7、SparkSql实战
SparkSql实战
准备工作
添加依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.5</version>
</dependency>SparkSession应用入口
Spark 2.0开始,SparkSession取代了原本的SQLContext与HiveContext作为SparkSQL应用程序的入口,可以加载不同数据源的数据,封装到DataFrame/Dataset集合数据结构中,使得编程更加简单,程序运行更加快速高效。注意原本的SQLContext与HiveContext仍然保留,以支持向下兼容。
SparkSql初体验
SparkSession对象实例通过建造者模式构建,代码如下:
其中
①表示导入SparkSession所在的包,
②表示建造者模式构建对象和设置属性,
③表示导入SparkSession类中implicits对象object中隐式转换函数。

object SparkSQLDemo00_hello {
def main(args: Array[String]): Unit = {
//1.准备SparkSQL开发环境
println(this.getClass.getSimpleName)
println(this.getClass.getSimpleName.stripSuffix("$"))
val spark: SparkSession = SparkSession.builder().appName(this.getClass.getSimpleName.stripSuffix("$")).master("local[*]").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
val df1: DataFrame = spark.read.text("data/input/text")
val df2: DataFrame = spark.read.json("data/input/json")
val df3: DataFrame = spark.read.csv("data/input/csv")
val df4: DataFrame = spark.read.parquet("data/input/parquet")
df1.printSchema()
df1.show(false)
df2.printSchema()
df2.show(false)
df3.printSchema()
df3.show(false)
df4.printSchema()
df4.show(false)
df1.coalesce(1).write.mode(SaveMode.Overwrite).text("data/output/text")
df2.coalesce(1).write.mode(SaveMode.Overwrite).json("data/output/json")
df3.coalesce(1).write.mode(SaveMode.Overwrite).csv("data/output/csv")
df4.coalesce(1).write.mode(SaveMode.Overwrite).parquet("data/output/parquet")
//关闭资源
sc.stop()
spark.stop()
}
}获取DataFrame/DataSet
实际项目开发中,往往需要将RDD数据集转换为DataFrame,本质上就是给RDD加上Schema信息
使用样例类
当RDD中数据类型CaseClass样例类时,底层可以通过反射Reflecttion获取属性名称和类型,构建Schema,应用到RDD数据集,将其转换为DataFrame。
object Test15 {
def main(args: Array[String]): Unit = {
//1.准备SparkSQL开发环境
//注意:在新版的Spark中,使用SparkSession来进行SparkSQL开发!
//因为SparkSession封装了SqlContext、HiveContext、SparkContext
val spark: SparkSession = SparkSession.builder().appName("hello").master("local[*]").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2.获取RDD
val fileRDD: RDD[String] = sc.textFile("D:\\soft\\idea\\work\\work04\\src\\main\\resources\\person")
val personRDD: RDD[Person] = fileRDD.map(line => {
val arr: Array[String] = line.split(" ")
Person(arr(0).toInt, arr(1), arr(2).toInt)
})
//3.RDD->DataFrame/DataSet
import spark.implicits._ //隐式转换
//将RDD转换为DataFrame,是弱类型的
val df: DataFrame = personRDD.toDF()
//将RDD转换为Dataset,是强类型的
val ds: Dataset[Person] = personRDD.toDS()
//4.输出约束和类型
df.printSchema()
df.show()
ds.printSchema()
ds.show()
//5.关闭资源
sc.stop()
spark.stop()
}
case class Person(id:Int,name:String,age:Int)
}此种方式要求RDD数据类型必须为CaseClass,转换的DataFrame中字段名称就是CaseClass中属性名称。
指定类型+列名
SparkSQL中提供一个函数:toDF,通过指定列名称,将数据类型为元组的RDD或Seq转换为DataFrame,实际开发中也常常使用。
object Test16 {
def main(args: Array[String]): Unit = {
//1.准备SparkSQL开发环境
//注意:在新版的Spark中,使用SparkSession来进行SparkSQL开发!
//因为SparkSession封装了SqlContext、HiveContext、SparkContext
val spark: SparkSession = SparkSession.builder().appName("hello").master("local[*]").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2.获取RDD
val fileRDD: RDD[String] = sc.textFile("D:\\soft\\idea\\work\\work04\\src\\main\\resources\\person")
//tupleRDD: RDD[(Int, String, Int)]--指定类型:(Int, String, Int)
//将读取的数据转换为三元组格式
val tupleRDD: RDD[(Int, String, Int)] = fileRDD.map(line => {
val arr: Array[String] = line.split(" ")
(arr(0).toInt, arr(1), arr(2).toInt)
})
//3.RDD->DataFrame/DataSet
import spark.implicits._ //隐式转换
//指定列名
val df: DataFrame = tupleRDD.toDF("id","name","age")
//dataset没有这样的用法
//4.输出约束和类型
df.printSchema()
df.show()
//5.关闭资源
sc.stop()
spark.stop()
}
}自定义Schema
依据RDD中数据自定义Schema,类型为StructType,每个字段的约束使用StructField定义,具体步骤如下:
- RDD中数据类型为Row:RDD[Row];
- 针对Row中数据定义Schema:StructType;
- 使用SparkSession中方法将定义的Schema应用到RDD[Row]上;
object Test17 {
def main(args: Array[String]): Unit = {
//1.准备SparkSQL开发环境
//注意:在新版的Spark中,使用SparkSession来进行SparkSQL开发!
//因为SparkSession封装了SqlContext、HiveContext、SparkContext
val spark: SparkSession = SparkSession.builder().appName("hello").master("local[*]").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2.获取RDD
val fileRDD: RDD[String] = sc.textFile("D:\\soft\\idea\\work\\work04\\src\\main\\resources\\person")
//准备rowRDD:RDD[Row]
val rowRDD: RDD[Row] = fileRDD.map(line => {
val arr: Array[String] = line.split(" ")
Row(arr(0).toInt, arr(1), arr(2).toInt)
})
//准备Schema
/*val schema: StructType = StructType(
StructField("id", IntegerType, true) ::
StructField("name", StringType, true) ::
StructField("age", IntegerType, true) :: Nil)*/
val schema: StructType = StructType(
List(
StructField("id", IntegerType, true),
StructField("name", StringType, true),
StructField("age", IntegerType, true)
)
)
//3.RDD->DataFrame/DataSet
import spark.implicits._ //隐式转换
val df: DataFrame = spark.createDataFrame(rowRDD, schema)
//4.输出约束和类型
df.printSchema()
df.show()
//5.关闭资源
sc.stop()
spark.stop()
}
}此种方式可以更加体会到DataFrame = RDD[Row] + Schema组成,在实际项目开发中灵活的选择方式将RDD转换为DataFrame。
RDD、DF、DS相互转换
转换API
实际项目开发中,常常需要对RDD、DataFrame及Dataset之间相互转换,其中要点就是Schema约束结构信息。
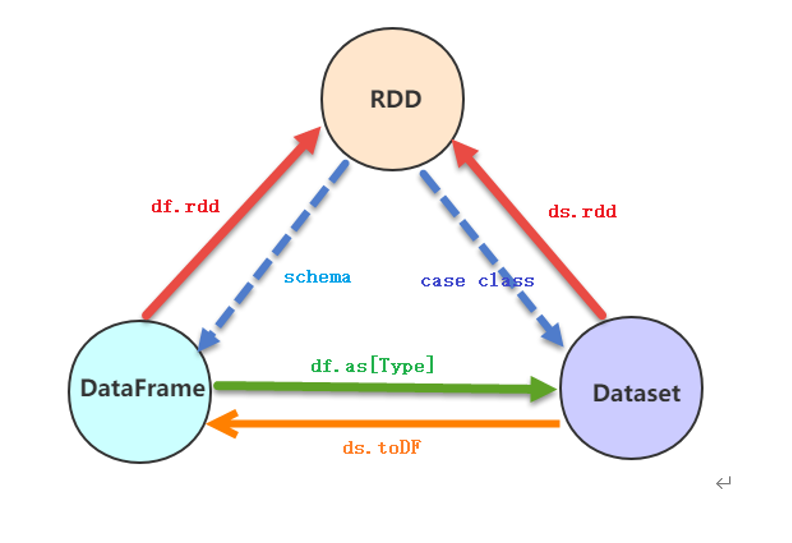
- RDD转换DataFrame或者Dataset
- 转换DataFrame时,定义Schema信息,两种方式
- 转换为Dataset时,不仅需要Schema信息,还需要RDD数据类型为CaseClass类型
- Dataset或DataFrame转换RDD
- 由于Dataset或DataFrame底层就是RDD,所以直接调用rdd函数即可转换
- dataframe.rdd 或者dataset.rdd
- DataFrame与Dataset之间转换
- 由于DataFrame为Dataset特例,所以Dataset直接调用toDF函数转换为DataFrame
- 当将DataFrame转换为Dataset时,使用函数as[Type],指定CaseClass类型即可,因为DataSet有具体的类型信息。
RDD、DataFrame和DataSet之间的转换如下:
RDD转换到DataFrame:rdd.toDF(“name”)
RDD转换到Dataset:rdd.map(x => Emp(x)).toDS
DataFrame转换到Dataset:df.as[Emp]
DataFrame转换到RDD:df.rdd
Dataset转换到DataFrame:ds.toDF
Dataset转换到RDD:ds.rdd注意:
RDD与DataFrame或者DataSet进行操作,都需要引入隐式转换import spark.implicits._,其中的spark是SparkSession对象的名称!
代码演示
object Test18 {
def main(args: Array[String]): Unit = {
//1.准备SparkSQL开发环境
val spark: SparkSession = SparkSession.builder().appName("hello").master("local[*]").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2.获取RDD
val fileRDD: RDD[String] = sc.textFile("D:\\soft\\idea\\work\\work04\\src\\main\\resources\\person")
val personRDD: RDD[Person] = fileRDD.map(line => {
val arr: Array[String] = line.split(" ")
Person(arr(0).toInt, arr(1), arr(2).toInt)
})
import spark.implicits._ //隐式转换
//3.相互转换
// RDD->DF
val df: DataFrame = personRDD.toDF()
// RDD->DS
val ds: Dataset[Person] = personRDD.toDS()
// DF->RDD
val rdd: RDD[Row] = df.rdd //注意:rdd->df的时候泛型丢了,所以df->rdd的时候就不知道原来的泛型了,给了个默认的
// DF->DS
val ds2: Dataset[Person] = df.as[Person] //给df添加上泛型
// DS->RDD
val rdd2: RDD[Person] = ds.rdd
// DS->DF
val df2: DataFrame = ds.toDF()
//4.输出约束和类型
df.printSchema()
df.show()
ds.printSchema()
ds.show()
//5.关闭资源
sc.stop()
spark.stop()
}
case class Person(id:Int,name:String,age:Int)
}SparkSQL花式查询
在SparkSQL模块中,将结构化数据封装到DataFrame或Dataset集合中后,提供了两种方式分析处理数据:
- SQL 编程,将DataFrame/Dataset注册为临时视图或表,编写SQL语句,类似HiveQL;
- DSL(domain-specific language)编程,调用DataFrame/Dataset API(函数),类似RDD中函数;
基于SQL查询
将Dataset/DataFrame注册为临时视图,编写SQL执行分析,分为两个步骤:
- 注册为临时视图

- 编写sql执行分析

其中SQL语句类似Hive中SQL语句,查看Hive官方文档,SQL查询分析语句语法,官方文档文档:

基于DSL分析
调用DataFrame/Dataset中API(函数)分析数据,其中函数包含RDD中转换函数和类似SQL语句函数,部分截图如下:

类似SQL语法函数:调用Dataset中API进行数据分析,Dataset中涵盖很多函数,大致分类如下:
- 选择函数select:选取某些列的值
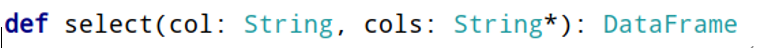
- 过滤函数filter/where:设置过滤条件,类似SQL中WHERE语句

- 分组函数groupBy/rollup/cube:对某些字段分组,在进行聚合统计

- 聚合函数agg:通常与分组函数连用,使用一些count、max、sum等聚合函数操作

- 排序函数sort/orderBy:按照某写列的值进行排序(升序ASC或者降序DESC)

- 限制函数limit:获取前几条数据,类似RDD中take函数
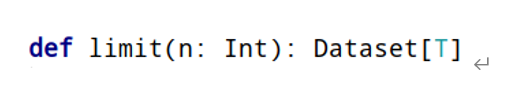
- 重命名函数withColumnRenamed:将某列的名称重新命名

- 删除函数drop:删除某些列

- 增加列函数withColumn:当某列存在时替换值,不存在时添加此列

上述函数在实际项目中经常使用,尤其数据分析处理的时候,其中要注意,调用函数时,通常指定某个列名称,传递Column对象,通过隐式转换转换字符串String类型为Column对象。
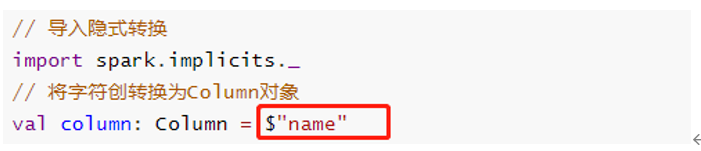
Dataset/DataFrame中转换函数,类似RDD中Transformation函数,使用差不多:

代码演示
object Test19 {
def main(args: Array[String]): Unit = {
//1.准备SparkSQL开发环境
val spark: SparkSession = SparkSession.builder().appName("hello").master("local[*]").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2.获取RDD
val fileRDD: RDD[String] = sc.textFile("D:\\soft\\idea\\work\\work04\\src\\main\\resources\\person")
val personRDD: RDD[Person] = fileRDD.map(line => {
val arr: Array[String] = line.split(" ")
Person(arr(0).toInt, arr(1), arr(2).toInt)
})
//3.RDD->DataFrame
import spark.implicits._ //隐式转换
val df: DataFrame = personRDD.toDF()
//4.输出约束和类型
df.printSchema()
df.show()
//TODO =============花式查询============
println("===========SQL风格========")
//-1.注册表
//df.registerTempTable("t_person")
//df.createOrReplaceGlobalTempView("t_person")//创建一个全局的视图/表,所有SparkSession可用--生命周期太长
df.createOrReplaceTempView("t_person") //创建一个临时视图/表,该SparkSession可用
//-2.各种查询
//=1.查看name字段的数据
spark.sql("select name from t_person").show(false)
//=2.查看 name 和age字段数据
spark.sql("select name,age from t_person").show(false)
//=3.查询所有的name和age,并将age+1
spark.sql("select name,age,age+1 from t_person").show(false)
//=4.过滤age大于等于25的
spark.sql("select id,name,age from t_person where age >= 25").show(false)
//=5.统计年龄大于30的人数
spark.sql("select count(*) from t_person where age > 30").show(false)
//=6.按年龄进行分组并统计相同年龄的人数
spark.sql("select age,count(*) from t_person group by age").show(false)
//=7.查询姓名=张三的
val name = "zhangsan"
spark.sql("select id,name,age from t_person where name='zhangsan'").show(false)
spark.sql(s"select id,name,age from t_person where name='${name}'").show(false)
println("===========DSL风格========")
//=1.查看name字段的数据
df.select(df.col("name")).show(false)
import org.apache.spark.sql.functions._
df.select(col("name")).show(false)
df.select("name").show(false)
//=2.查看 name 和age字段数据
df.select("name", "age").show(false)
//=3.查询所有的name和age,并将age+1
//df.select("name","age","age+1").show(false)//报错:没有"age+1"这个列名
//df.select("name","age","age"+1).show(false)//报错:没有"age+1"这个列名
df.select($"name", $"age", $"age" + 1).show(false) //$"age"表示获取该列的值/$"列名"表示将该列名字符串转为列对象
df.select('name, 'age, 'age + 1).show(false) //'列名表示将该列名字符串转为列对象
//=4.过滤age大于等于25的
df.filter("age >= 25").show(false)
df.where("age >= 25").show(false)
//=5.统计年龄大于30的人数
val count: Long = df.filter("age > 30").count()
println("年龄大于30的人数"+count)
//=6.按年龄进行分组并统计相同年龄的人数
df.groupBy("age").count().show(false)
//=7.查询姓名=张三的
df.filter("name ='zhangsan'").show(false)
df.where("name ='zhangsan'").show(false)
df.filter($"name" === "zhangsan").show(false)
df.filter('name === "zhangsan").show(false)
//=8.查询姓名!=张三的
df.filter($"name" =!= name).show(false)
df.filter('name =!= "zhangsan").show(false)
//TODO =============花式查询============
//5.关闭资源
sc.stop()
spark.stop()
}
case class Person(id: Int, name: String, age: Int)
}使用SparkSQL的SQL和DSL两种方式完成WordCount
object SparkSQLDemo05_WordCount {
def main(args: Array[String]): Unit = {
//1.准备SparkSQL开发环境
val spark: SparkSession = SparkSession.builder().appName("hello").master("local[*]").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
import spark.implicits._
//2.获取DF/DS
//获取DF/DS方式一:通过RDD->DF/DS
val fileRDD: RDD[String] = sc.textFile("data/input/words.txt")
val df: DataFrame = fileRDD.toDF("value")
val ds: Dataset[String] = df.as[String]
df.printSchema()
df.show(false)
ds.printSchema()
ds.show(false)
//获取DF/DS方式二:
val df2: DataFrame = spark.read.text("data/input/words.txt")
df2.printSchema()
df2.show(false)
val ds2: Dataset[String] = spark.read.textFile("data/input/words.txt")
ds2.printSchema()
ds2.show(false)
/*
root
|-- value: string (nullable = true)
+----------------+
|value |
+----------------+
|hello me you her|
|hello you her |
|hello her |
|hello |
+----------------+
*/
//3.计算WordCount
//df.flatMap(_.split(" ")) //报错:DF没有泛型,不知道_是String
//df2.flatMap(_.split(" "))//报错:DF没有泛型,不知道_是String
val wordDS: Dataset[String] = ds.flatMap(_.split(" "))
//ds2.flatMap(_.split(" "))
wordDS.printSchema()
wordDS.show(false)
/*
+-----+
|value|
+-----+
|hello|
|me |
|you |
....
*/
//TODO SQL风格
wordDS.createOrReplaceTempView("t_words")
val sql: String =
"""
|select value as word,count(*) as counts
|from t_words
|group by word
|order by counts desc
|""".stripMargin
spark.sql(sql).show(false)
//TODO DSL风格
wordDS.groupBy("value")
.count()
.orderBy('count.desc)
.show(false)
/*
+-----+------+
|word |counts|
+-----+------+
|hello|4 |
|her |3 |
|you |2 |
|me |1 |
+-----+------+
+-----+-----+
|value|count|
+-----+-----+
|hello|4 |
|her |3 |
|you |2 |
|me |1 |
+-----+-----+
*/
//4.关闭资源
sc.stop()
spark.stop()
}
case class Person(id: Int, name: String, age: Int)
}贡献者
 codingLab
codingLab版权所有
版权归属:
许可证: