加载和保存数据,例如从MySQL表中既可以加载读取数据:load/read,又可以保存写入数据:save/write。

由于SparkSQL没有内置支持从HBase表中加载和保存数据,但是只要实现外部数据源接口,也能像上面方式一样读取加载数据。
Load加载数据
在SparkSQL中读取数据使用SparkSession读取,并且封装到数据结构Dataset/DataFrame中。
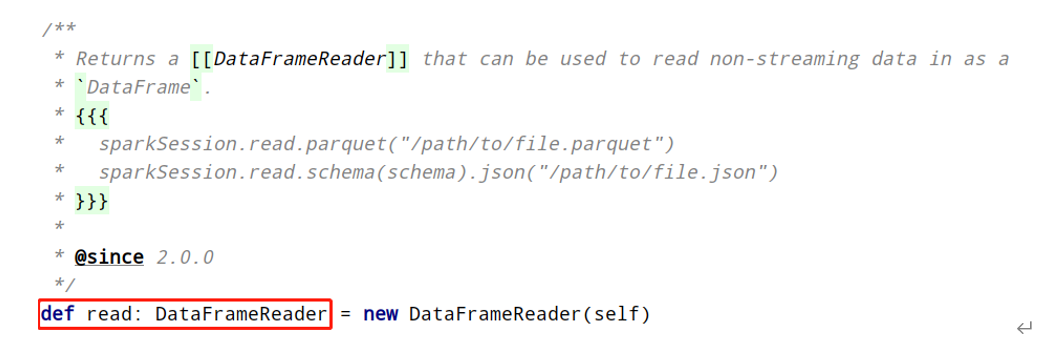
DataFrameReader专门用于加载load读取外部数据源的数据,基本格式如下:

SparkSQL模块本身自带支持读取外部数据源的数据:

总结起来三种类型数据,也是实际开发中常用的:
文件格式数据
文本文件text、csv文件和json文件
列式存储数据
Parquet格式、ORC格式
数据库表
关系型数据库RDBMS:MySQL、DB2、Oracle和MSSQL
此外加载文件数据时,可以直接使用SQL语句,指定文件存储格式和路径:

Save保存数据
SparkSQL模块中可以从某个外部数据源读取数据,就能向某个外部数据源保存数据,提供相应接口,通过DataFrameWrite类将数据进行保存。

与DataFrameReader类似,提供一套规则,将数据Dataset保存,基本格式如下:

SparkSQL模块内部支持保存数据源如下: 
所以使用SpakrSQL分析数据时,从数据读取,到数据分析及数据保存,链式操作,更多就是ETL操作。当将结果数据DataFrame/Dataset保存至Hive表中时,可以设置分区partition和分桶bucket,形式如下:

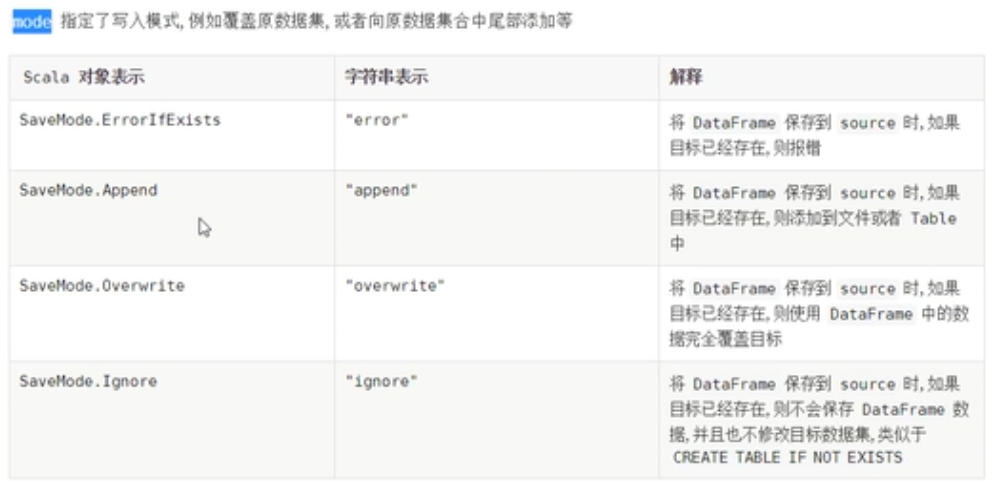
保存模式(SaveMode)
将Dataset/DataFrame数据保存到外部存储系统中,考虑是否存在,存在的情况下的下如何进行保存,DataFrameWriter中有一个mode方法指定模式:
通过源码发现SaveMode时枚举类,使用Java语言编写,如下四种保存模式:
- Append 追加模式,当数据存在时,继续追加;
- Overwrite 覆写模式,当数据存在时,覆写以前数据,存储当前最新数据;
- ErrorIfExists 存在及报错;
- Ignore 忽略,数据存在时不做任何操作;
实际项目依据具体业务情况选择保存模式,通常选择Append和Overwrite模式。
小项目
数据格式
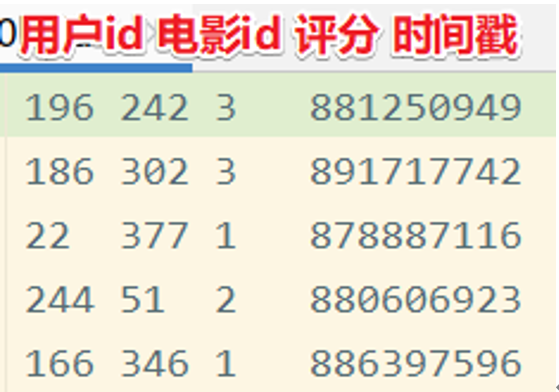
需求
对电影评分数据进行统计分析,分别使用DSL编程和SQL编程,获取电影平均分Top10,要求电影的评分次数大于200。
代码实现
object SparkSQLDemo06_MovieTop10 {
def main(args: Array[String]): Unit = {
//1.准备SparkSQL开发环境
val spark: SparkSession = SparkSession.builder().appName("SparkSQL").master("local[*]").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
import spark.implicits._
//2.获取DF/DS
//也可以用rdd-->df
val fileDS: Dataset[String] = spark.read.textFile("data/input/rating_100k.data")
val rowDS: Dataset[(Int, Int)] = fileDS.map(line => {
val arr: Array[String] = line.split("\t")
(arr(1).toInt, arr(2).toInt)
})
val cleanDF: DataFrame = rowDS.toDF("mid","score")
cleanDF.printSchema()
cleanDF.show(false)
/*
+----+-----+
|mid |score|
+----+-----+
|242 |3 |
|302 |3 |
|377 |1 |
|51 |2 |
|346 |1 |
...
*/
//3.完成需求:统计评分次数>200的电影的平均分最高的Top10
//TODO SQL
cleanDF.createOrReplaceTempView("t_scores")
val sql:String =
"""
|select mid, round(avg(score),2) avg,count(*) counts
|from t_scores
|group by mid
|having counts > 200
|order by avg desc,counts desc
|limit 10
|""".stripMargin
spark.sql(sql).show(false)
//TODO DSL
import org.apache.spark.sql.functions._
cleanDF
.groupBy("mid")
.agg(
round(avg('score),2) as "avg",
count('mid) as "counts"
)//聚合函数可以写在这里
.orderBy('avg.desc,'counts.desc)
.filter('counts > 200)
.limit(10)
.show(false)
/*
+---+----+------+
|mid|avg |counts|
+---+----+------+
|318|4.47|298 |
|483|4.46|243 |
|64 |4.45|283 |
|12 |4.39|267 |
|603|4.39|209 |
|50 |4.36|583 |
|98 |4.29|390 |
|357|4.29|264 |
|427|4.29|219 |
|127|4.28|413 |
+---+----+------+
*/
//4.关闭资源
sc.stop()
spark.stop()
}
}扩展阅读:Catalyst 优化器
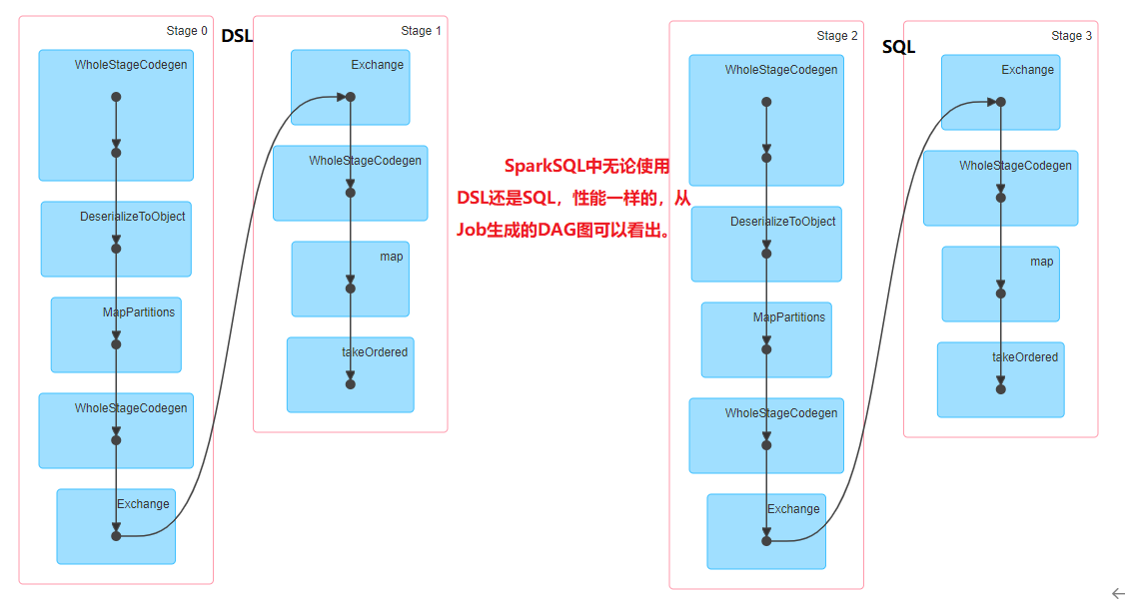
在上面案例中,运行应用程序代码,通过WEB UI界面监控可以看出,无论使用DSL还是SQL,构建Job的DAG图一样的,性能是一样的,原因在于SparkSQL中引擎:Catalyst:将SQL和DSL转换为相同逻辑计划。
Spark SQL是Spark技术最复杂的组件之一,Spark SQL的核心是Catalyst优化器,它以一种新颖的方式利用高级编程语言功能(例如Scala的模式匹配和quasiquotes)来构建可扩展的查询优化器。
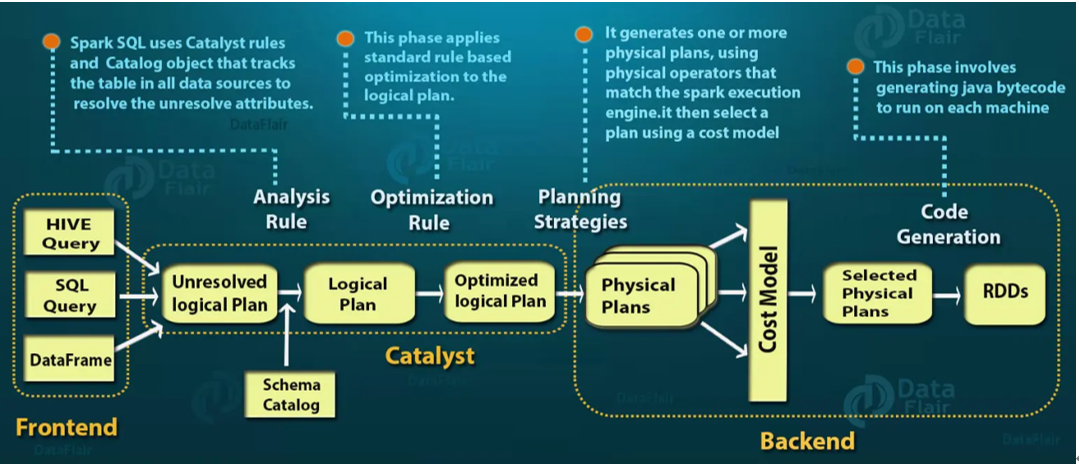
SparkSQL的Catalyst优化器是整个SparkSQL pipeline的中间核心部分,其执行策略主要两方向:
- 基于规则优化/Rule Based Optimizer/RBO;
- 基于代价优化/Cost Based Optimizer/CBO;
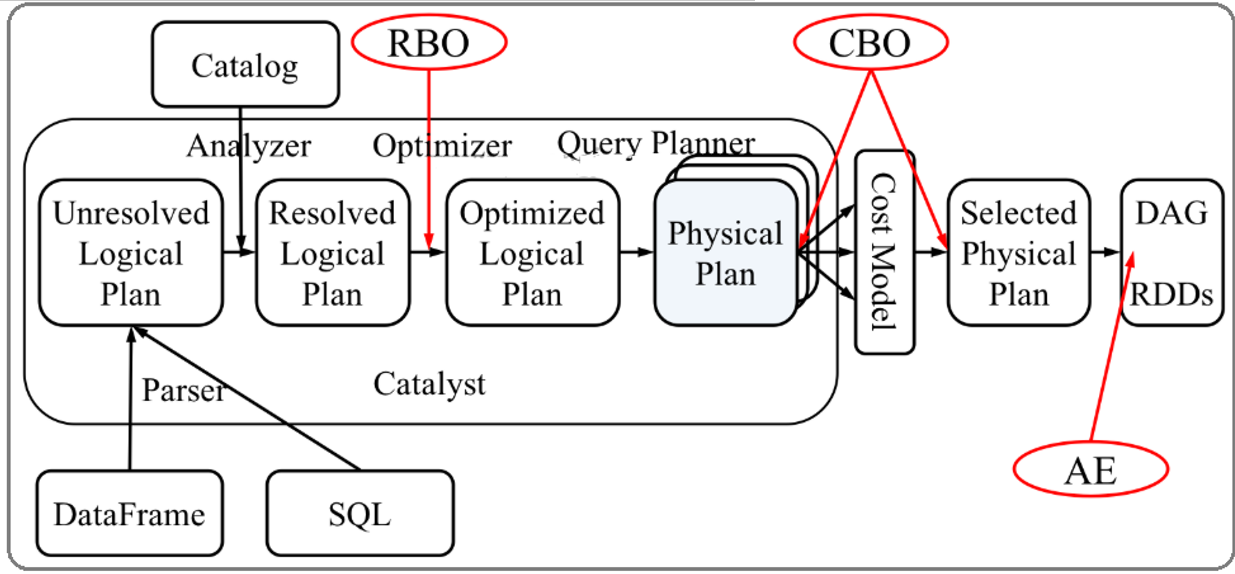
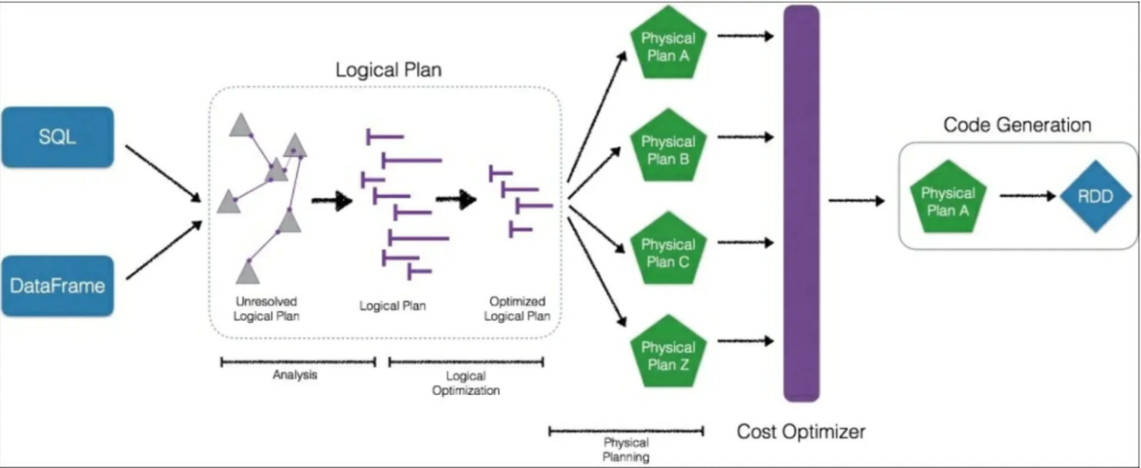
从上图可见,无论是直接使用SQL语句还是使用 ataFrame,都会经过一些列步骤转换成DAG对RDD的操作。
Catalyst工作流程:
- SQL语句首先通过Parser模块被解析为语法树,此棵树称为Unresolved Logical Plan;
- Unresolved Logical Plan通过Analyzer模块借助于数据元数据解析为Logical Plan;
- 此时再通过各种基于规则的Optimizer进行深入优化,得到Optimized Logical Plan;
- 优化后的逻辑执行计划依然是逻辑的,需要将逻辑计划转化为Physical Plan。
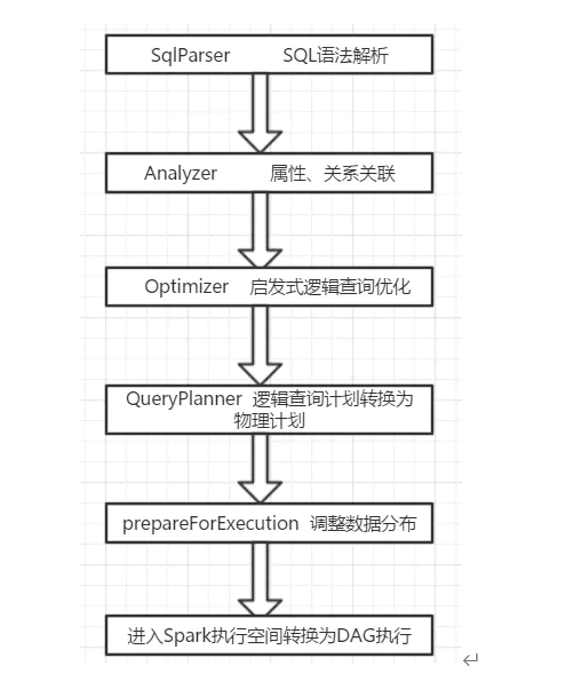
Catalyst的三个核心点:
- Parser,第三方类库ANTLR实现。将sql字符串切分成Token,根据语义规则解析成一颗AST语法树;
- Analyzer,Unresolved Logical Plan,进行数据类型绑定和函数绑定;
- Optimizer,规则优化就是模式匹配满足特定规则的节点等价转换为另一颗语法树;
SparkSQL自定义UDF函数
无论Hive还是SparkSQL分析处理数据时,往往需要使用函数,SparkSQL模块本身自带很多实现公共功能的函数,在org.apache.spark.sql.functions中。SparkSQL与Hive一样支持定义函数:UDF和UDAF,尤其是UDF函数在实际项目中使用最为广泛。
回顾Hive中自定义函数有三种类型:
1:UDF(User-Defined-Function) 函数 一对一的关系,输入一个值经过函数以后输出一个值; 在Hive中继承UDF类,方法名称为evaluate,返回值不能为void,其实就是实现一个方法;
2:UDAF(User-Defined Aggregation Function) 聚合函数 多对一的关系,输入多个值输出一个值,通常与groupBy联合使用;
3:UDTF(User-Defined Table-Generating Functions) 函数一对多的关系,输入一个值输出多个值(一行变为多行); 用户自定义生成函数,有点像flatMap;
注意:在SparkSQL中,目前仅仅支持UDF函数和UDAF函数
目前来说Spark 框架各个版本及各种语言对自定义函数的支持:
如何自定义函数
UDF函数也有DSL和SQL两种方式
SQL方式
使用SparkSession中udf方法定义和注册函数,在SQL中使用,使用如下方式定义:

DSL方式
使用org.apache.sql.functions.udf函数定义和注册函数,在DSL中使用,如下方式:

案例
object SparkSQLDemo08_UDF {
def main(args: Array[String]): Unit = {
//1.准备SparkSQL开发环境
val spark: SparkSession = SparkSession.builder().appName("hello").master("local[*]").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
import org.apache.spark.sql.functions._
import spark.implicits._
//2.获取数据DF->DS->RDD
val df: DataFrame = spark.read.text("data/input/udf.txt")
df.printSchema()
df.show(false)
/*
root
|-- value: string (nullable = true)
+-----+
|value|
+-----+
|hello|
|haha |
|hehe |
|xixi |
+-----+
*/
//TODO =======SQL风格=======
//3.自定义UDF:String-->大写
spark.udf.register("small2big",(value:String)=>{
value.toUpperCase
})
//4.执行查询转换
df.createOrReplaceTempView("t_words")
val sql =
"""
|select value,small2big(value) big_value
|from t_words
|""".stripMargin
spark.sql(sql).show(false)
//TODO =======DSL风格=======
//3.自定义UDF:String-->大写
//4.执行查询转换
val small2big2 = udf((value:String)=>{
value.toUpperCase
})
df.select('value,small2big2('value).as("big_value2")).show(false)
//5.关闭资源
sc.stop()
spark.stop()
}
}Spark On Hive
Spark SQL模块从发展来说,从Apache Hive框架而来,发展历程:Hive(MapReduce)-> Shark (Hive on Spark) -> Spark SQL(SchemaRDD -> DataFrame -> Dataset), SparkSQL天然无缝集成Hive,可以加载Hive表数据进行分析。
HiveOnSpark和SparkOnHive
HiveOnSpark:SparkSql诞生之前的Shark项目使用的,是把Hive的执行引擎换成Spark,剩下的使用Hive的,严重依赖Hive,早就淘汰了没有人用了
SparkOnHive:SparkSQL诞生之后,Spark提出的,是仅仅使用Hive的元数据(库/表/字段/位置等信息...),剩下的用SparkSQL的,如:执行引擎,语法解析,物理执行计划,SQL优化
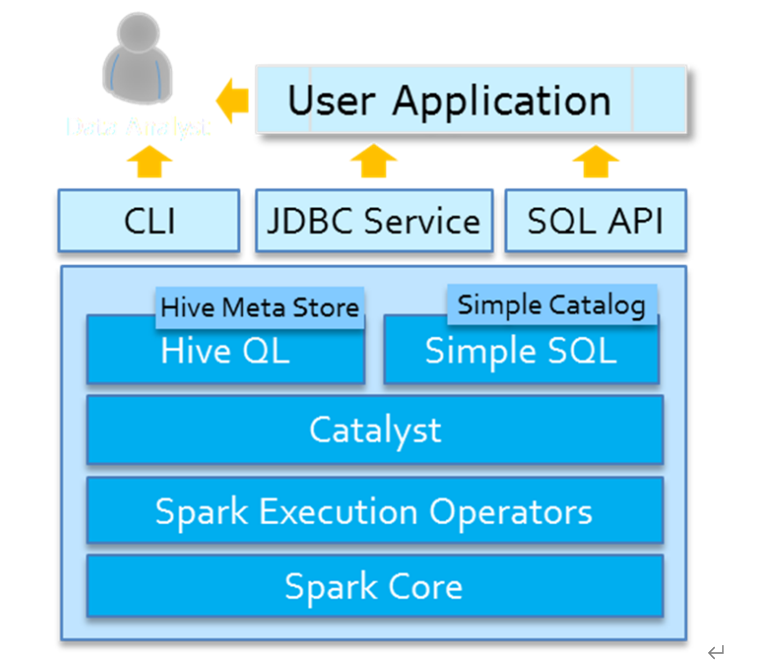
spark-sql中集成Hive
本质
SparkSQL集成Hive本质就是:SparkSQL读取Hive的元数据MetaStore
操作
1、启动Hive的元数据库服务
hive所在机器node2上启动
nohup /export/server/hive/bin/hive --service metastore &
注意:Spark3.0需要Hive2.3.7版本
2、告诉SparkSQL:Hive的元数据库在哪里
哪一台机器需要使用spark-sql命令行整合hive就把下面的配置放在哪一台
也可以将hive-site.xml分发到集群中所有Spark的conf目录,此时任意机器启动应用都可以访问Hive表数据。
cd /export/server/spark/conf/ vim hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node2:9083</value>
</property>
</configuration>使用sparksql操作hive
/export/server/spark/bin/spark-sql --master local[2] --conf spark.sql.shuffle.partitions=2
show databases;
show tables;
CREATE TABLE person3 (id int, name string, age int) row format delimited fields terminated by ' ';
LOAD DATA LOCAL INPATH 'file:///root/person.txt'
INTO TABLE person3;
show tables;
select * from person3;Spark代码中集成Hive
操作
1.开启hive元数据库
nohup /export/server/hive/bin/hive --service metastore &
2.添加依赖
<!--SparkSQL+ Hive依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>${spark.version}</version>
</dependency>3.在代码中告诉SparkSQL:Hive的元数据服务的配置
SparkSQL-OnHive的元数据库(语法解析,物理执行计划生成,执行引擎,SQL优化都是用的Spark的。
完整代码
object SparkSQLDemo09_SparkOnHive {
def main(args: Array[String]): Unit = {
//1.准备SparkSQL开发环境
val spark: SparkSession = SparkSession.builder().appName("SparkSQL").master("local[*]")
.config("spark.sql.shuffle.partitions", "4")//默认是200,本地测试给少一点
.config("spark.sql.warehouse.dir", "hdfs://node1:8020/user/hive/warehouse")//指定Hive数据库在HDFS上的位置
.config("hive.metastore.uris", "thrift://node2:9083")
.enableHiveSupport()//开启对hive语法的支持
.getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2.执行Hive-SQL
spark.sql("show databases").show(false)
spark.sql("show tables").show(false)
spark.sql("CREATE TABLE person2 (id int, name string, age int) row format delimited fields terminated by ' '")
spark.sql("LOAD DATA LOCAL INPATH 'file:///D:/person.txt' INTO TABLE person2")
spark.sql("show tables").show(false)
spark.sql("select * from person2").show(false)
//5.关闭资源
sc.stop()
spark.stop()
}
}贡献者
 codingLab
codingLab版权所有
版权归属:
许可证: