2、DataSet数据结构
DataSet
sparksql支持:命令式,SQL
spark用于支持这两种方式的api叫做,dataset和dataframe
为什么需要Dataset
Spark在Spark 1.3版本中引入了Dataframe,DataFrame是组织到命名列中的分布式数据集合,但是有如下几点限制:
- 编译时类型不安全:
- Dataframe API不支持编译时安全性,这限制了在结构不知道时操纵数据。因为Schema 是运行时信息,在编译期间不知道scheme信息。
- 以下示例在编译期间有效。但是,执行此代码时将出现运行时异常。

也就是说在编译时检查不出异常,但是在运行的时候会出现异常。
为什么dataframe为什么在运行时候才知道scheme信息,编译时类型不安全?
- 数据源的多样性,dataframe的数据源可以有多种,json,jdbc,csv,parquet等多种,因此运行时才能确定数据源的 Schema。
- 延迟执行,懒加载,只有直行道Action算子才真正触发计算,转换算子只是创建DAG图逻辑计划。
- 无法对域对象(丢失域对象)进行操作:
- 将域对象转换为DataFrame后,无法从中重新生成它;
- 下面的示例中,一旦我们从personRDD创建personDF,将不会恢复Person类的原始RDD(RDD [Person]);
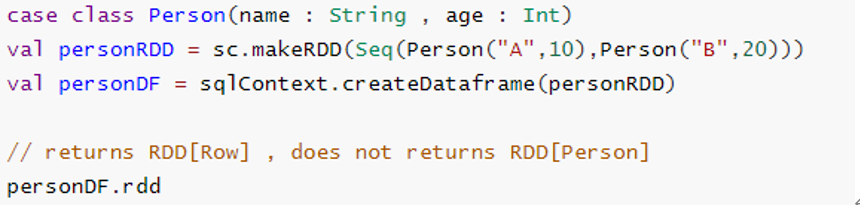
总结出DataFrame存在的两点缺陷问题:
- 编译错误无法检查出来,只能运行时检查错误
- 丢失对象的类型信息,是一种强类型的结构
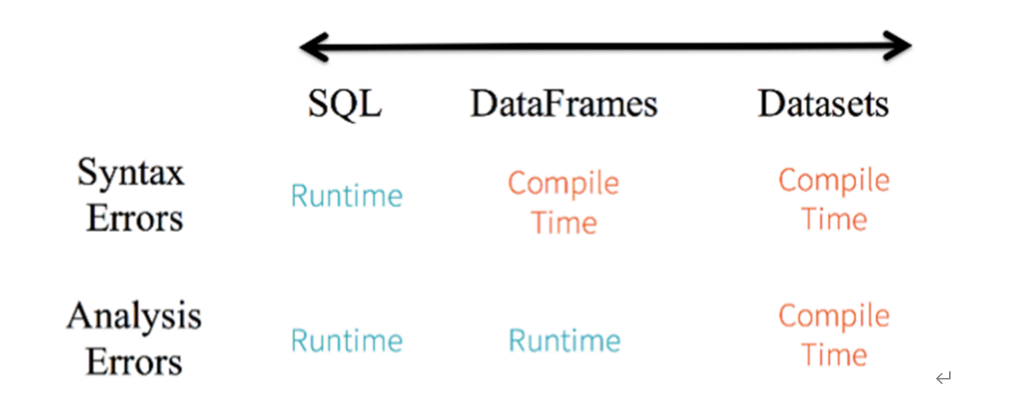
基于上述的两点,从Spark1.6开始出现Dataset,至Spark 2.0中将DataFrame与Dataset合并,其中DataFrame为Dataset特殊类型,类型为Row。
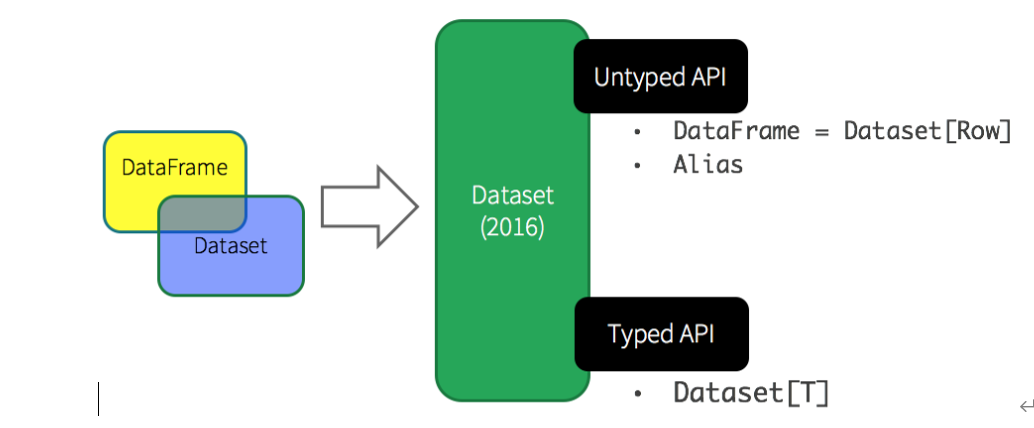
针对RDD、DataFrame与Dataset三者编程比较来说,Dataset API无论语法错误和分析错误在编译时都能发现。
此外RDD与Dataset相比较而言,由于Dataset数据使用特殊编码,所以在存储数据时更加节省内存。
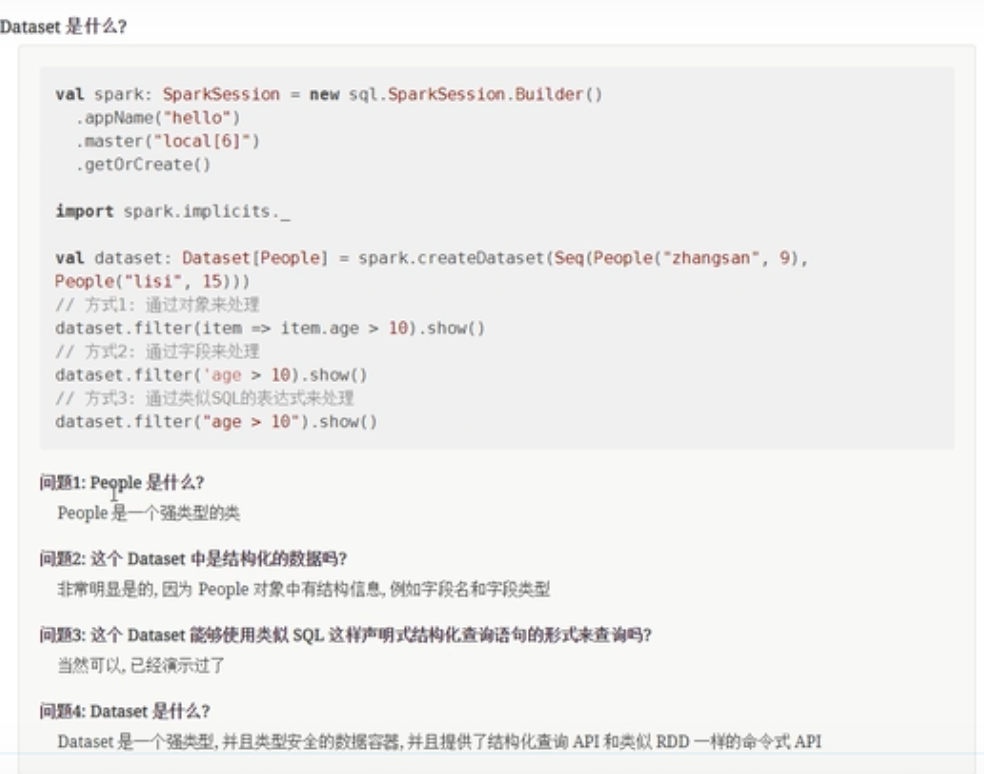
Dataset是什么

这里解释一下,在DataFrame中,每一行的类型是Row类型,但是在DataSet中,增加了具体的类型,所以DataSet看起来比DataFrame更加的高级。
Spark 框架从最初的数据结构RDD、到SparkSQL中针对结构化数据封装的数据结构DataFrame,最终使用Dataset数据集进行封装,发展流程如下。
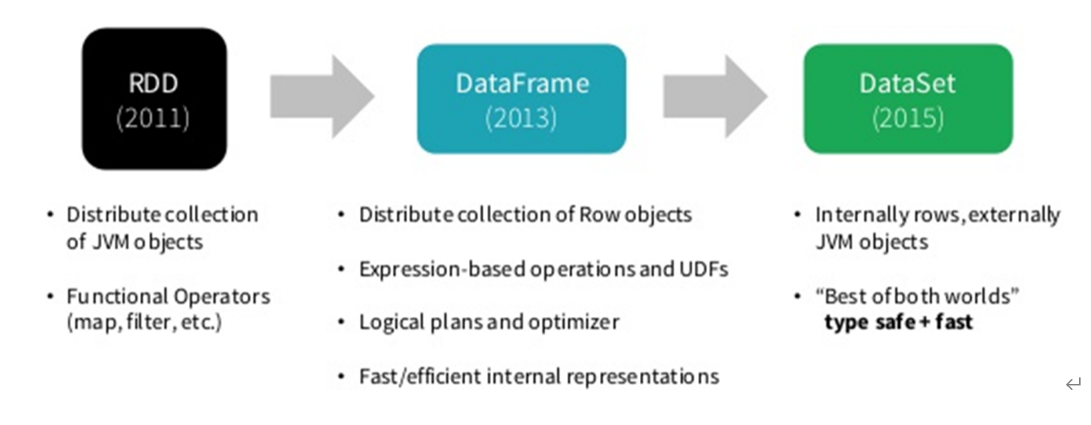
Dataset是Spark 1.6推出的最新的数据抽象,可以理解为是DataFrames的扩展,它提供了一种类型安全的,面向对象的编程接口。
从Spark 2.0开始,DataFrame与Dataset合并,每个Dataset也有一个被称为一个DataFrame的类型化视图,这种DataFrame是Row类型的Dataset,即Dataset[Row]。DataFrame = DataSet[Row]
Dataset结合了RDD和DataFrame的优点:
- 与RDD相比:Dataset保存了更多的描述信息,概念上等同于关系型数据库中的二维表;
- 与DataFrame相比:Dataset保存了类型信息,是强类型的,提供了编译时类型检查,调用Dataset的方法先会生成逻辑计划,然后被Spark的优化器进行优化,最终生成物理计划,然后提交到集群中运行;
所以在实际项目中建议使用Dataset进行数据封装,数据分析性能和数据存储更加好。
object Test03 {
def main(args: Array[String]): Unit = {
// 1 创建sparksession
val spark = new sql.SparkSession.Builder()
.master("local[6]")
.appName("dataset")
.getOrCreate()//创建sparksession的对象
// 2 导入隐式转换,这里的spark是创建出来的spark对象,而不是包
import spark.implicits._
val datasource: RDD[Person] = spark.sparkContext.parallelize(Seq(Person("zhangsan", 15), Person("lisi", 25)))
// 3 使用dataset
// 把生成的数据转换为dataset
val daData: Dataset[Person] = datasource.toDS()
//dataset支持rdd类型的api
daData.filter(item => item.age>10).show()
// dataste支持弱类型的api
daData.filter('age> 10).show()
daData.filter($"age">10).show()
// 可以直接编写sql表达式
daData.filter("age > 10").show()
}
case class Person(name:String,age: Int)
}
在dataset中,不仅有类型信息,而且还有结构信息。
Dataset底层是什么
查看执行计划
object Test03 {
def main(args: Array[String]): Unit = {
// 1 创建sparksession
val spark = new sql.SparkSession.Builder()
.master("local[6]")
.appName("dataset")
.getOrCreate()//创建sparksession的对象
// 2 导入隐式转换,这里的spark是创建出来的spark对象,而不是包
import spark.implicits._
val datasource: RDD[Person] = spark.sparkContext.parallelize(Seq(Person("zhangsan", 15), Person("lisi", 25)))
// 3 使用dataset
// 把生成的数据转换为dataset
val daData: Dataset[Person] = datasource.toDS()
//查看逻辑执行计划
daData.queryExecution
//查看物理执行计划和逻辑执行计划
daData.explain(true)
}
case class Person(name:String,age: Int)
}
//执行计划
== Parsed Logical Plan ==//解析AST语法树
SerializeFromObject [staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(assertnotnull(input[0, hm.hmsql.Test03$Person, true])).name, true, false) AS name#3, knownnotnull(assertnotnull(input[0, hm.hmsql.Test03$Person, true])).age AS age#4]
+- ExternalRDD [obj#2]
== Analyzed Logical Plan ==//分析树。添加元数据信息
name: string, age: int
SerializeFromObject [staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(assertnotnull(input[0, hm.hmsql.Test03$Person, true])).name, true, false) AS name#3, knownnotnull(assertnotnull(input[0, hm.hmsql.Test03$Person, true])).age AS age#4]
+- ExternalRDD [obj#2]
== Optimized Logical Plan ==//优化语法树
SerializeFromObject [staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(assertnotnull(input[0, hm.hmsql.Test03$Person, true])).name, true, false) AS name#3, knownnotnull(assertnotnull(input[0, hm.hmsql.Test03$Person, true])).age AS age#4]
+- ExternalRDD [obj#2]
== Physical Plan ==//生成物理执行计划
*(1) SerializeFromObject [staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, knownnotnull(assertnotnull(input[0, hm.hmsql.Test03$Person, true])).name, true, false) AS name#3, knownnotnull(assertnotnull(input[0, hm.hmsql.Test03$Person, true])).age AS age#4]
+- Scan[obj#2]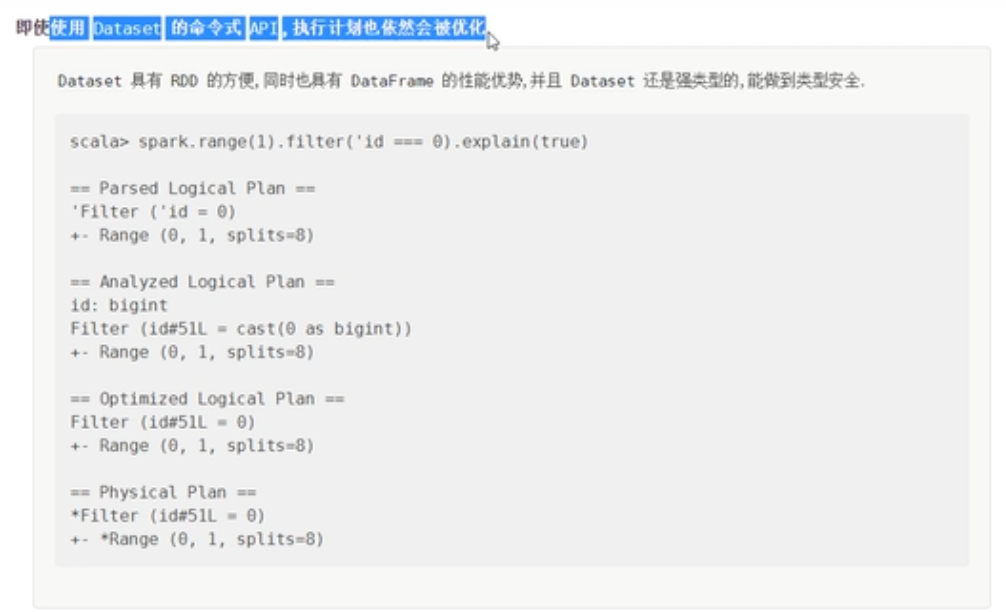
也就是说dataset不管是否执行sql语句,都会被优化器进行优化。
dataset底层数据结构
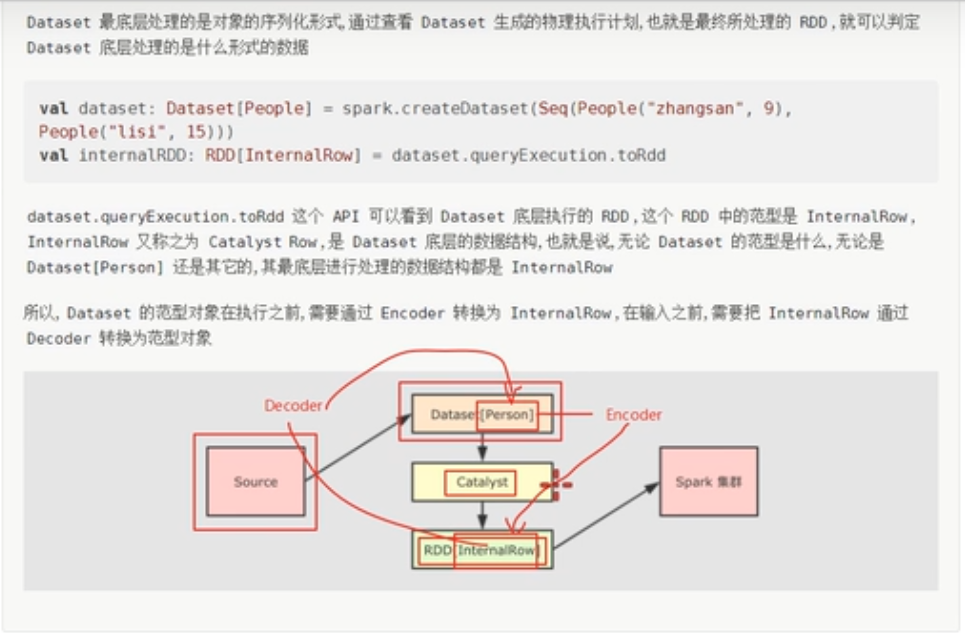
底层代码
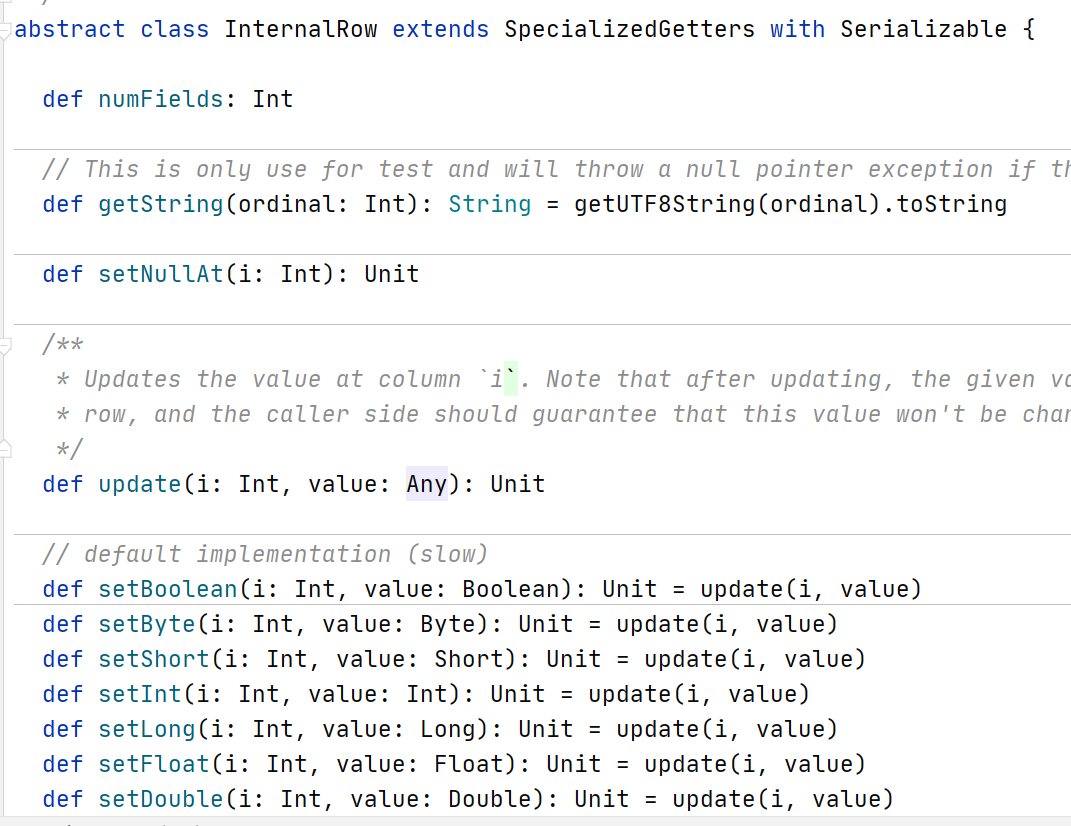
从底层代码来看,他对所有的数据类型都进行了一个包装,对外表现为不同的数据类型,但是对内使用统一的数据类型表示。
使用dataset.rdd可以直接把dataset转换为rdd,spark是一个非常弹性的工具,在一个程序中,既可以使用rdd,又可以使用rdd,还可以使用sql。
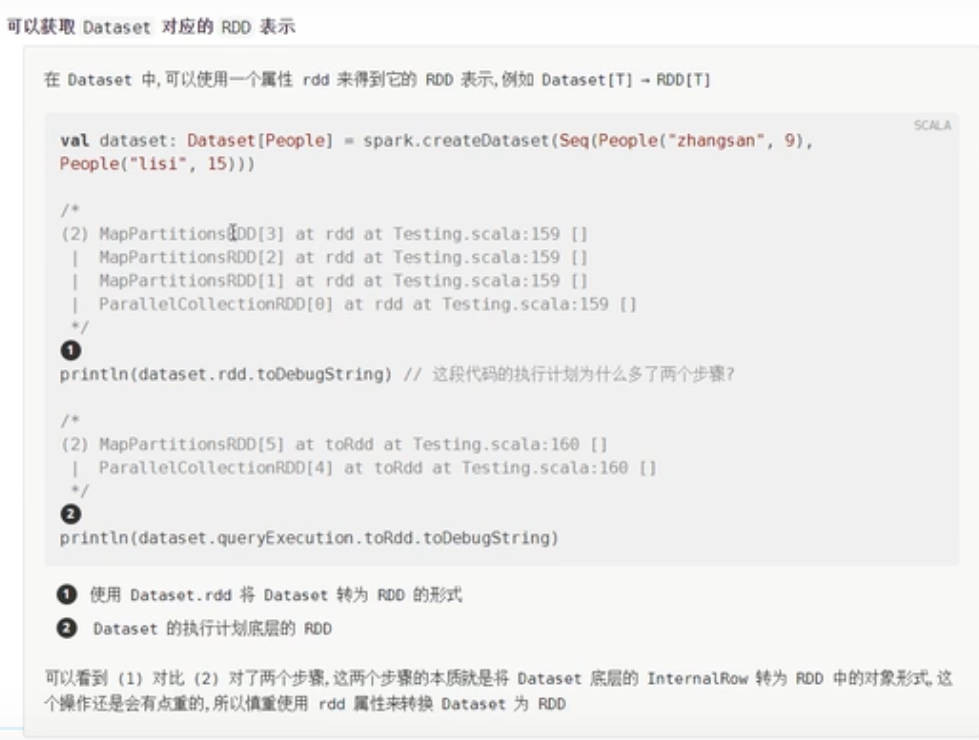
object Test04 {
def main(args: Array[String]): Unit = {
// 1 创建sparksession
val spark = new sql.SparkSession.Builder()
.master("local[6]")
.appName("dataset")
.getOrCreate()//创建sparksession的对象
// 2 导入隐式转换,这里的spark是创建出来的spark对象,而不是包
import spark.implicits._
val datasource: RDD[Person] = spark.sparkContext.parallelize(Seq(Person("zhangsan", 15), Person("lisi", 25)))
// 3 使用dataset
// 第一种创建dataset的方式:把生成的数据转换为dataset
val daData: Dataset[Person] = datasource.toDS()
// 第二种方式创建dataset
val dataDs: Dataset[Person] = spark.createDataset(Seq(Person("zhangsan", 15), Person("lisi", 25)))
//直接获取已经分析和结果过的dataset的执行计划,从中拿到rdd
val rdd1: RDD[InternalRow] = dataDs.queryExecution.toRdd
//将dataset底层的RDD[InternalRow],通过底层的DECODER转换成和dataset类型一致的RDD
val rdd: RDD[Person] = dataDs.rdd
//查看rdd的执行步骤
println(rdd1.toDebugString)
println()
println(rdd.toDebugString)
}
case class Person(name:String,age: Int)
}
(2) SQLExecutionRDD[3] at toRdd at Test04.scala:29 []
| MapPartitionsRDD[2] at toRdd at Test04.scala:29 []
| ParallelCollectionRDD[1] at toRdd at Test04.scala:29 []
(2) MapPartitionsRDD[8] at rdd at Test04.scala:30 []
| SQLExecutionRDD[7] at rdd at Test04.scala:30 []
| MapPartitionsRDD[6] at rdd at Test04.scala:30 []
| MapPartitionsRDD[5] at rdd at Test04.scala:30 []
| ParallelCollectionRDD[4] at rdd at Test04.scala:30 []- dataDs.queryExecution.toRdd:直接获取已经分析和解析过的dataset的执行计划,从中获取到rdd和其类型,必然是InternalRow类型的。
- dataDs.rdd:将dataset底层的RDD[InternalRow],通过底层的DECODER转换成和dataset类型一致的RDD[person],也就是转换为具体的类型。
RDD、DataFrame、DataSet小结
下面这张图说明了三者结构的差别
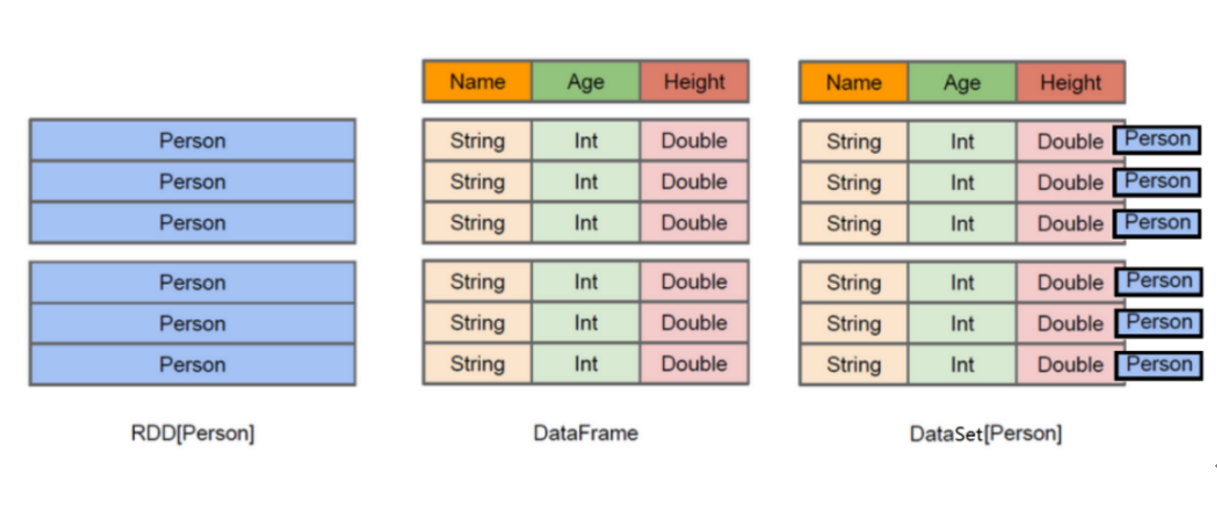
SparkSQL中常见面试题:如何理解Spark中三种数据结构RDD、DataFrame和Dataset关系?
RDD:
- RDD(Resilient Distributed Datasets)叫做弹性分布式数据集,是Spark中最基本的数据抽象,源码中是一个抽象类,代表一个不可变、可分区、里面的元素可并行计算的集合。
- 编译时类型安全,但是无论是集群间的通信,还是IO操作都需要对对象的结构和数据进行序列化和反序列化,还存在较大的GC的性能开销,会频繁的创建和销毁对象。
DataFrame
- 与RDD类似,DataFrame是一个分布式数据容器,不过它更像数据库中的二维表格,除了数据之外,还记录这数据的结构信息(即schema)。
- DataFrame也是懒执行的,性能上要比RDD高(主要因为执行计划得到了优化)。
- 由于DataFrame每一行的数据结构一样,且存在schema中,Spark通过schema就能读懂数据,因此在通信和IO时只需要序列化和反序列化数据,而结构部分不用。
- Spark能够以二进制的形式序列化数据到JVM堆以外(off-heap:非堆)的内存,这些内存直接受操作系统管理,也就不再受JVM的限制和GC的困扰了。但是DataFrame不是类型安全的。
Dataset:
- Dataset是Spark1.6中对DataFrame API的一个扩展,是Spark最新的数据抽象,结合了RDD和DataFrame的优点。
- DataFrame=Dataset[Row](Row表示表结构信息的类型),DataFrame只知道字段,但是不知道字段类型,而Dataset是强类型的,不仅仅知道字段,而且知道字段类型。
- 样例类CaseClass被用来在Dataset中定义数据的结构信息,样例类中的每个属性名称直接对应到Dataset中的字段名称。
- Dataset具有类型安全检查,也具有DataFrame的查询优化特性,还支持编解码器,当需要访问非堆上的数据时可以避免反序列化整个对象,提高了效率。
贡献者
 codingLab
codingLab版权所有
版权归属:
许可证: