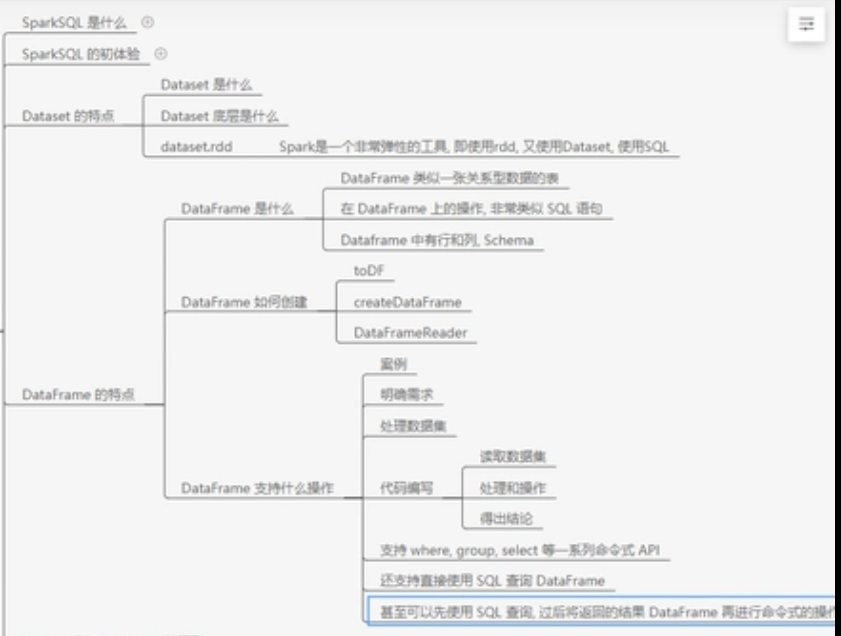
1、DataFrame数据结构
DataFrame
DataFrame是什么

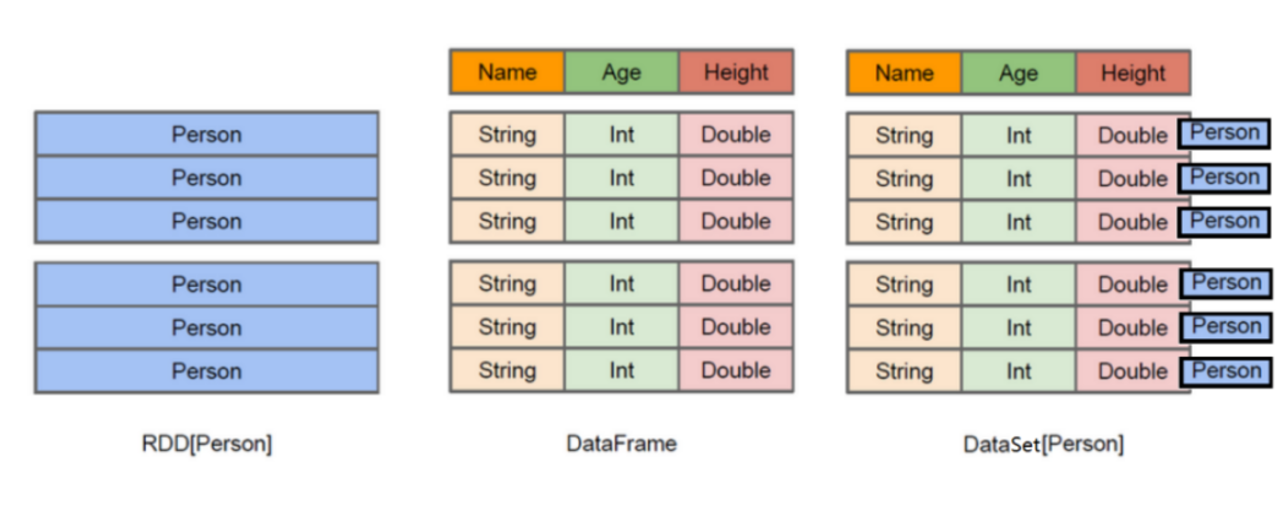
上图中左侧的RDD[Person]虽然以Person为类型参数,但Spark框架本身不了解Person类的内部结构。而中间的DataFrame却提供了详细的结构信息,使得Spark SQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。了解了这些信息之后,Spark SQL的查询优化器就可以进行针对性的优化。后者由于在编译期有详尽的类型信息,编译期就可以编译出更加有针对性、更加优化的可执行代码。
Schema 信息
查看DataFrame中Schema是什么,执行如下命令:df.schema。
Schema信息封装在StructType中,包含很多StructField对象。

Row DataFrame中每条数据封装在Row中,Row表示每行数据。如何构建Row对象:要么是传递value,要么传递Seq,官方实例代码:
import org.apache.spark.sql._
// Create a Row from values.
Row(value1, value2, value3, ...)
// Create a Row from a Seq of values.
Row.fromSeq(Seq(value1, value2, ...))如何获取Row中每个字段的值呢?
方式1:下标获取,从0开始,类似数组下标获取
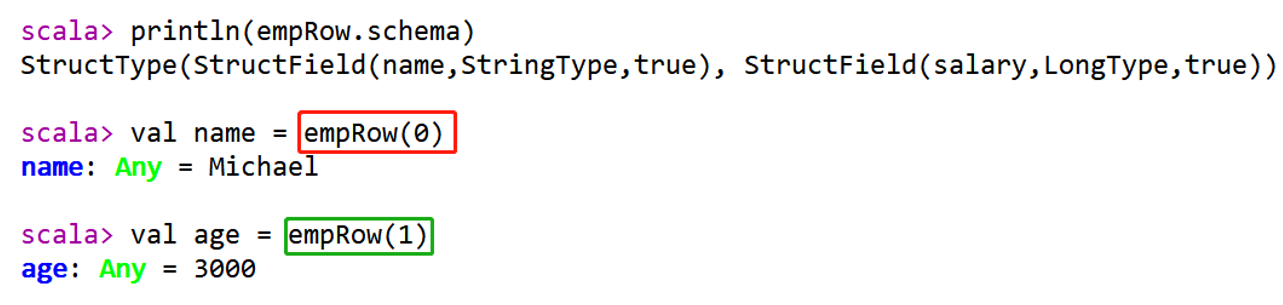
方式2:指定下标,知道类型

方式3:通过As转换类型

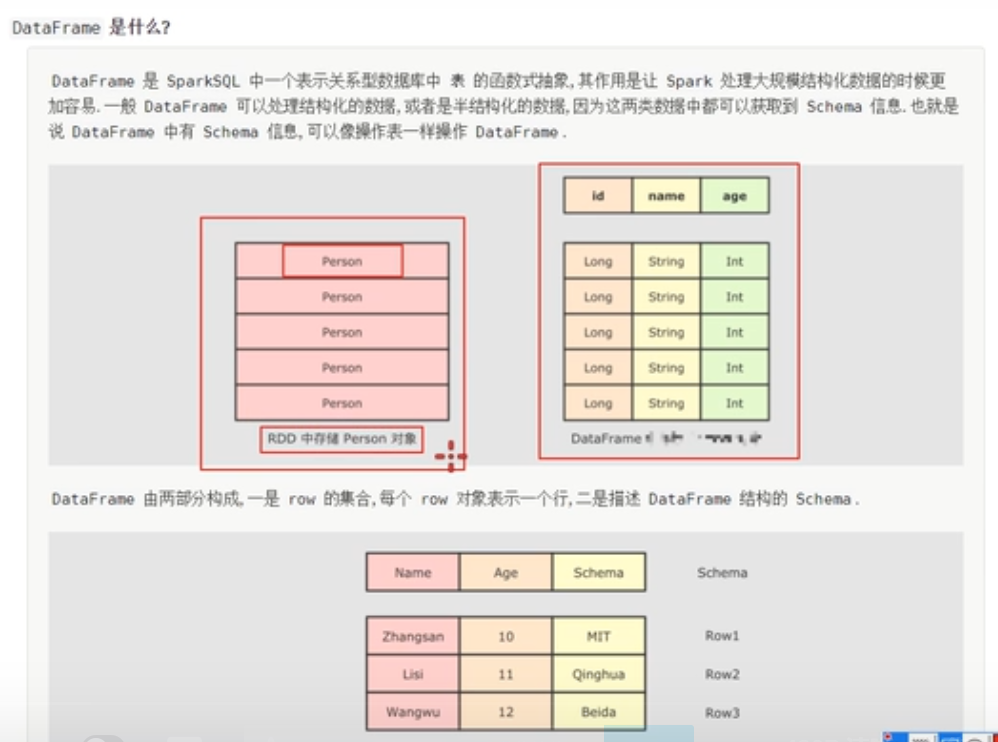
- 在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。
- DataFrame与RDD的主要区别在于,前者带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。
- 使得Spark SQL得以洞察更多的结构信息,从而对藏于DataFrame背后的数据源以及作用于DataFrame之上的变换进行针对性的优化,最终达到大幅提升运行时效率。反观RDD,由于无从得知所存数据元素的具体内部结构,Spark Core只能在stage层面进行简单、通用的流水线优化。
案例
Dataobject Test05 {
def main(args: Array[String]): Unit = {
// 1 创建sparksession
val spark: SparkSession = SparkSession.builder()
.appName("dataframe")
.master("local[6]")
.getOrCreate()//创建sparksession的对象
// 2 导入隐式转换,这里的spark是创建出来的spark对象,而不是包
import spark.implicits._
// 3 创建dataframe
val df: DataFrame = Seq(Person("zhangsan", 15), Person("lisi", 25)).toDF()
// 操作dataframe
// select name from table where age > 16
// sql语句支持的语法,dataframe也都支持
df
.where('age>16)
.select("name")
.show()
}
case class Person(name:String,age: Int)
}DataFrame类似于关系型数据库中的一张表,在DataFrame上面的操作,非常类似于sql语句的操作,因为dataframe被划分为行和列,并且列中包含Schema信息,表示表的结构信息。
数据清洗的步骤
ETL:
- E:抽取
- T:转换和处理
- L:装载和落地
spark代码编写规则:
- 创建DataFrame,DataSet,RDD,读取数据
- 通过Df,DataSet,RDD,的API进行数据的处理
- 通过DF,DataSet,RDD,进行数据的落地
创建DataFrame
通过隐式转换
object Test06 {
def main(args: Array[String]): Unit = {
// 1 创建sparksession
val spark: SparkSession = SparkSession.builder()
.appName("dataframe")
.master("local[6]")
.getOrCreate()//创建sparksession的对象
// 2 导入隐式转换,这里的spark是创建出来的spark对象,而不是包
import spark.implicits._
val personList = Seq(Person("zhangsan", 15), ("lisi", 26))
// 3 创建dataframe
// 1 通过隐式转换
val df1: DataFrame = personList.toDF()
val df2: DataFrame = spark.sparkContext.parallelize(personList).toDF()
}
case class Person(name:String,age: Int)
}通过集合创建
object Test06 {
def main(args: Array[String]): Unit = {
// 1 创建sparksession
val spark: SparkSession = SparkSession.builder()
.appName("dataframe")
.master("local[6]")
.getOrCreate()//创建sparksession的对象
// 2 导入隐式转换,这里的spark是创建出来的spark对象,而不是包
import spark.implicits._
val personList = Seq(Person("zhangsan", 15), ("lisi", 26))
// 3 创建dataframe
// 2 通过createDataFrame()创建
val df3: DataFrame = spark.createDataFrame(personList)
}
case class Person(name:String,age: Int)
}通过读取外部数据集
object Test06 {
def main(args: Array[String]): Unit = {
// 1 创建sparksession
val spark: SparkSession = SparkSession.builder()
.appName("dataframe")
.master("local[6]")
.getOrCreate()//创建sparksession的对象
// 2 导入隐式转换,这里的spark是创建出来的spark对象,而不是包
import spark.implicits._
val personList = Seq(Person("zhangsan", 15), ("lisi", 26))
// 3 创建dataframe
//3 通过read()方式
val df4: DataFrame = spark.read.csv("")
}
case class Person(name:String,age: Int)
}操作DataFrame
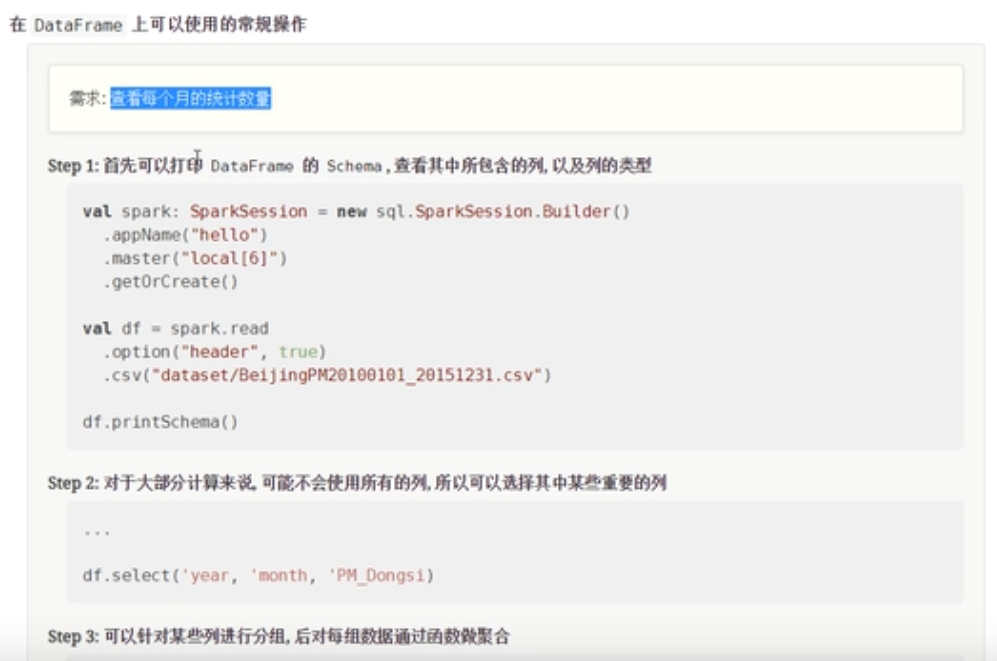
object Test07 {
def main(args: Array[String]): Unit = {
// 1 创建sparksession
val spark: SparkSession = SparkSession.builder()
.appName("dataframe")
.master("local[6]")
.getOrCreate()//创建sparksession的对象
// 2 导入隐式转换,这里的spark是创建出来的spark对象,而不是包
import spark.implicits._
// 读取数据
val df: DataFrame = spark.read
.option("header",value = true)//告诉spark在读取文件的时候,把第一行当做头处理
.csv("")
// 处理
// 1 选择列
// 2 过滤掉NA的值
// 3 分组处理
// 4 做聚合处理
df.select('year,'month,'PM_Dongsi)
.where('PM_Dongsi =!= "NA")
.groupBy('year,'month)
.count()
.show()
//直接使用sql语句查询
//将dataframe注册为临时表
df.createOrReplaceTempView("pm")
val res: DataFrame = spark.sql("select year,month,count(PM_Dongsi) from pm where PM_Dongsi != 'NA' group by year,month ")
res.show()
spark.stop()
}
case class Person(name:String,age: Int)
}DataSet和DataFrame的区别
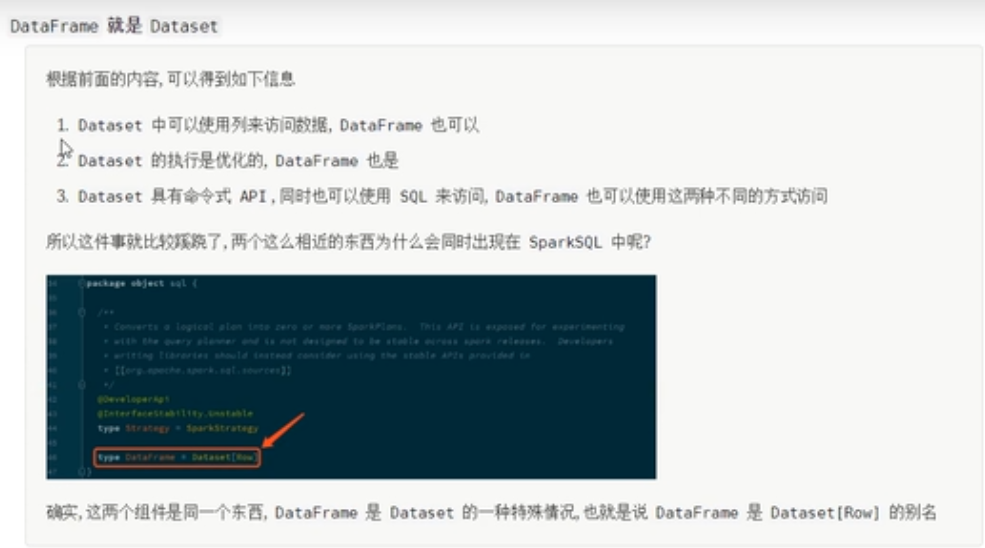
从源码中可以看到DataFrame就是Dataset
package object sql {
@DeveloperApi
@Unstable
type Strategy = SparkStrategy
type DataFrame = Dataset[Row]
private[sql] val SPARK_VERSION_METADATA_KEY = "org.apache.spark.version"
private[sql] val SPARK_LEGACY_DATETIME = "org.apache.spark.legacyDateTime"
}
object Test08 {
def main(args: Array[String]): Unit = {
// 1 创建sparksession
val spark: SparkSession = SparkSession.builder()
.appName("dataframe")
.master("local[6]")
.getOrCreate()//创建sparksession的对象
// 2 导入隐式转换,这里的spark是创建出来的spark对象,而不是包
import spark.implicits._
val personList = Seq(Person("zhangsan", 15), Person("lisi", 26))
//无论DataFrame里面存储的是什么类型的数据。其底层都是Dataset[Row]类型,DataFrame是弱类型
val df: DataFrame = personList.toDF()
//但是对于Dataset来说。里面可以存储具体的类型对象,Dataset是强类型
val ds: Dataset[Person] = personList.toDS()
}
case class Person(name:String,age: Int)
}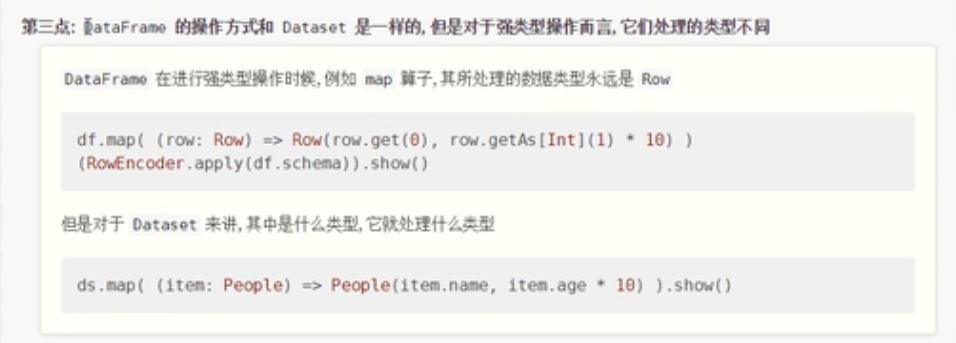
不管DataFrame里面存储的是什么,类型永远是Row对象,但是对于Dataset来说,可以具体存储类型。
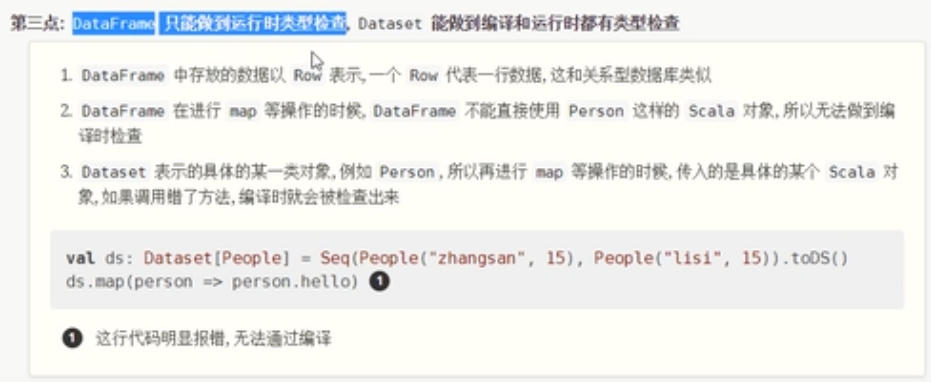
DataFrame代表的弱类型在编译的时候是不安全的,Dataset是编译时类型安全的。

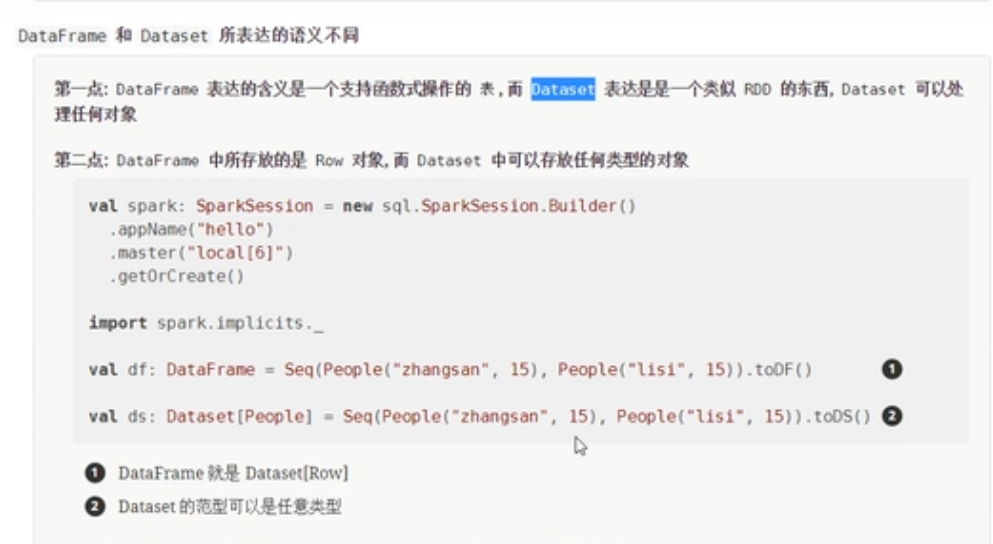
DataFrame和DataSet的区别
- DataFrame表达的含义是一个支持函数式编程的二维表格。DataSet表达的是一个类似RDD的东西,DataSet可以处理任何对象类型
- DataFrame里面存放的是Row对象,DataSet里面可以存放任何类型的对象。
- DataFrame代表的是弱类型,DataSet代表的是强类型。
- DataFrame只能运行时检查类型安全,但是DataSet可以做到编译时和运行时的类型安全检查。
Row对象
DataFrame中每条数据封装在Row中,Row表示每行数据
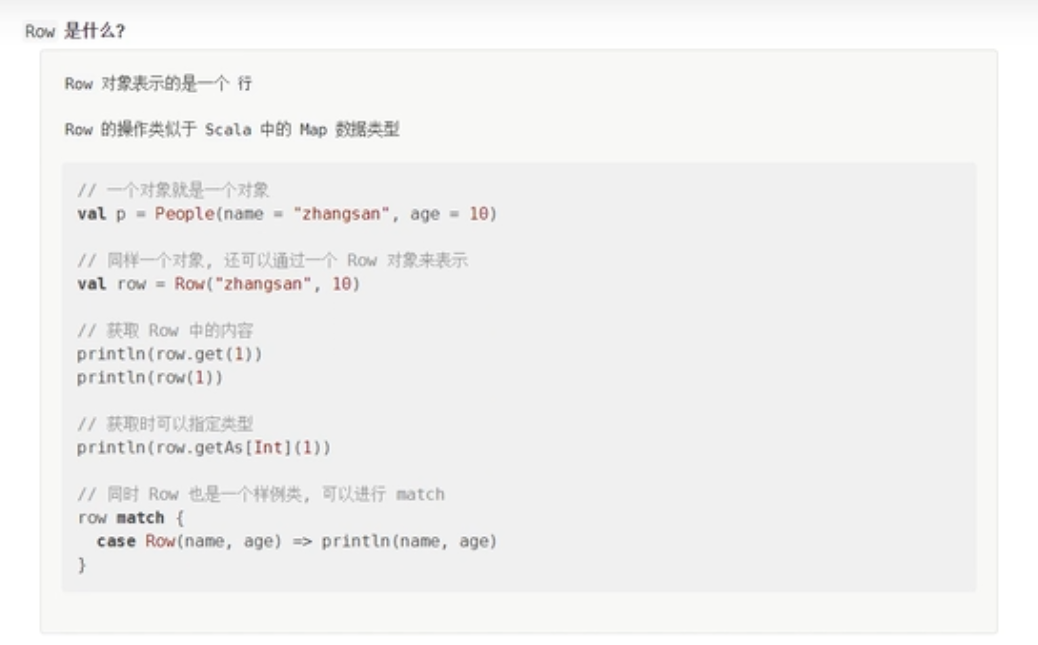
row与DataFrame
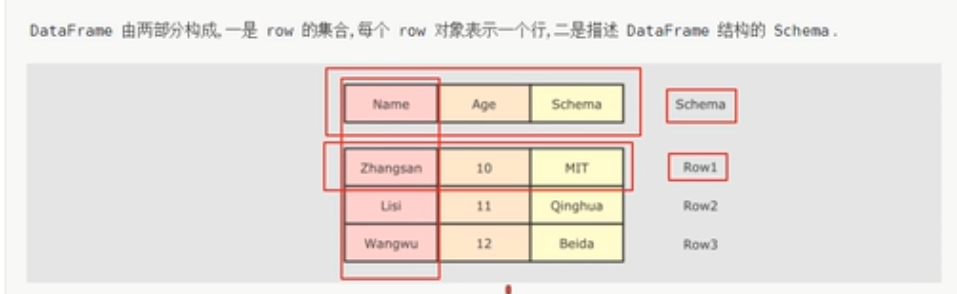
可以看到,DataFrame就是一个二维的表格,row就是一个行,Row有一个schema对象表示表结构,DataFrame就是由放置了Row的Dataset组成组成的二维表格。其实DataFrame就是DataSet。
object Test09 {
def main(args: Array[String]): Unit = {
// 1 创建sparksession
val spark: SparkSession = SparkSession.builder()
.appName("dataframe")
.master("local[6]")
.getOrCreate()//创建sparksession的对象
// 2 导入隐式转换,这里的spark是创建出来的spark对象,而不是包
import spark.implicits._
//Row 是什么,如何创建
val p = new Person("zhangsan", 25)
//row对象必须配合schema对象才会有列名
val row: Any = Row("lisi", 24)
// 从row中获取数据是根据索引获取的
row.getString(0) //根据索引修改值,就像数组一样
row.getInt(1)
// row也是样例类
row match{
case Row(name,age)=>println(name,age)
}
}
case class Person(name:String,age: Int)
}如何理解DataFrame就是Dataset,我们可以从DataFrame和Dataset的结构看一下。
对于RDD中的数据:

对应到Dataset中就是这样存放的:

如果存放到DataFrame中,那么就是下面这样的。
很明显,我们可以看出,对于Dataset中,数据是按照对象的格式存储在每一行中,每一行都表示一个对象,表头的schema信息也是一个对象,并且每一行表示具体的类型,不再是Row类型,我们说DataFrame是存储了类型为Row的Dataset,也就是说DataFrame的每一行类型被封装为Row类型,不能代表具体的类型。
RDD、DataFrame和Dataset
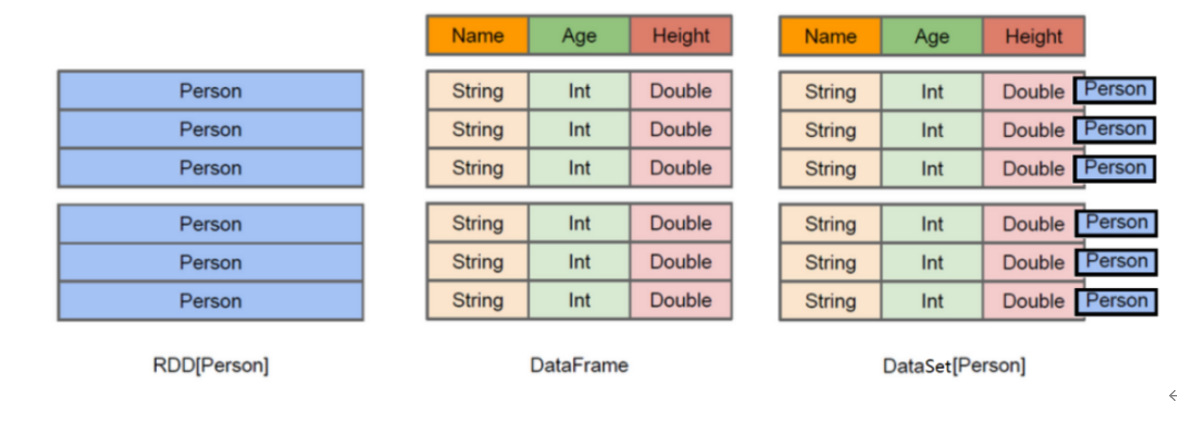
如何理解Spark中三种数据结构RDD、DataFrame和Dataset关系
SparkSQL中常见面试题:如何理解Spark中三种数据结构RDD、DataFrame和Dataset关系?
RDD
- RDD(Resilient Distributed Datasets)叫做弹性分布式数据集,是Spark中最基本的数据抽象,源码中是一个抽象类,代表一个不可变、可分区、里面的元素可并行计算的集合。
- 编译时类型安全,但是无论是集群间的通信,还是IO操作都需要对对象的结构和数据进行序列化和反序列化,还存在较大的GC的性能开销,会频繁的创建和销毁对象。
DataFrame
- 与RDD类似,DataFrame是一个分布式数据容器,不过它更像数据库中的二维表格,除了数据之外,还记录这数据的结构信息(即schema)。
- DataFrame也是懒执行的,性能上要比RDD高(主要因为执行计划得到了优化)。
- 由于DataFrame每一行的数据结构一样,且存在schema中,Spark通过schema就能读懂数据,因此在通信和IO时只需要序列化和反序列化数据,而结构部分不用。
- Spark能够以二进制的形式序列化数据到JVM堆以外(off-heap:非堆)的内存,这些内存直接受操作系统管理,也就不再受JVM的限制和GC的困扰了。但是DataFrame不是类型安全的。
Dataset
- Dataset是Spark1.6中对DataFrame API的一个扩展,是Spark最新的数据抽象,结合了RDD和DataFrame的优点。
- DataFrame=Dataset[Row](Row表示表结构信息的类型),DataFrame只知道字段,但是不知道字段类型,而Dataset是强类型的,不仅仅知道字段,而且知道字段类型。
- 样例类CaseClass被用来在Dataset中定义数据的结构信息,样例类中的每个属性名称直接对应到Dataset中的字段名称。
- Dataset具有类型安全检查,也具有DataFrame的查询优化特性,还支持编解码器,当需要访问非堆上的数据时可以避免反序列化整个对象,提高了效率。
小结
贡献者
 codingLab
codingLab版权所有
版权归属:
许可证: