18、Spark运行环境
Spark运行环境
Spark应用程序可以运行在本地模式(Local Mode)、集群模式(Cluster Mode)和云服务(Cloud),方便开发测试和生产部署。
概述
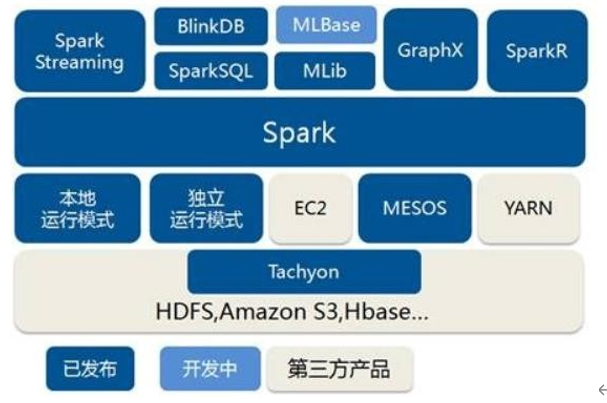
Spark 作为一个数据处理框架和计算引擎,被设计在所有常见的集群环境中运行, 在国内工作中主流的环境为Yarn,不过逐渐容器式环境也慢慢流行起来。接下来,我们就分别看看不同环境下Spark 的运行。
Spark如何将程序运行在集群当中
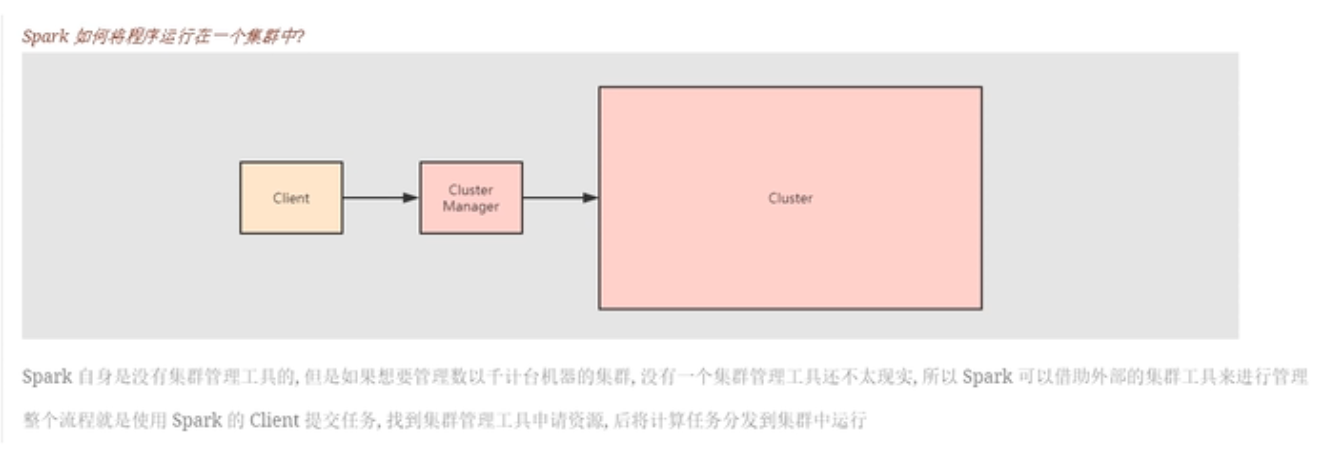
上面所说的工具就是集群管理器。Yarn,Mesos,StandAlone以及Kub都是spark可以使用的资源管理器。spark客户端提交过来的程序先由driver划分为多个任务(Task)(这里的任务是根据阶段(Stage)进行划分的),然后将任务提交到集群资源管理器上面,最后由集群管理器调度Task到集群中去执行。我们只是和集群资源管理器打交道,对于我们,集群就是一整台计算器。

worker是一个守护进程,对应集群中的每一个主机,运行任务是在Executor进程中运行。
Driver划分我们提交的程序为多个任务。
程序运行过程
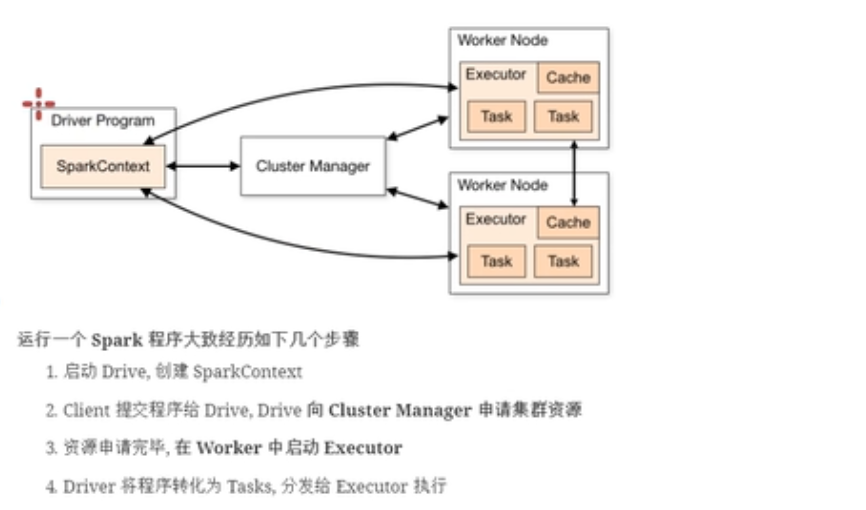
driver负责执行我们的main方法,负责创建程序执行的环境spark Centsxt,运行在Yarn上面有两种模式,这两种模式的区别就是Driver的运行位置不同:
- Clint模式:Driver运行在本地提交程序的客户端。
- cluster模式:Driver运行在集群当中,和applicationMaster在一台机器上面。
拓展一

拓展二
运行在不同的集群当中,启动的方式也不一样。
standalone模式下
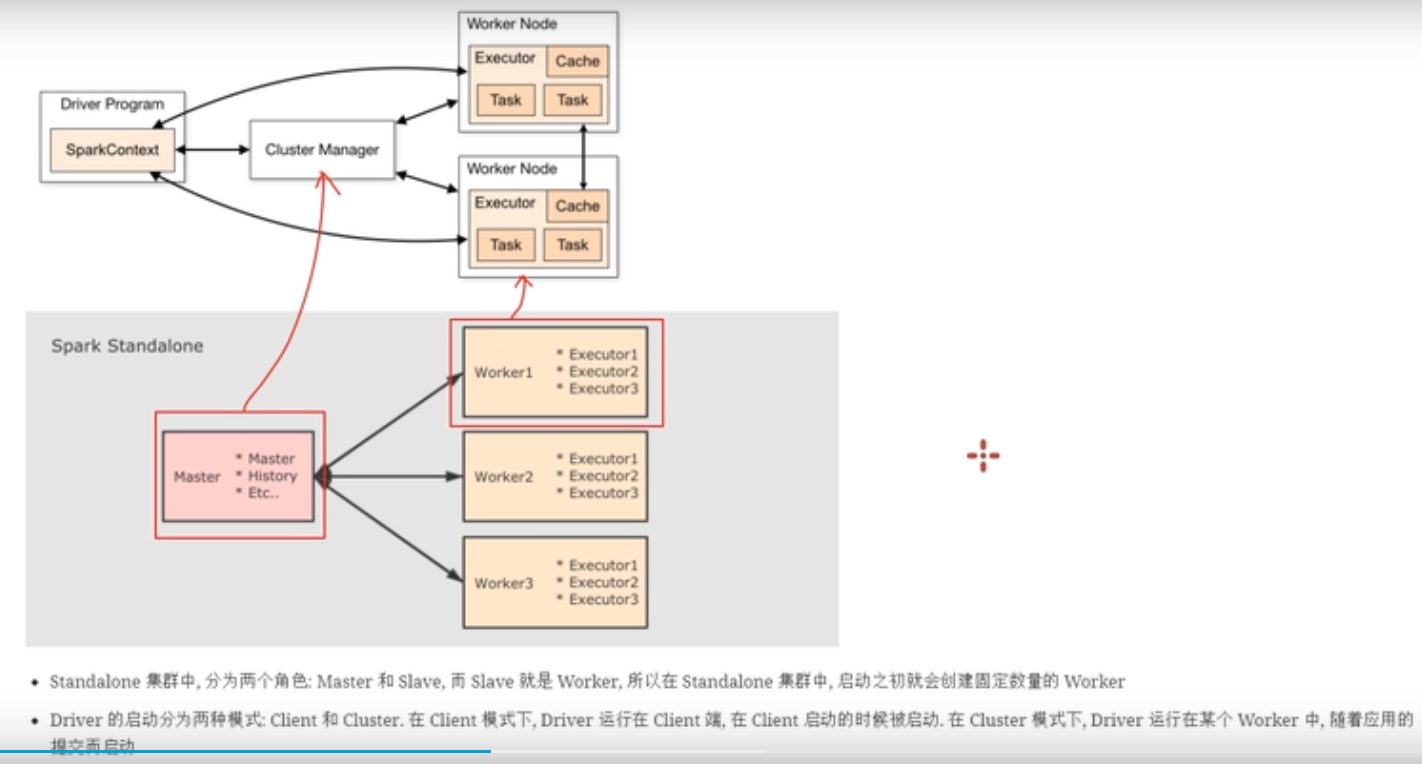
在standalone模式下面,分为两个组件,worker和master,而master就相当于集群管理器,也就是cluster manager,而worker就相当于worker node节点。master用于接收外部提交的任务,会把任务分发到不同的worker 中去执行,worker会启动相应的executor去执行任务。一个worker中可能会启动多个executor。因为这个集群是spark自己的,所以worker在集群启动的时候,就会被创建。
Driver的启动分为两种模式,clint模式和cluster模式:
- 如果是clint模式,也就是说driver运行在shell窗口或者命令行窗口中,在shell窗口中运行main方法就可以把程序划分为多个任务,然后在和集群进行交互,执行任务。问题就是不好管理资源。
- driver也可以运行在某一个worker当中,这种是cluster模式。
Yarn模式
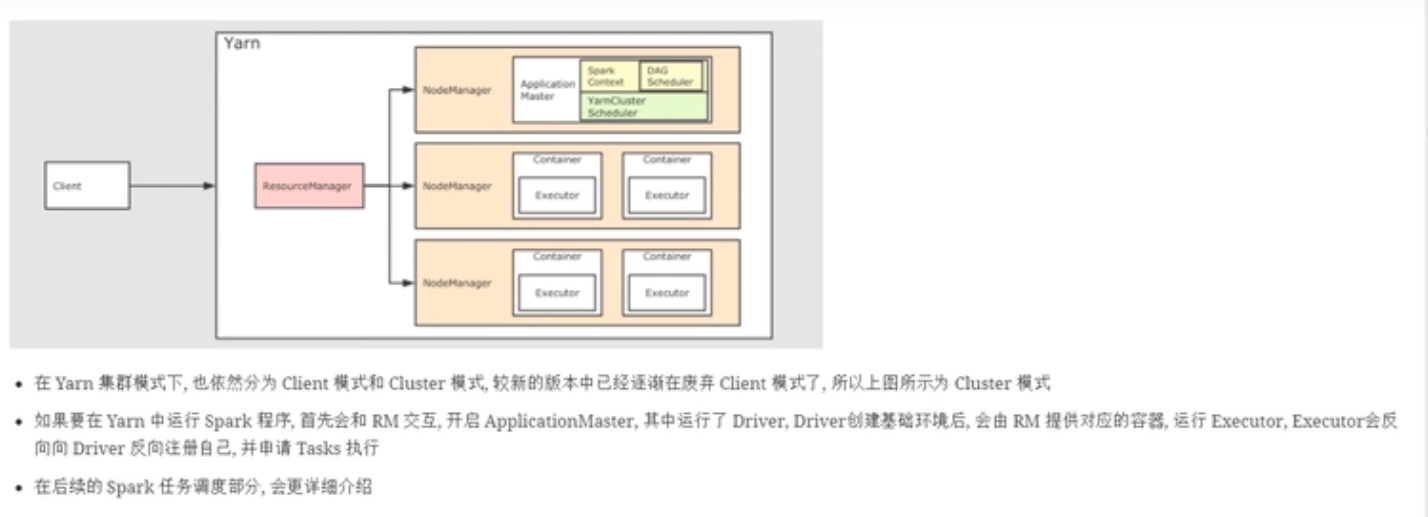
clint是spark带的客户端命令工具,当driver运行在这个命令行中的时候,是clint模式。当把任务提交到yarn当中运行的时候,首先还是和resourceManager进行交互,在yarn中运行程序,首先需要创建applicationMaster组件(作业的老大),这个applicationMaster来进行整个作业的资源申请和调度。
- driver也有两种运行位置,第一种是运行在applicationMaster中(cluster模式),其中cluster模式,driver运行在aplicationMaster当中。然后driver把程序划分为多个任务,application根据任务的个数,向resourcemanager申请资源运行任务。
- 另一种也就是运行在命令行窗口中。
小结

将Spark应用程序运行在集群上,比如Hadoop YARN集群,Spark 自身集群Standalone及Apache Mesos集群,
Standalone集群模式(学习测试使用):类似Hadoop YARN架构,典型的Mater/Slaves模式,
Standalone-HA高可用集群模式(学习测试/生产环境使用):使用Zookeeper搭建高可用,避免Master是有单点故障的。
On YARN集群模式(生产环境使用):运行在 yarn 集群之上,由 yarn 负责资源管理,Spark 负责任务调度和计算,好处:计算资源按需伸缩,集群利用率高,共享底层存储,避免数据跨集群迁移。
Apache Mesos集群模式(国内使用较少):运行在 Mesos 资源管理器框架之上,由Mesos 负责资源管理,Spark 负责任务调度和计算。
云服务:Kubernetes 模式
中小公司未来会更多的使用云服务,Spark 2.3开始支持将Spark 开发应用运行到K8s上。
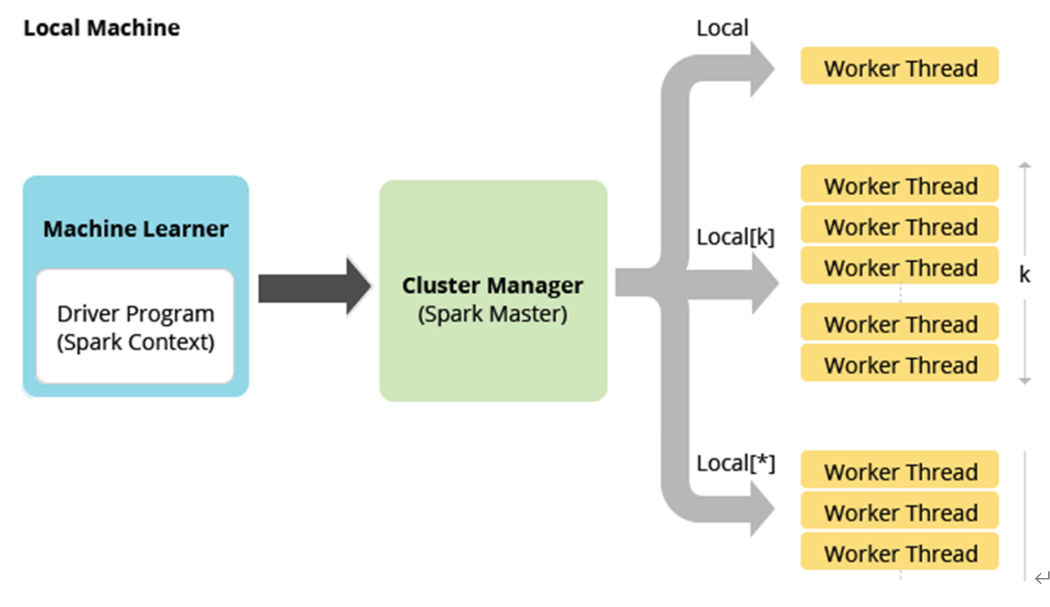
Local模式
将Spark 应用程序中任务Task运行在一个本地JVM Process进程中,通常开发测试使用。
在本地使用多线程模拟Spark集群中的各个角色
spark shell介绍

所谓的Local 模式,就是不需要其他任何节点资源就可以在本地执行 Spark 代码的环境,一般用于教学,调试,演示等, 之前在 IDEA 中运行代码的环境我们称之为开发环境,和本地模式不是一个概念。
解压缩文件
将 spark-3.0.0-bin-hadoop3.2.tgz 文件上传到Linux 并解压缩,放置在指定位置,路径中不要包含中文或空格。
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module cd /opt/module
mv spark-3.0.0-bin-hadoop3.2 spark-local启动 Local 环境
- 进入解压缩后的路径,执行如下指令
bin/spark-shell启动界面
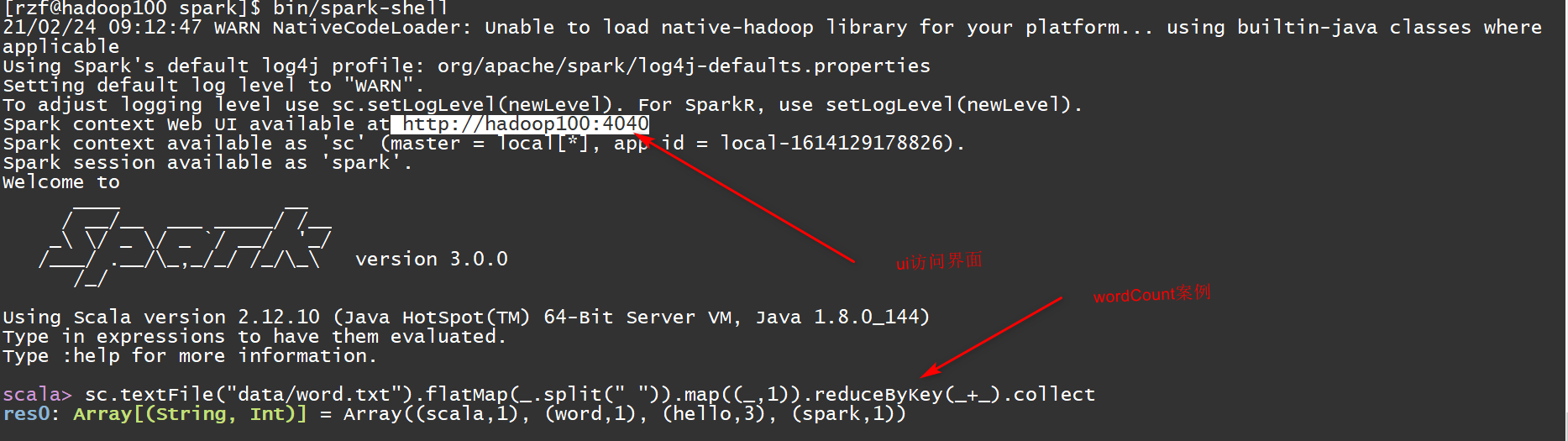
- sc:SparkContext实例对象:
- spark:SparkSession实例对象
- 4040:Web监控页面端口号
- 启动成功后,可以输入网址进行 Web UI 监控页面访问,默认的端口号是4040
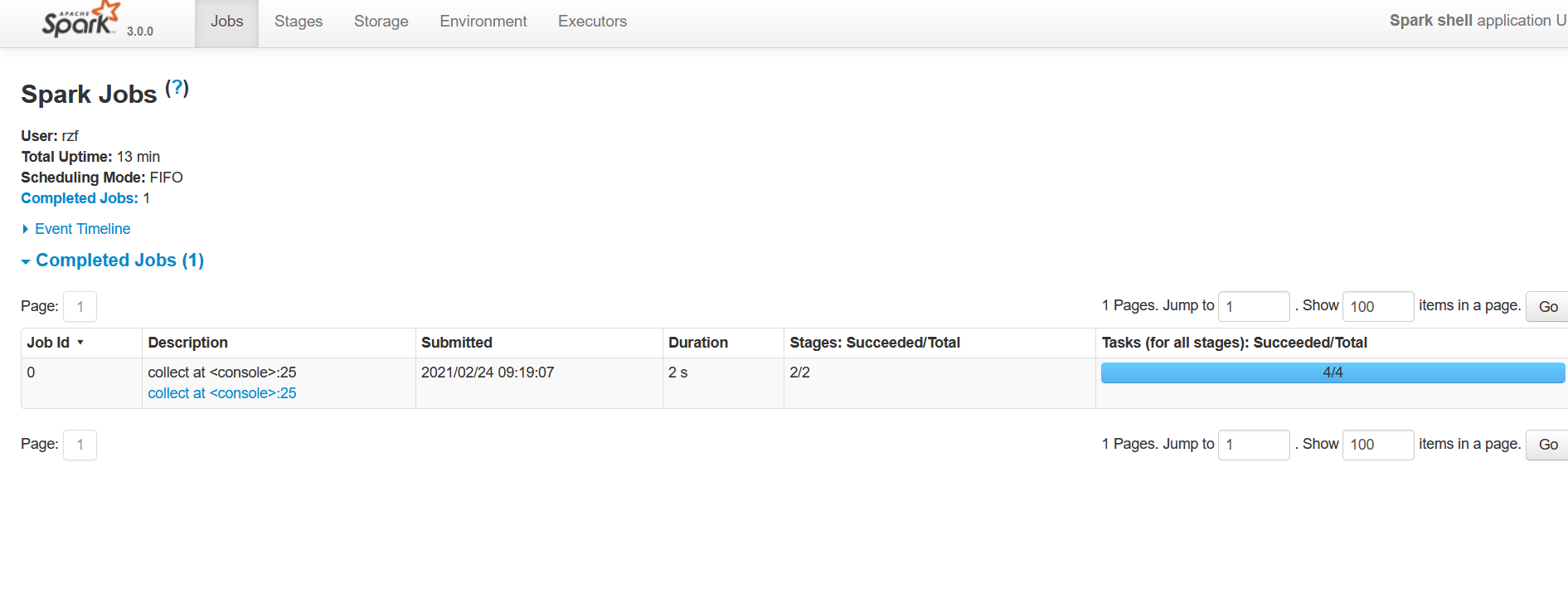
spark shell说明
- 直接使用./spark-shell,表示使用local 模式启动,在本机启动一个SparkSubmit进程。
- 还可指定参数 --master,如:
park-shell --master local[N] 表示在本地模拟N个线程来运行当前任务 spark-shell --master local[*] 表示使用当前机器上所有可用的资源
- 不携带参数默认就是
spark-shell --master local[*]
- 后续还可以使用--master指定集群地址,表示把任务提交到集群上运行,如
./spark-shell --master spark://node01:7077,node02:7077
退出本地模式
按键Ctrl+C 或输入 Scala 指令:quit
提交应用
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \ 这里表示是本地模式
./examples/jars/spark-examples_2.12-3.0.0.jar \ 10- --class 表示要执行程序的主类,此处可以更换为咱们自己写的应用程序,需要写全类名
- --master local[2] 部署模式,默认为本地模式,数字表示分配的虚拟CPU 核数量,线程数量
- spark-examples_2.12-3.0.0.jar 运行的应用类所在的 jar 包,实际使用时,可以设定为咱们自己打的 jar 包
- 数字 10 表示程序的入口参数,用于设定当前应用的任务数量
执行程序结果
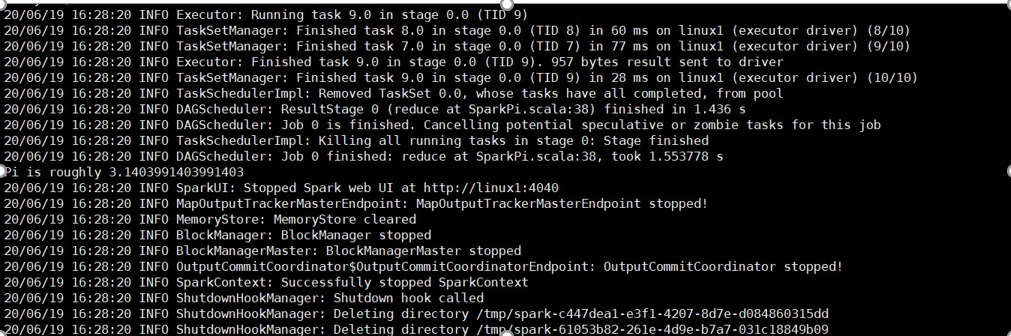
spark程序的web监控页面端口是4040
Standalone 模式
local 本地模式毕竟只是用来进行练习演示的,真实工作中还是要将应用提交到对应的集群中去执行,这里我们来看看只使用 Spark 自身节点运行的集群模式,也就是我们所谓的独立部署(Standalone)模式。
Spark 的 Standalone模式体现了经典的master-slave 模式(主从模式)。
Master和Worker是和资源有关的节点,driver和executor是和计算有关的节点。
Standalone模式是Spark自带的一种集群模式,不同于前面Local本地模式使用多线程模拟集群的环境,Standalone模式是真实地在多个机器之间搭建Spark集群的环境
- Standalone集群使用了分布式计算中的master-slave模型:
- master是集群中含有Master进程的节点(负责管理整个作业的资源调度)
- slave是集群中含有Executor进程的Worker节点worker负责管理一个节点上面分配的资源)
图解
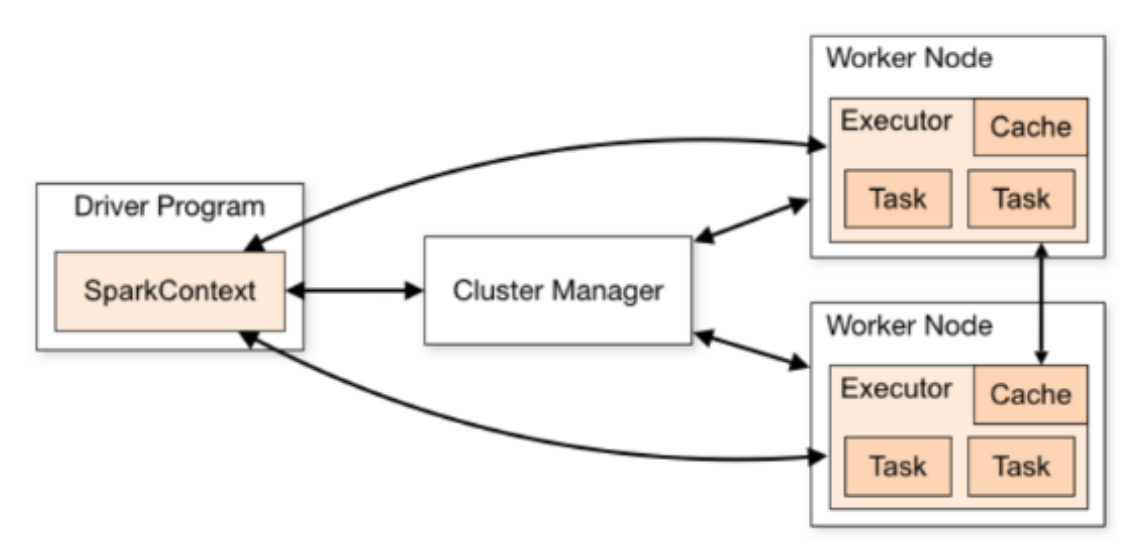
Spark Standalone集群,类似Hadoop YARN,管理集群资源和调度资源:
- 主节点Master:
管理整个集群资源,接收提交应用,分配资源给每个应用,运行Task任务
- 从节点Workers:
管理每个机器的资源,分配对应的资源来运行Task;
每个从节点分配资源信息给Worker管理,资源信息包含内存Memory和CPU Cores核数
- 历史服务器HistoryServer(可选):
Spark Application运行完成以后,保存事件日志数据至HDFS,启动HistoryServer可以查看应用运行相关信息。
集群规划
| Linux1 | Linux2 | Linux3 | |
|---|---|---|---|
| Spark | Worker Master | Worker | Worker |
解压缩文件
将 spark-3.0.0-bin-hadoop3.2.tgz 文件上传到Linux 并解压缩在指定位置
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module cd /opt/module
mv spark-3.0.0-bin-hadoop3.2 spark-standalone修改配置文件
- 进入解压缩后路径的 conf 目录,修改 slaves.template 文件名为 slaves
//修改文件名
mv slaves.template slaves
//修改slaves 文件,添加work 节点
hadoop100
hadoop101
hadoop102- 修改 spark-env.sh.template 文件名为 spark-env.sh
//修改文件名
mv spark-env.sh.template spark-env.sh
//修改 spark-env.sh 文件,添加 JAVA_HOME 环境变量和集群对应的 master 节点
export JAVA_HOME=/opt/module/jdk1.8.0_144
SPARK_MASTER_HOST=linux1 主机名称 master主机地址
SPARK_MASTER_PORT=7077 默认端口号,表示通过哪一个端口号链接集群- 注意:7077 端口,相当于 hadoop内部通信的 8020 端口,此处的端口需要确认自己的 Hadoop
- 分发 spark-standalone 目录
xsync spark启动集群
- 执行脚本命令:
//启动全部节点
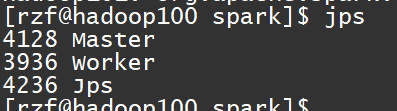
sbin/start-all.sh查看进程
hadoop100主机进程,其他节点都是从机,worker节点
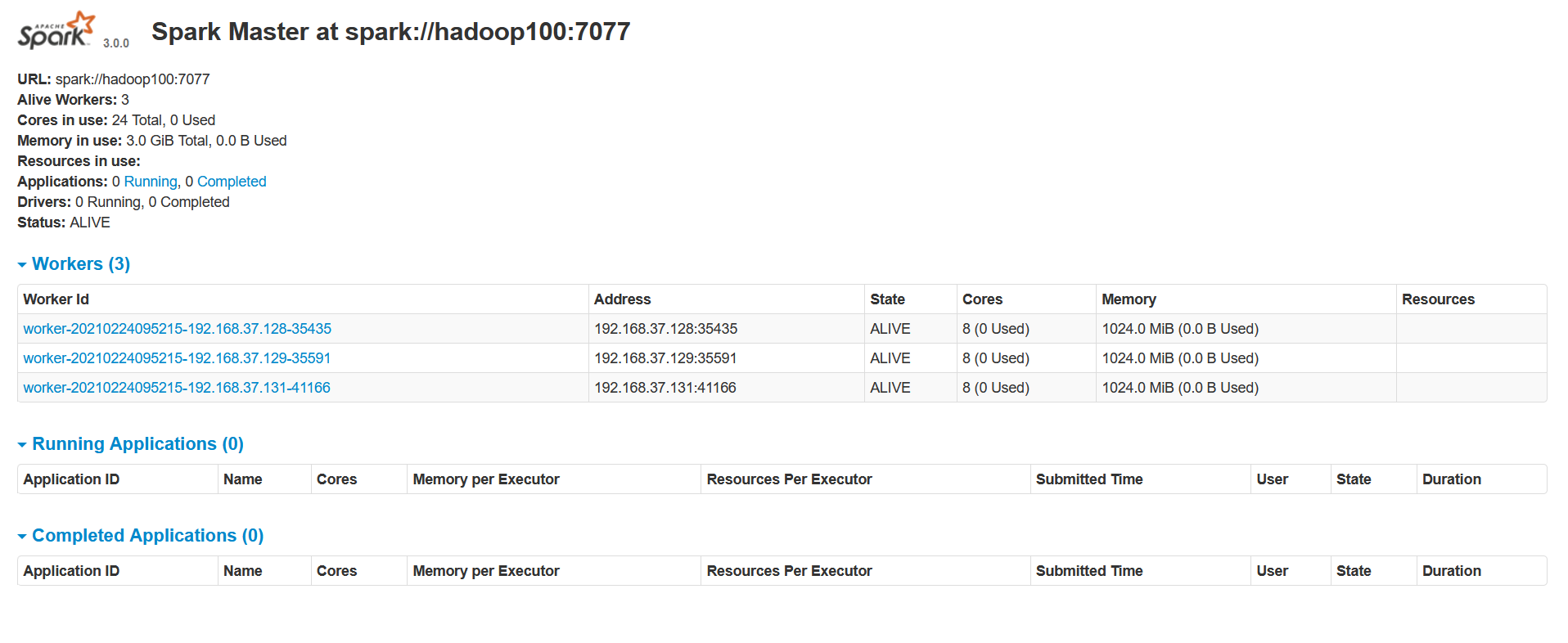
- 查看 Master 资源监控Web UI 界面:
http://linux1:8080,默认是通过8080端口访问
提交应用
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop100:7077 \ 这里是和本地模式的区别,通过master节点提交
./examples/jars/spark-examples_2.12-3.0.0.jar \ 10- --class 表示要执行程序的主类
- --master spark://hadoop100:7077 独立部署模式,连接到Spark 集群
- spark-examples_2.12-3.0.0.jar 运行类所在的 jar 包
- 数字 10 表示程序的入口参数,用于设定当前应用的任务数量
执行任务时,默认采用服务器集群节点的总核数,每个节点内存 1024M。
提交参数说明
在提交应用中,一般会同时一些提交参数
bin/spark-submit \
--class <main-class>
--master <master-url> \
... # other options
<application-jar> \ [application-arguments]| 参数 | 解释 | 可选值举例 |
|---|---|---|
| --class | Spark 程序中包含主函数的类 | |
| --master | Spark 程序运行的模式(环境) | 模式:local[*]、spark://linux1:7077、 Yarn |
| --executor-memory 1G | 指定每个 executor 可用内存为 1G | 符合集群内存配置即可,具体情况具体分析。 |
| --total-executor-cores 2 | 指定所有executor 使用的cpu 核数 为 2 个 | |
| --executor-cores | 指定每个executor 使用的cpu 核数 | |
| application-jar | 打包好的应用 jar,包含依赖。这 个 URL 在集群中全局可见。 比如 hdfs:// 共享存储系统,如果是file:// path, 那么所有的节点的 path 都包含同样的 jar | |
| application-arguments | 传给 main()方法的参数 |
配置历史服务
由于 spark-shell 停止掉后,集群监控 linux1:4040 页面就看不到历史任务的运行情况,所以开发时都配置历史服务器记录任务运行情况。
- 修改spark-defaults.conf.template 文件名为 spark-defaults.conf
mv spark-defaults.conf.template spark-defaults.conf- 修改 spark-default.conf 文件,配置日志存储路径
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop100:8020/directory注意:需要启动 hadoop 集群,HDFS 上的directory 目录需要提前存在
sbin/start-dfs.sh
hadoop fs -mkdir /directory- 修改 spark-env.sh 文件, 添加日志配置
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://hadoop100:8020/directory
-Dspark.history.retainedApplications=30"- 参数 1 含义:WEB UI 访问的端口号为 18080
- 参数 2 含义:指定历史服务器日志存储路径
- 参数 3 含义:指定保存Application 历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
- 分发配置文件
xsync conf/- 重新启动集群和历史服务
sbin/start-all.sh
sbin/start-history-server.sh- 重新执行任务
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop100:7077 \
./examples/jars/spark-examples_2.12-3.0.0.jar \ 10- 查看历史服务器
http://hadoop100:18080配置高可用( HA)
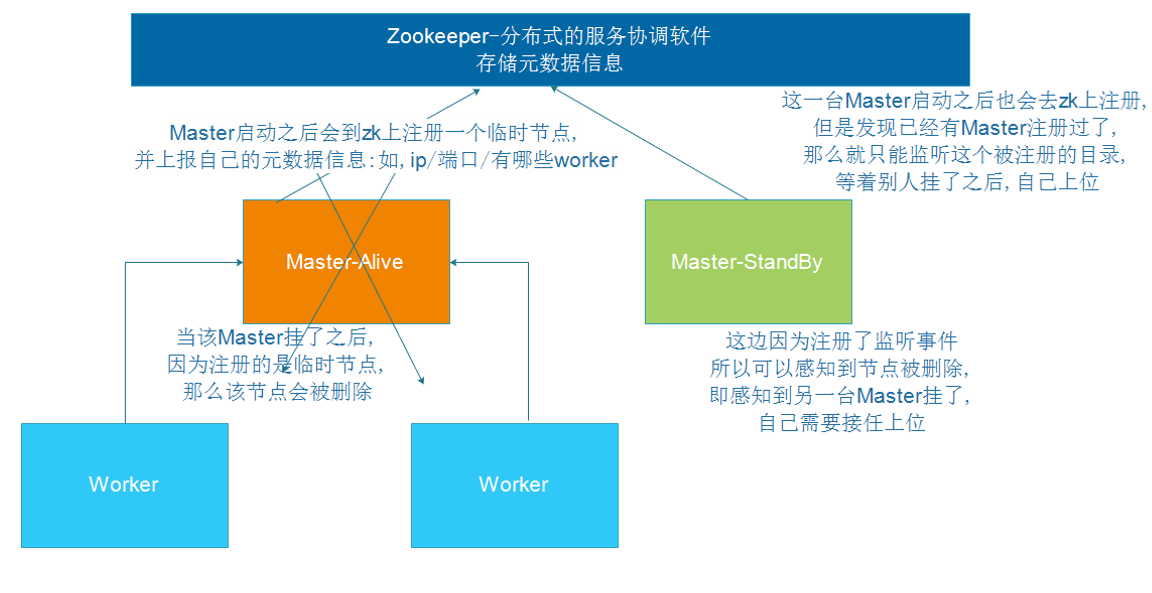
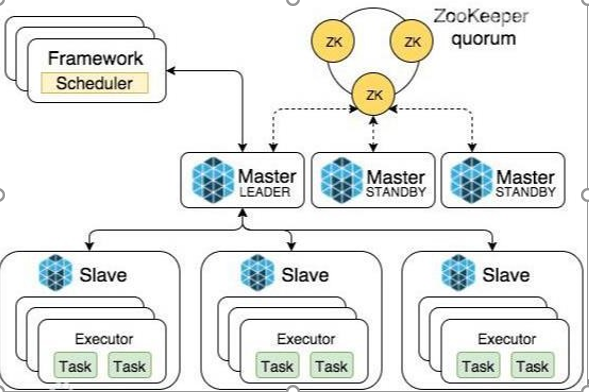
所谓的高可用是因为当前集群中的 Master 节点只有一个,所以会存在单点故障问题。所以为了解决单点故障问题,需要在集群中配置多个 Master节点,一旦处于活动状态的Master 发生故障时,由备用 Master 提供服务,保证作业可以继续执行。这里的高可用一般采用Zookeeper设置
Spark Standalone集群是Master-Slaves架构的集群模式,和大部分的Master-Slaves结构集群一样,存在着Master单点故障(SPOF)的问题。如何解决这个单点故障的问题,Spark提供了两种方案:
- 基于文件系统的单点恢复(Single-Node Recovery with Local File System)--只能用于开发或测试环境。
- 基于zookeeper的Standby Masters(Standby Masters with ZooKeeper)--可以用于生产环境。
ZooKeeper提供了一个Leader Election机制,利用这个机制可以保证虽然集群存在多个Master,但是只有一个是Active的,其他的都是Standby。当Active的Master出现故障时,另外的一个Standby Master会被选举出来。由于集群的信息,包括Worker, Driver和Application的信息都已经持久化到文件系统,因此在切换的过程中只会影响新Job的提交,对于正在进行的Job没有任何的影响。加入ZooKeeper的集群整体架构如下图所示。
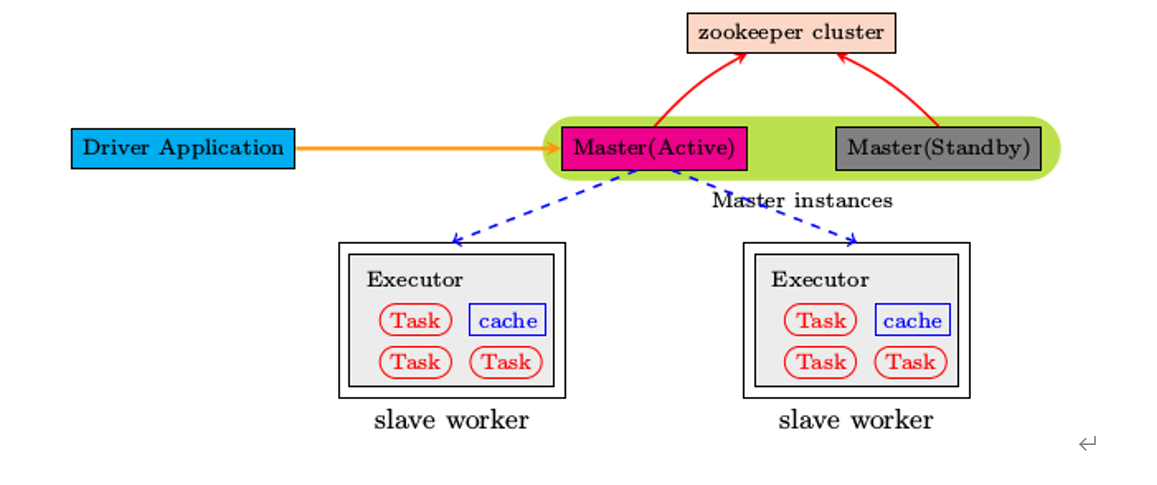
集群规划
| Linux1 | Linux2 | Linux3 | |
|---|---|---|---|
| Spark | Master Zookeeper Worker | Master Zookeeper Worker | Zookeeper Worker |
- 停止集群
sbin/stop-all.sh- 启动Zookeeper
bin/zkServer.sh start- 修改spark-env.sh 文件添加如下配置
//注 释 如 下 内 容 :
#SPARK_MASTER_HOST=linux1
#SPARK_MASTER_PORT=7077
//添加如下内容:
//#Master 监控页面默认访问端口为 8080,但是可能会和 Zookeeper 冲突,所以改成 8989,也可以自定义,访问 UI 监控页面时请注意
SPARK_MASTER_WEBUI_PORT=8989
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=hadoop100,hadoop101,hadoop102
-Dspark.deploy.zookeeper.dir=/spark"- 分发配置文件
xsync conf/- 在hadoop100节点上启动集群
[rzf@hadoop100 spark]$ sbin/start-all.shhadoop100节点

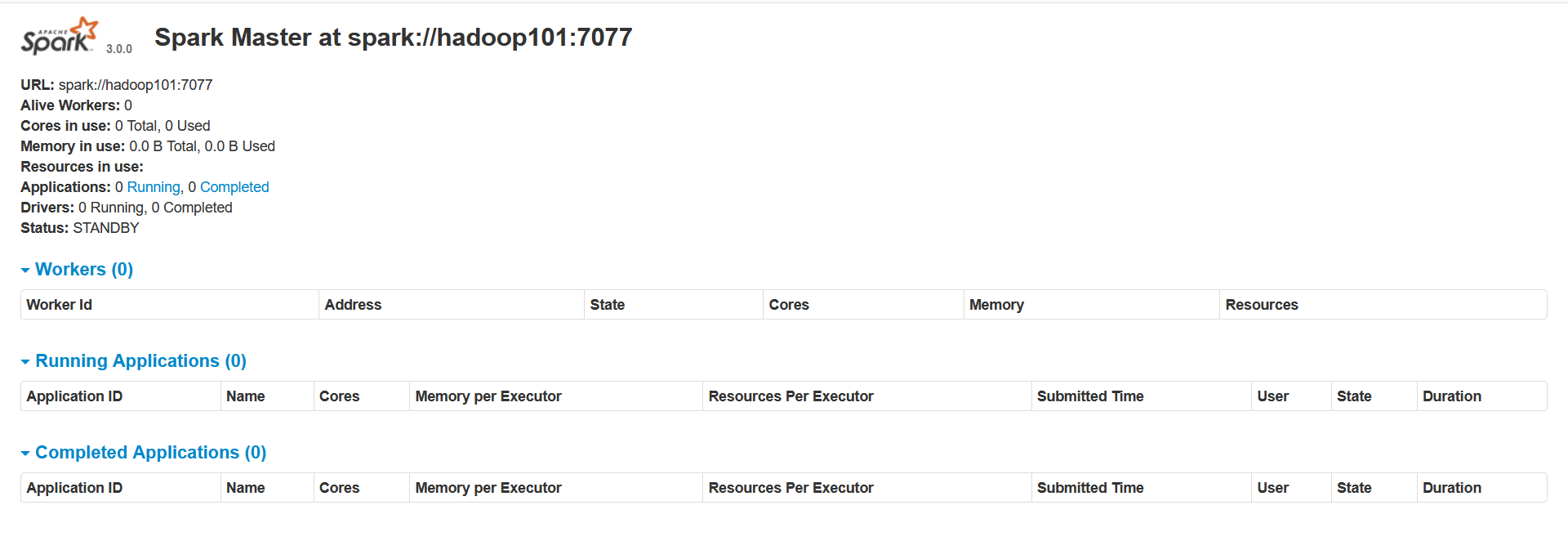
- 起 动 hadoop101 的单独 Master 节点,此时 hadoop101 节点 Master 状态处于备用状态
[rzf@hadoop101 spark]$ sbin/start-master.sh此时hadoop101节点出现备用的master

备用节点ui界面
- 提交应用到集群
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop100:7077,hadoop101:7077 \
./examples/jars/spark-examples_2.12-3.0.0.jar \ 10- 停止 hadoop100 的 Master 资源监控进程
kill -9 6790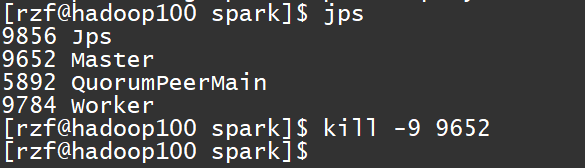
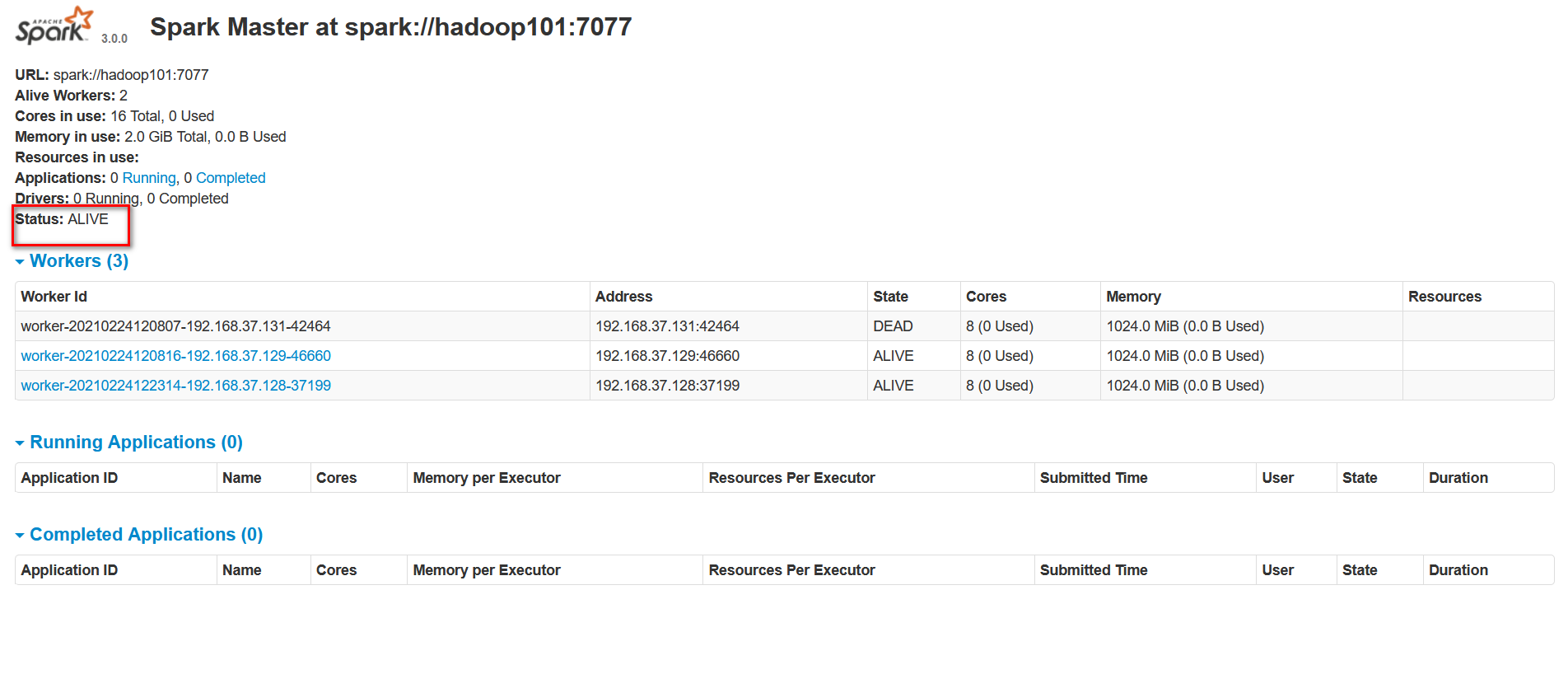
- 查看 hadoop101的 Master 资源监控Web UI,稍等一段时间后,hadoop101节点的 Master 状态提升为活动状态,可以看到,主节点出现故障后,从节点会代替主节点。
Yarn 模式
独立部署(Standalone)模式由 Spark自身提供计算资源,无需其他框架提供资源。这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但是你也要记住,Spark 主要是计算框架,而不是资源调度框架,所以本身提供的资源调度并不是它的强项,所以还是和其他专业的资源调度框架集成会更靠谱一些。所以接下来我们来学习在强大的Yarn 环境下 Spark是如何工作的(其实是因为在国内工作中,Yarn 使用的非常多)。
在集群模式中,用户将编译过的jar包提交给集群管理器(可能是yarn),除了执行器进程之外,集群管理器还会在集群内部的某一个工作节点上面启动驱动器进程,这意味着集群管理器负责维护所有的与spark应用相关的进程。
注意:
- SparkOnYarn的本质是把Spark任务的class字节码文件打成jar包,上传到Yarn集群的JVM中去运行!
- Spark集群的相关角色(JVM进程)也会在Yarn的JVM中运行
- SparkOnYarn需要:
- 修改一些配置,让支持SparkOnYarn
- Spark程序打成的jar包--可以先使用示例jar包spark-examples_2.11-3.0.1.jar,也可以后续使用我们自己开发的程序打成的jar包
- Spark任务提交工具:bin/spark-submit
- Spark本身依赖的jars:在spark的安装目录的jars中有,提交任务的时候会被上传到Yarn/HDFS,或手动提前上传上
- SparkOnYarn不需要Spark集群,只需要一个单机版spark解压包即可(有示例jar, 有spark-submit,有依赖的jars)
- SparkOnYarn根据Driver运行在哪里分为2种模式:client模式和cluster模式
解压文件
将 spark-3.0.0-bin-hadoop3.2.tgz 文件上传到linux 并解压缩,放置在指定位置。
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module cd /opt/module
mv spark-3.0.0-bin-hadoop3.2 spark-yarn修改配置文件
- 修改 hadoop 配置文件/opt/module/hadoop/etc/hadoop/yarn-site.xml, 并且分发
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是 true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是 true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>- 修改 conf/spark-env.sh,添加 JAVA_HOME 和YARN_CONF_DIR配置
export JAVA_HOME=/opt/module/jdk1.8.0_144
YARN_CONF_DIR=/opt/module/hadoop-2.7.2/etc/hadoop- 分发spark
//这里不再需要分发spark,因为yarn只是部署在一台节点上面
xsync spark-yarn启动 HDFS 以及 YARN 集群
//启动hdfs
sbin/start-dfs.sh
//启动yarn
sbin/start-yarn.sh
//启动spark集群
sbin/start-all.sh提交应用
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \ 表示运行在yarn上
--deploy-mode cluster \ 集群方式启动运行
./examples/jars/spark-examples_2.12-3.0.0.jar \ 10查看http://hadoop101:8088页面,点击History,查看历史页面
配置历史服务器
- 修改 spark-defaults.conf.template 文件名为 spark-defaults.conf
mv spark-defaults.conf.template spark-defaults.conf- 修改 spark-default.conf 文件,配置日志存储路径
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop100:8020/directory注意:需要启动 hadoop 集群,HDFS 上的目录需要提前存在
- 修改 spark-env.sh 文件, 添加日志配置
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://hadoop100:8020/directory
-Dspark.history.retainedApplications=30"- 参数 1 含义:WEB UI 访问的端口号为 18080,
- 参数 2 含义:指定历史服务器日志存储路径
- 参数 3 含义:指定保存Application 历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
- 修改 spark-defaults.conf
spark.yarn.historyServer.address=hadoop100:18080
spark.history.ui.port=18080- 启动历史服务
sbin/start-history-server.sh- 提交应用
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.12-3.0.0.jar \ 10两种模式
当一个MR应用提交运行到Hadoop YARN上时
包含两个部分:
应用管理者ApplicationMaster(代表一个作业的老大)
任务进程(如MapReduce程序MapTask和ReduceTask任务)
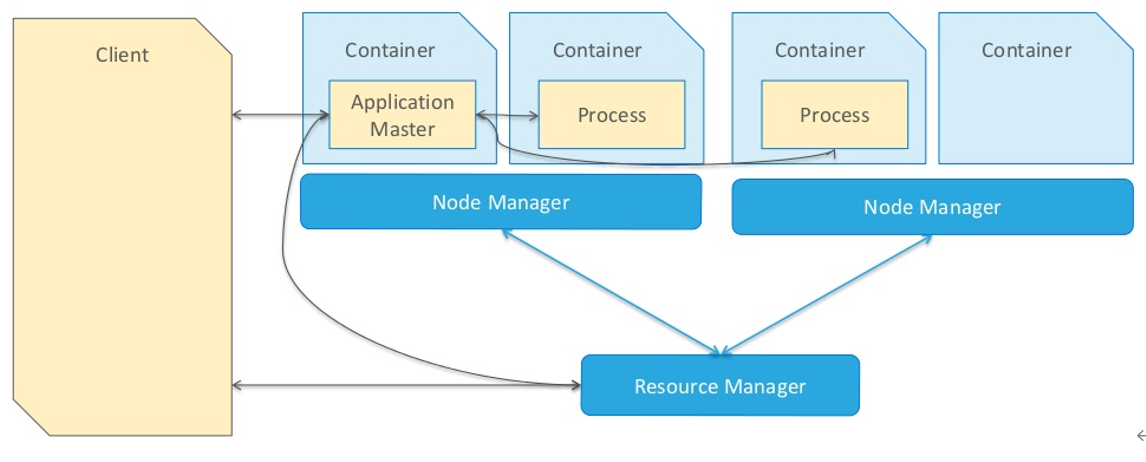
注意:在一个节点上面可以启动多个Container,一个容器可以运行一个Executor进程。
当一个Spark应用提交运行在集群上时,应用架构有两部分组成:
- Driver Program(资源申请和调度Job执行,负责将我们编写的代码分为多个任务Task)。
- Executors(运行Job中Task任务和缓存数据)。
他们都是jvm进程
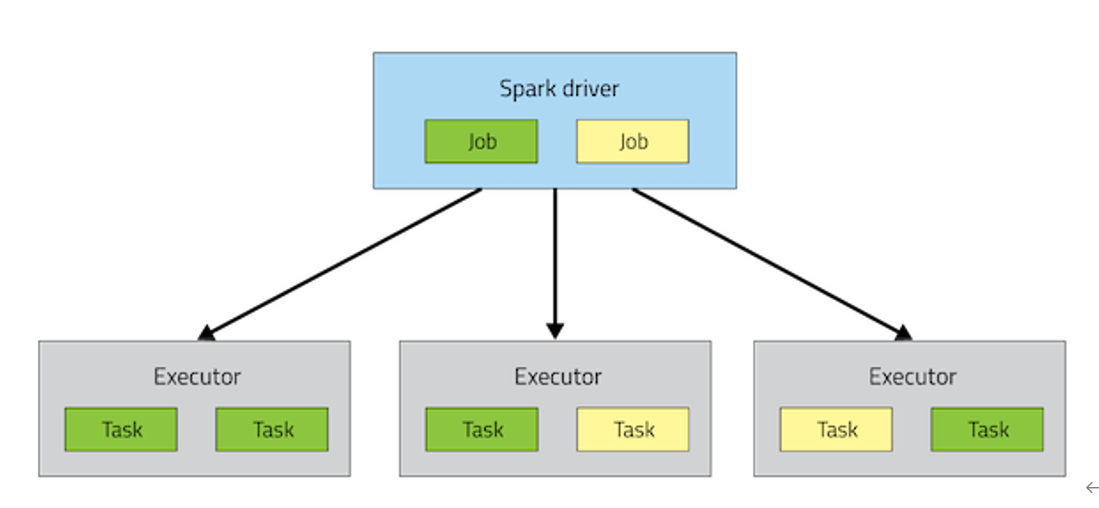
Executor是一个进程,运行Task是线程。
而Driver程序运行的位置可以通过--deploy-mode 来指定,值可以是:
- client:表示Driver运行在提交应用的Client上(默认)
- cluster表示Driver运行在集群中(YARN的NodeManager)
Driver是什么:
The process running the main() function of the application and creating the SparkContext
运行应用程序的main()函数并创建SparkContext的进程。
注意
cluster和client模式最最本质的区别是:Driver程序运行在哪里。企业实际生产环境中使用cluster模式
Clint模式
client模式下:
Spark 的Driver驱动程序, 运行在提交任务的客户端上,(也就是命令行窗口), 和集群的通信成本高!因为在运行作业的过程中,Driver需要调度Task到集群的某一个具体节点上执行,并且在任务在执行完成后,还需要由Driver汇总最终的结果,所以会存在其他节点和Driver进程之间的通信。
因为Driver在客户端,所以Driver中的程序结果输出可以在客户端控制台看到
这种情况下Driver是在客户端,不受RM管理,所以job失败后灭有重试机制。
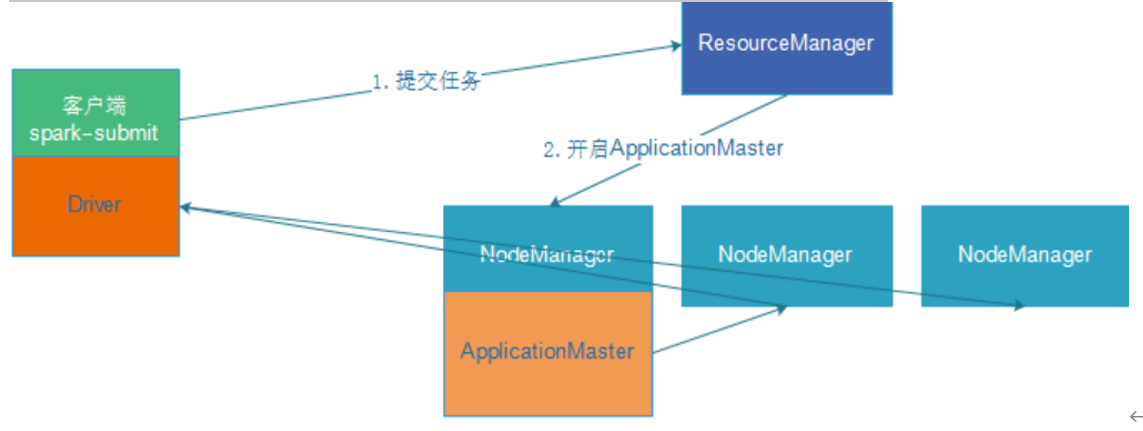
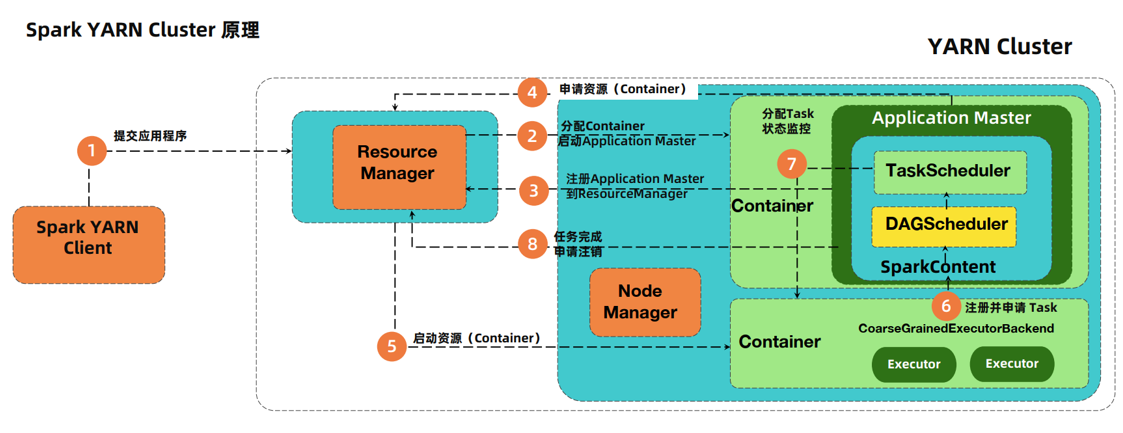
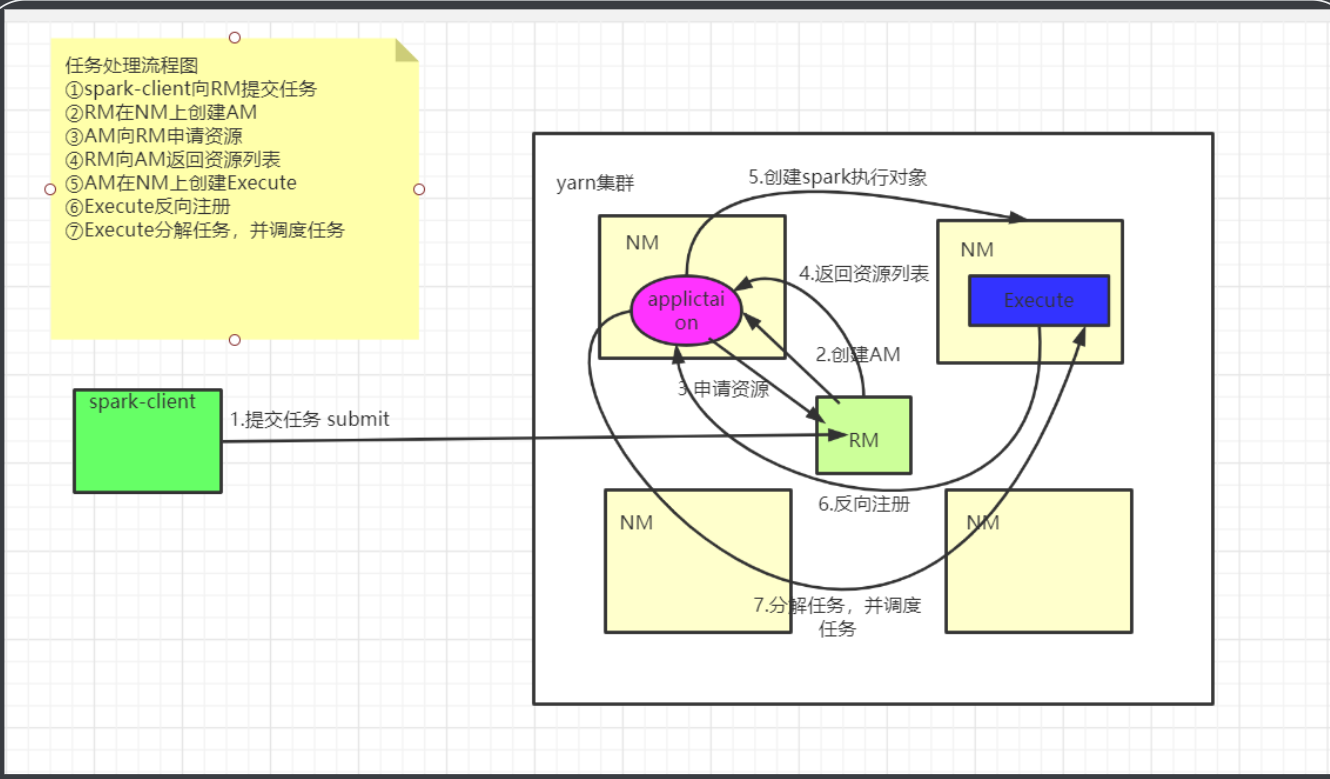
Spark Yarn Client原理
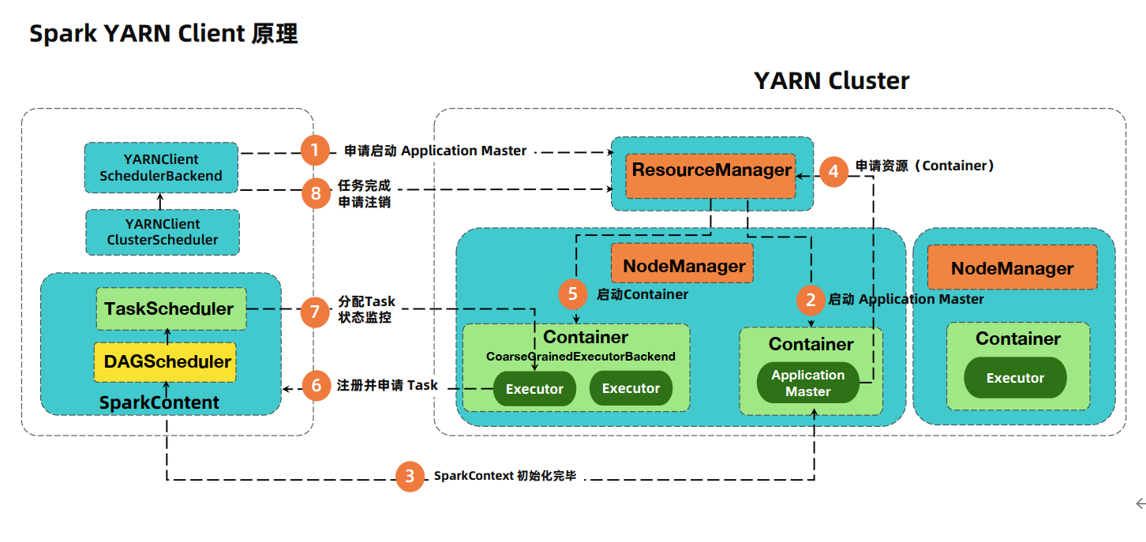
详解
- Yarn是通过ScheduleBackend来和向RM通信发送消息,告知RM申请启动一个ApplicationMaster。
- RM寻找一台空闲的NodeManager节点,然后在节点上面启动Container容器,容器启动后,在容器里面启动ApplicationMaster进程,启动后会去RM进程注册自己。
- 此时在client端的Driver已经把job分为多个Task,并且已经初始化好SparkContext环境。
- Driver和ApplicationMaster进行通信,把需要申请的资源告诉Application进程,包括数据,资源的位置。
- ApplicationMaster进程找到RM进行申请资源。
- RM根据资源请求的数量,找到一定数量的NodeManager,如果不够的话,会先分配一定数量的NodeManager,然后在NodeManager上面启动Container。
- 各个Container启动之后会在容器内启动Executor,然后各个 Executor进程会去Driver进程哪里注册自己,告诉Driver自己由多少资源,然后申请一定数量的Task.
- Driver根据情况把Task分配给Executor进程,并且监控各个Task的状态,Executor根据资源的状况,去hdfs上面加载数据然后执行。
- 等到任务执行完成后,Driver会向RM申请注销自己,job执行完成。
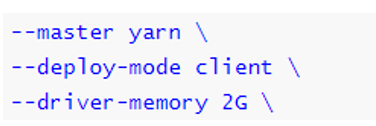
运行圆周率PI程序,采用client模式,命令如下:
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \
--master yarn \
--deploy-mode client \
--driver-memory 512m \
--driver-cores 1 \
--executor-memory 512m \
--num-executors 2 \
--executor-cores 1 \
--class org.apache.spark.examples.SparkPi \
${SPARK_HOME}/examples/jars/spark-examples_2.12-3.0.1.jar \
10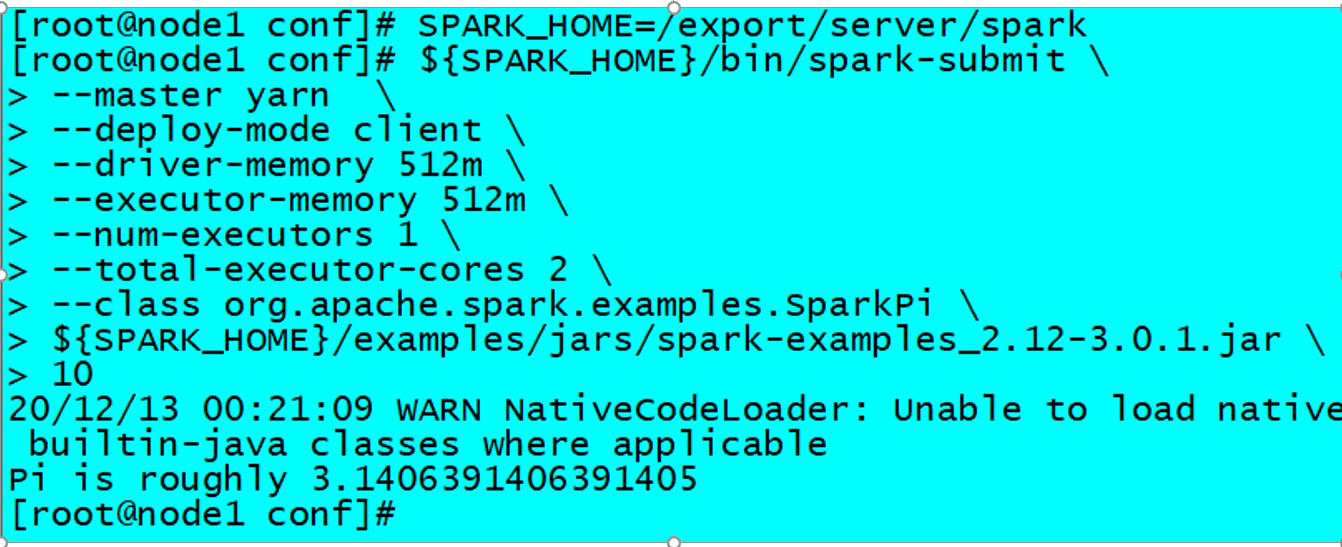
Cluster模式
cluster模式下:
- Spark 的Driver驱动程序, 运行在Yarn集群上, 和集群的通信成本低!
- 且Driver是交给Yarn管理的,如果失败会由Yarn重启。
- 因为Driver运行在Yarn上,所以Driver中的程序结果输出在客户端控制台看不到,在Yarn日志中看到。
- cluster模式下,Driver进程和ApplicationMaster进程一般在同一个节点上,同受RM监控,所以作业失败会重试。
任务提交过程
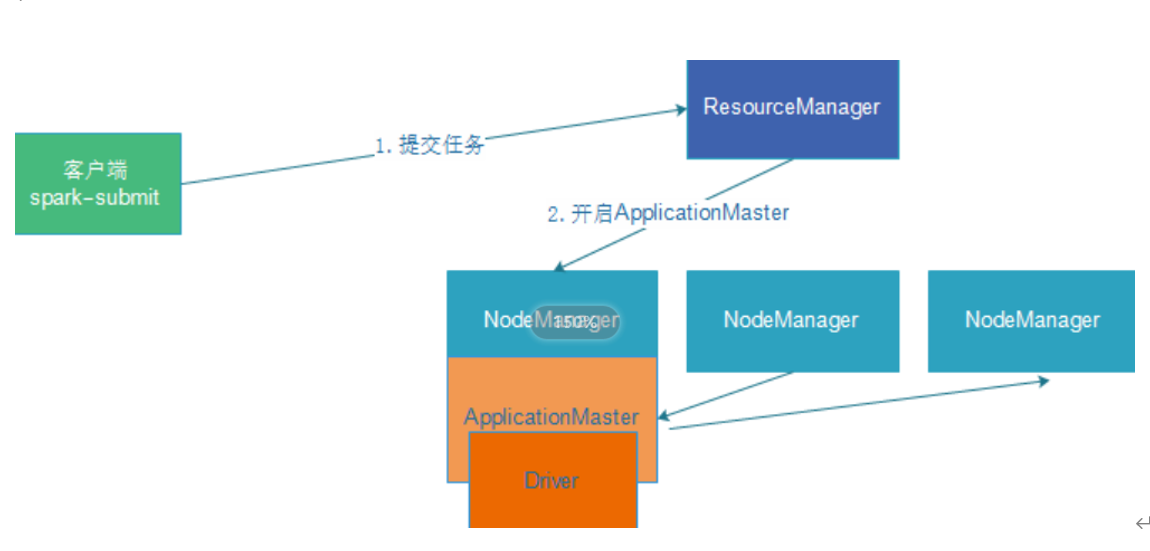
详细提交过程
过程解释
- 客户端提交作业到RM,RM找到一个空闲的节点,启动容器,然后在容器中启动ApplicationMaster进程。
- ApplicationMaster启动之后,会到RM上面去注册自己。
- 此时Driver已经在ApplicationMaster所在的节点上面启动,并且初始化运行环境,然后和ApplicationMaster进程通信,告诉ApplicationMaster进程自己所需要的资源,以及资源所在的路径。
- ApplicationMaster向RM申请启动一定数量的资源。
- RM找到空闲的NodeMnager并且启动一定的Container和Executor进程。
- Executor启动之后去Driver进程哪里注册自己,并申请起订数量的任务,Executor申请到任务之后,去hdfs上面加载所需要的数据,然后执行Task.在执行的过程中,Driver进程一直在监控各个任务的执行状态。
- 等到所有的任务全部执行完成,Driver向RM申请注销自己。作业完成。
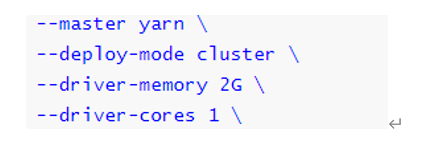
运行圆周率PI程序,采用cluster模式,命令如下:
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \
--master yarn \
--deploy-mode cluster \
--driver-memory 512m \
--executor-memory 512m \
--num-executors 1 \
--class org.apache.spark.examples.SparkPi \
${SPARK_HOME}/examples/jars/spark-examples_2.12-3.0.1.jar \
10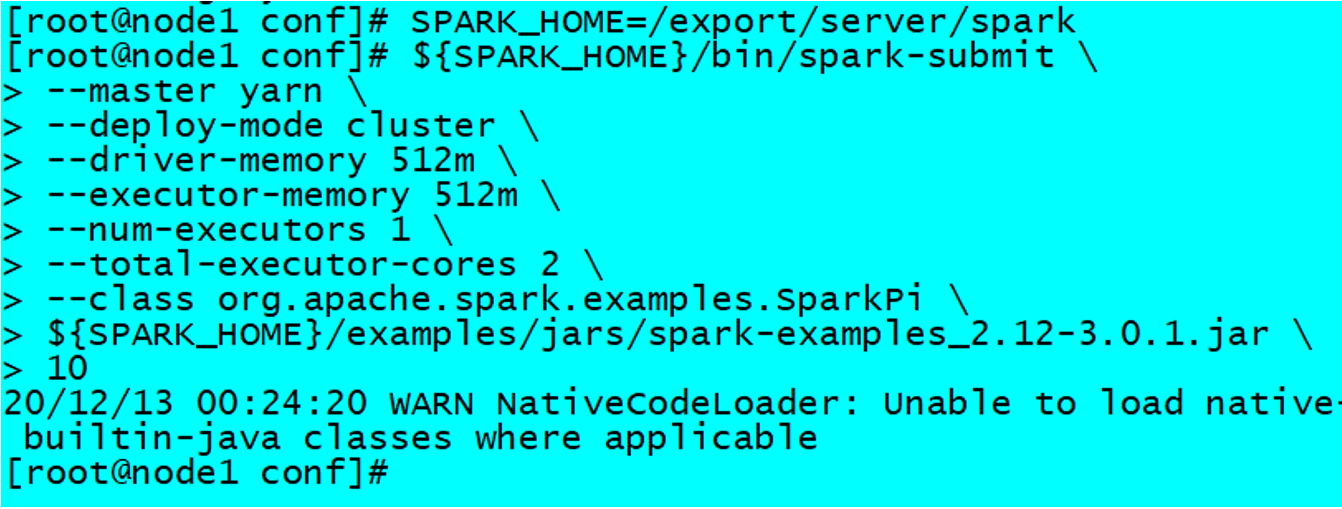
不管是哪一种模式,由两个组件在负责作业的执行: Application可以认为是一个作业的老大,负责作业资源的申请。
Driver:负责划分我们的作业为多个Stage和Task,并且调度各个Task到Executor去执行,最后汇总结果。
上面这两个进程,ApplicationMaster是属于Yarn的组件,所以是负责一个作业的资源分配,而Driver是属于Spark组件,主要是负责作业的执行监控和调度,这两者之间还需要通信,因为Driver需要根据资源的多少去分配Task执行。
小结
Client模式和Cluster模式最最本质的区别是:Driver程序运行在哪里。
- Client模式:学习测试时使用,开发不用,了解即可
- Driver运行在Client上,和集群的通信成本高
- Driver输出结果会在客户端显示
- Cluster模式:生产环境中使用该模式
- Driver程序在YARN集群中,和集群的通信成本低
- Driver输出结果不能在客户端显示
- 该模式下Driver运行ApplicattionMaster这个节点上,由Yarn管理,如果出现问题,yarn会重启ApplicattionMaster(Driver)
两种模式详解
clint模式
在YARN Client模式下,Driver在任务提交的本地机器上运行,示意图如下:
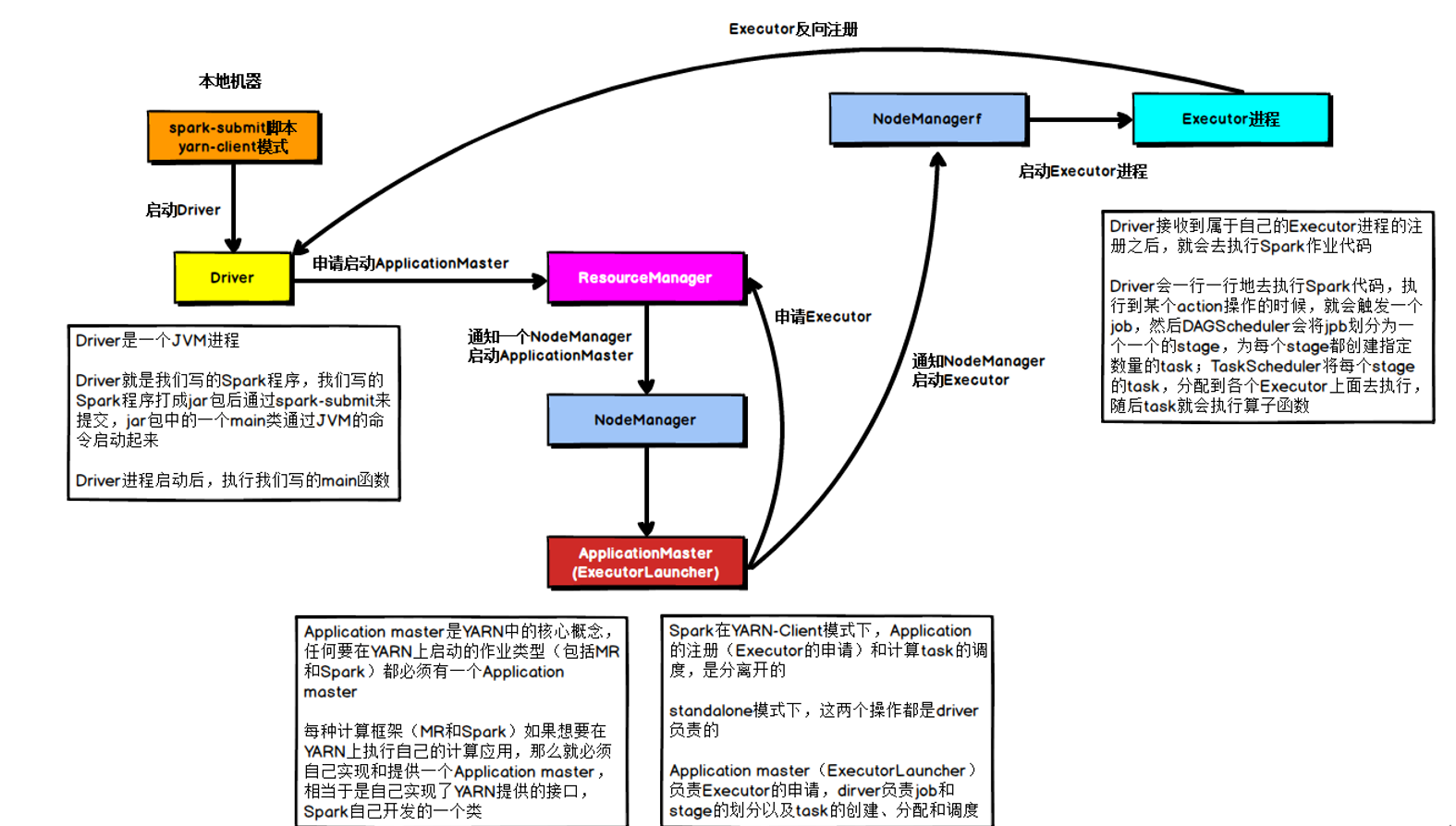
具体流程
- Driver在任务提交的本地机器上运行,Driver启动后会和ResourceManager通讯申请启动ApplicationMaster;
- 随后ResourceManager分配Container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster的功能相当于一个ExecutorLaucher,只负责向ResourceManager申请Executor内存;

- ResourceManager接到ApplicationMaster的资源申请后会分配Container,然后ApplicationMaster在资源分配指定的NodeManager上启动Executor进程;
- Executor进程启动后会向Driver反向注册,Executor全部注册完成后Driver开始执行main函数;
- 之后执行到Action算子时,触发一个Job,并根据宽依赖开始划分Stage,每个Stage生成对应的TaskSet,之后将Task分发到各个Executor上执行。
Cluster模式
在YARN Cluster模式下,Driver运行在NodeManager Contanier中,此时Driver与AppMaster合为一体,示意图如下:
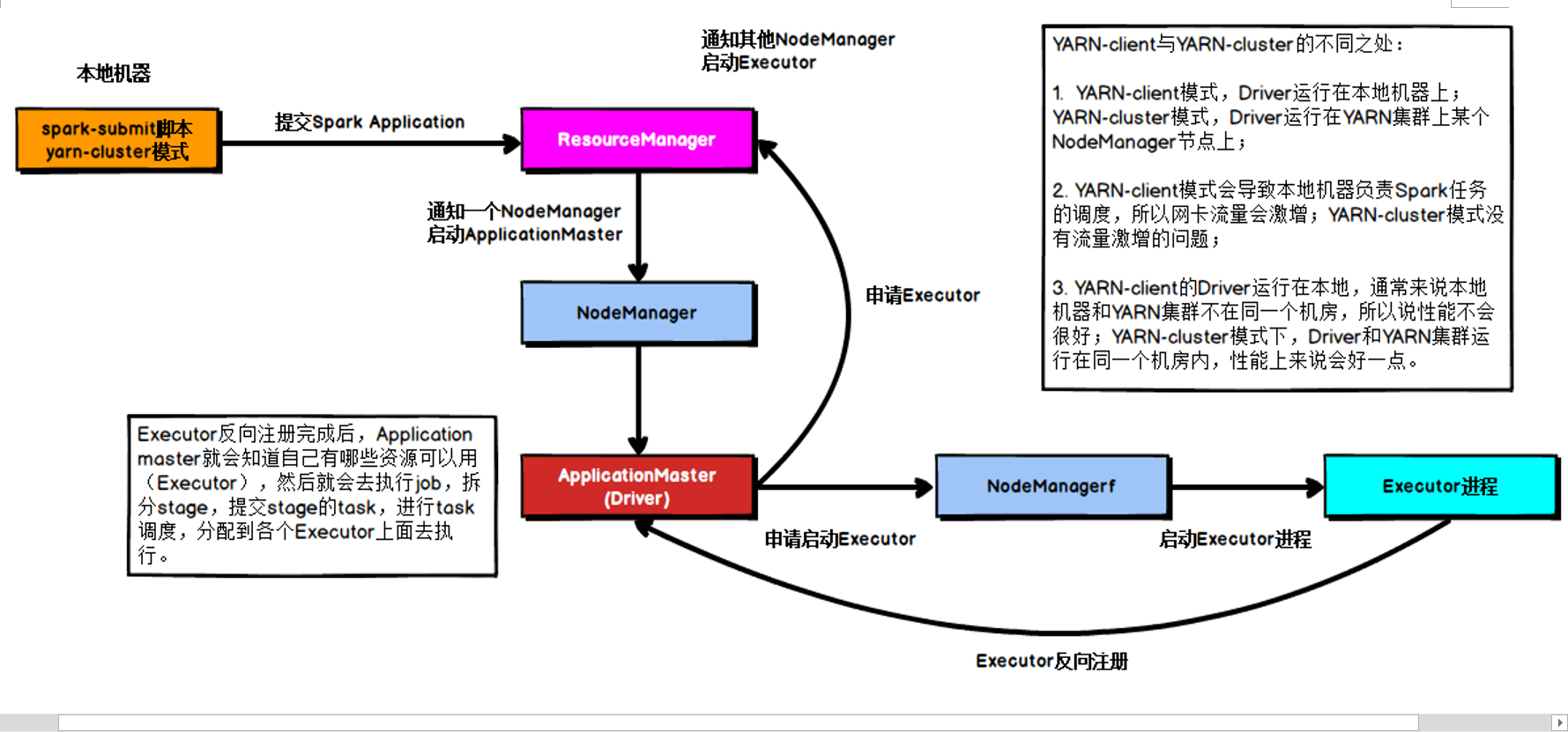
提交流程
- 任务提交后会和ResourceManager通讯申请启动ApplicationMaster;
- 随后ResourceManager分配Container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster就是Driver;
- Driver启动后向ResourceManager申请Executor内存,ResourceManager接到ApplicationMaster的资源申请后会分配Container,然后在合适的NodeManager上启动Executor进程;
- Executor进程启动后会向Driver反向注册;
- Executor全部注册完成后Driver开始执行main函数,之后执行到Action算子时,触发一个job,并根据宽依赖开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行;
Spark集群角色
当Spark Application运行在集群上时,主要有四个部分组成,如下示意图:
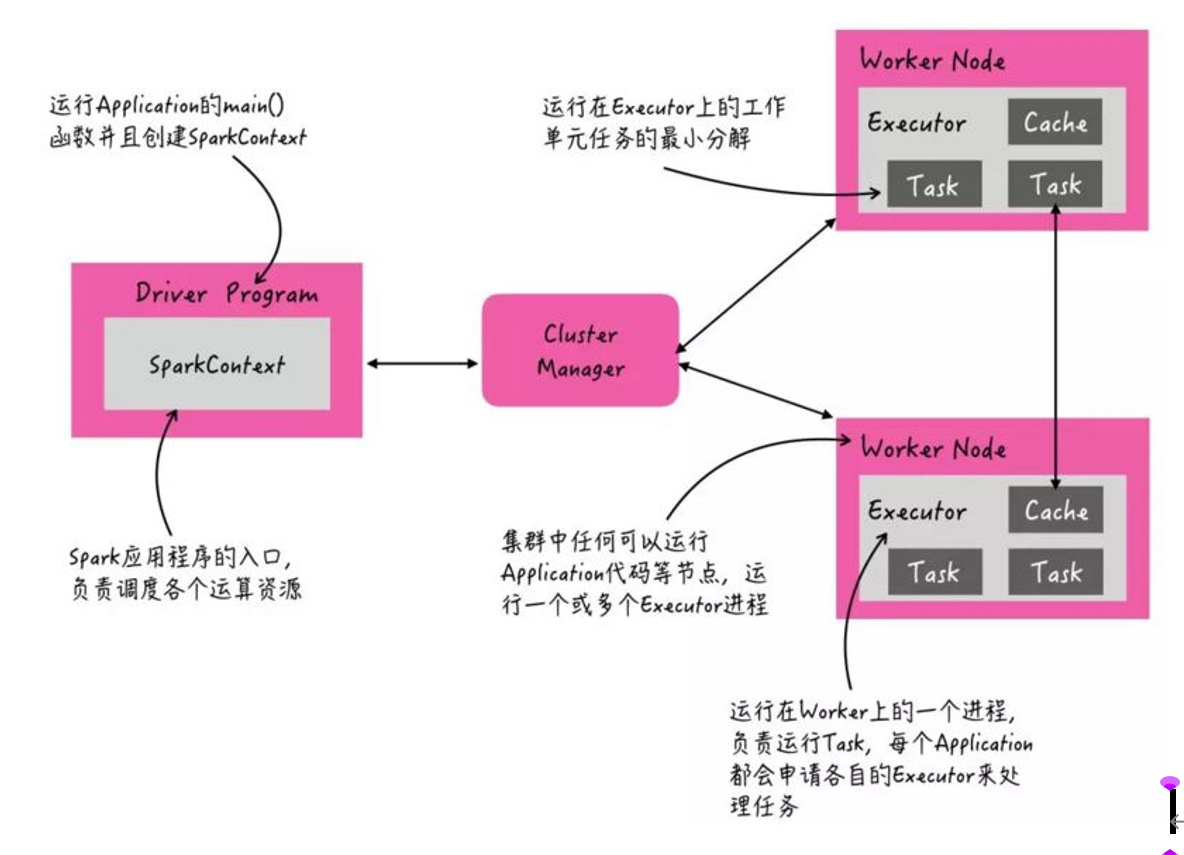
1、Driver:是一个JVM Process 进程,编写的Spark应用程序就运行在Driver上,由Driver进程执行;
2)、Master(ResourceManager):是一个JVM Process 进程,主要负责资源的调度和分配,并进行集群的监控等职责;
3)、Worker(NodeManager):是一个JVM Process 进程,一个Worker运行在集群中的一台服务器上,主要负责两个职责,一个是用自己的内存存储RDD的某个或某些partition;另一个是启动其他进程和线程(Executor),对RDD上的partition进行并行的处理和计算。
4)、Executor:是一个JVM Process 进程,一个Worker(NodeManager)上可以运行多个Executor,Executor通过启动多个线程(task)来执行对RDD的partition进行并行计算,也就是执行我们对RDD定义的例如map、flatMap、reduce等算子操作。
spark-shell和spark-submit
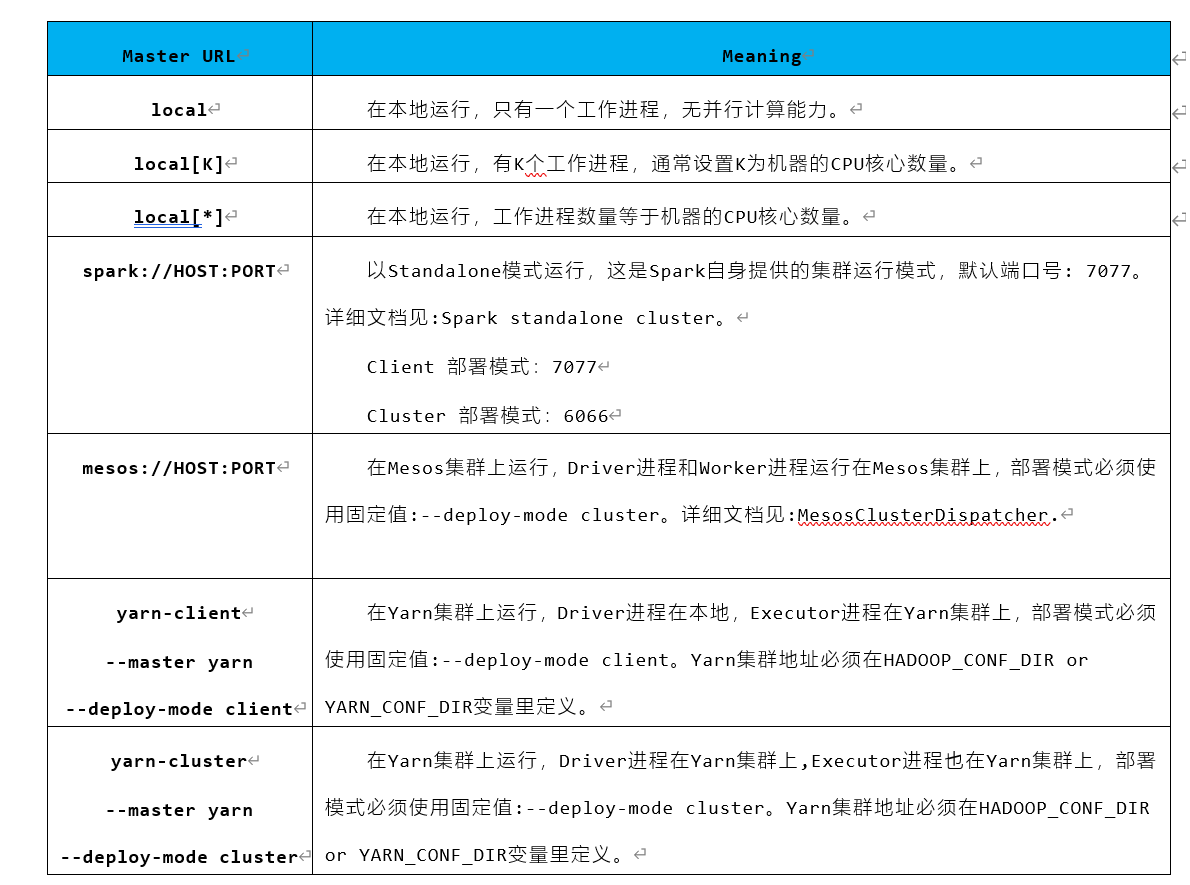
Spark支持多种集群管理器(Cluster Manager),取决于传递给SparkContext的MASTER环境变量的值:local、spark、yarn,区别如下:
spark-shell
之前我们使用提交任务都是使用spark-shell提交,spark-shell是Spark自带的交互式Shell程序,方便用户进行交互式编程,用户可以在该命令行下可以用scala编写spark程序,适合学习测试时使用!
spark-shell可以携带参数
- spark-shell --master local[N] 数字N表示在本地模拟N个线程来运行当前任务
- spark-shell --master local[*] *表示使用当前机器上所有可用的资源
- 默认不携带参数就是--master local[*]
- spark-shell --master spark://node01:7077,node02:7077 表示运行在集群上
spark-submit
spark-shell交互式编程确实很方便我们进行学习测试,但是在实际中我们一般是使用IDEA开发Spark应用程序打成jar包交给Spark集群/YARN去执行,所以我们还得学习一个spark-submit命令用来帮我们提交jar包给spark集群/YARN
spark-submit命令是我们开发时常用的!
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \
--master local[2] \
--class org.apache.spark.examples.SparkPi \
${SPARK_HOME}/examples/jars/spark-examples_2.11-3.0.1.jar \
10
或提交任务到Standalone集群
--master spark://node1:7077 \
或提交任务到Standalone-HA集群
--master spark://node1:7077,node2:7077 \或使用SparkOnYarn的Client模式提交到Yarn集群:
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \
--master yarn \
--deploy-mode client \
--driver-memory 512m \
--executor-memory 512m \
--num-executors 1 \
--total-executor-cores 2 \
--class org.apache.spark.examples.SparkPi \
${SPARK_HOME}/examples/jars/spark-examples_2.12-3.0.1.jar \
10
或使用SparkOnYarn的Cluster模式提交到Yarn集群
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \
--master yarn \
--deploy-mode cluster \
--driver-memory 512m \
--executor-memory 512m \
--num-executors 1 \
--total-executor-cores 2 \
--class org.apache.spark.examples.SparkPi \
${SPARK_HOME}/examples/jars/spark-examples_2.12-3.0.1.jar \
10应用提交语法
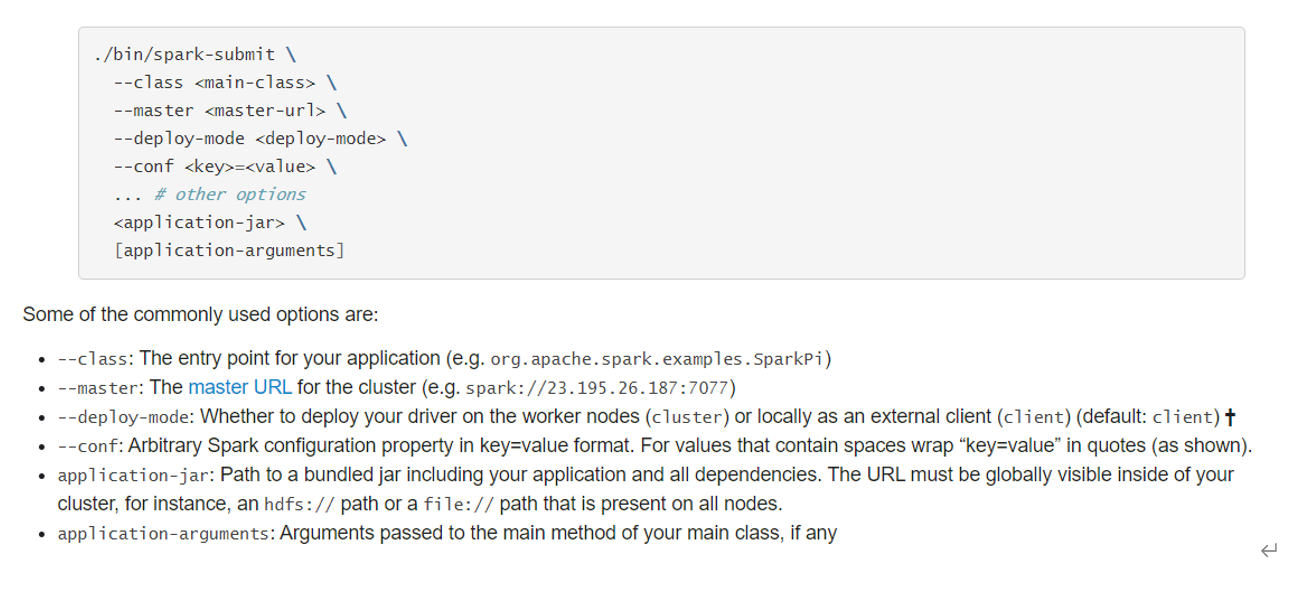
使用【spark-submit】提交应用语法如下:
Usage: spark-submit [options] <app jar | python file> [app arguments]如果使用Java或Scala语言编程程序,需要将应用编译后达成Jar包形式,提交运行。
基本参数设置
提交运行Spark Application时,有些基本参数需要传递值,如下所示:

动态加载Spark Applicaiton运行时的参数,通过--conf进行指定,如下使用方式:

Driver Program 参数配置
每个Spark Application运行时都有一个Driver Program,属于一个JVM Process进程,可以设置内存Memory和CPU Core核数。

Executor 参数配置
每个Spark Application运行时,需要启动Executor运行任务Task,需要指定Executor个数及每个Executor资源信息(内存Memory和CPU Core核数)。

官方案例
# Run application locally on 8 cores
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[8] \
/path/to/examples.jar \
100
# Run on a Spark standalone cluster in client deploy mode
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://207.184.161.138:7077 \
--executor-memory 20G \
--total-executor-cores 100 \
/path/to/examples.jar \
1000
# Run on a Spark standalone cluster in cluster deploy mode with supervise
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://207.184.161.138:7077 \
--deploy-mode cluster \
--supervise \
--executor-memory 20G \
--total-executor-cores 100 \
/path/to/examples.jar \
1000
# Run on a YARN clusterexport HADOOP_CONF_DIR=XXX
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \ # can be client for client mode
--executor-memory 20G \
--num-executors 50 \
/path/to/examples.jar \
1000
# Run a Python application on a Spark standalone cluster
./bin/spark-submit \
--master spark://207.184.161.138:7077 \
examples/src/main/python/pi.py \
1000
# Run on a Mesos cluster in cluster deploy mode with supervise
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master mesos://207.184.161.138:7077 \
--deploy-mode cluster \
--supervise \
--executor-memory 20G \
--total-executor-cores 100 \
http://path/to/examples.jar \
1000
# Run on a Kubernetes cluster in cluster deploy mode
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master k8s://xx.yy.zz.ww:443 \
--deploy-mode cluster \
--executor-memory 20G \
--num-executors 50 \
http://path/to/examples.jar \
1000K8S & Mesos 模式
Mesos 是Apache 下的开源分布式资源管理框架,它被称为是分布式系统的内核,在Twitter 得到广泛使用,管理着Twitter 超过 30,0000 台服务器上的应用部署,但是在国内,依然使用着传统的Hadoop大数据框架,所以国内使用Mesos 框架的并不多,但是原理其实都差不多,这里我们就不做过多讲解了。
容器化部署是目前业界很流行的一项技术,基于Docker 镜像运行能够让用户更加方便地对应用进行管理和运维。容器管理工具中最为流行的就是Kubernetes(k8s),而 Spark 也在最近的版本中支持了k8s 部署模式。
参考资料
https://spark.apache.org/docs/latest/running-on-kubernetes.htmlWindows 模式
在同学们自己学习时,每次都需要启动虚拟机,启动集群,这是一个比较繁琐的过程, 并且会占大量的系统资源,导致系统执行变慢,不仅仅影响学习效果,也影响学习进度, Spark 非常暖心地提供了可以在windows 系统下启动本地集群的方式,这样,在不使用虚拟机的情况下,也能学习 Spark 的基本使用
解压缩文件
将文件 spark-3.0.0-bin-hadoop3.2.tgz解压缩到无中文无空格的路径中
启动本地环境
执行解压缩文件路径下 bin 目录中的 spark-shell.cmd 文件,启动 Spark 本地环境,以管理员身份运行
命令行提交应用
在 DOS 命令行窗口中执行提交指令
spark-submit --class org.apache.spark.examples.SparkPi --master local[2] ../examples/jars/spark-examples_2.12-3.0.0.jar 10
部署模式对比
| 模式 | Spark 安装机器数 | 需启动的进程 | 所属者 | 应用场景 |
|---|---|---|---|---|
| Local | 1 | 无 | Spark | 测试 |
| Standalone | 3 | Master 及 Worker | Spark | 单独部署 |
| Yarn | 1 | Yarn 及 HDFS | Hadoop | 混合部署 |
端口号
- Spark 查看当前 Spark-shell 运行任务情况端口号:4040(计算)application的webUI的端口号
- Spark Master 内部通信服务端口号:7077,spark基于standalone的提交任务的端口号
- Standalone 模式下,Spark Master Web 端口号:8080(资源)
- Spark 历史服务器端口号:18080
- Hadoop YARN 任务运行情况查看端口号:8088
思维导图

运行在Yarn集群上

运行在Mesos集群上

在Cloud

贡献者
 codingLab
codingLab版权所有
版权归属:
许可证: