11、Spark的Yarn-cluster模式和Yarn-client模式
先来回顾一下YARN的相关组件
首先简要说明一下hadoop yarn是如何从hadoop种分离出来的:
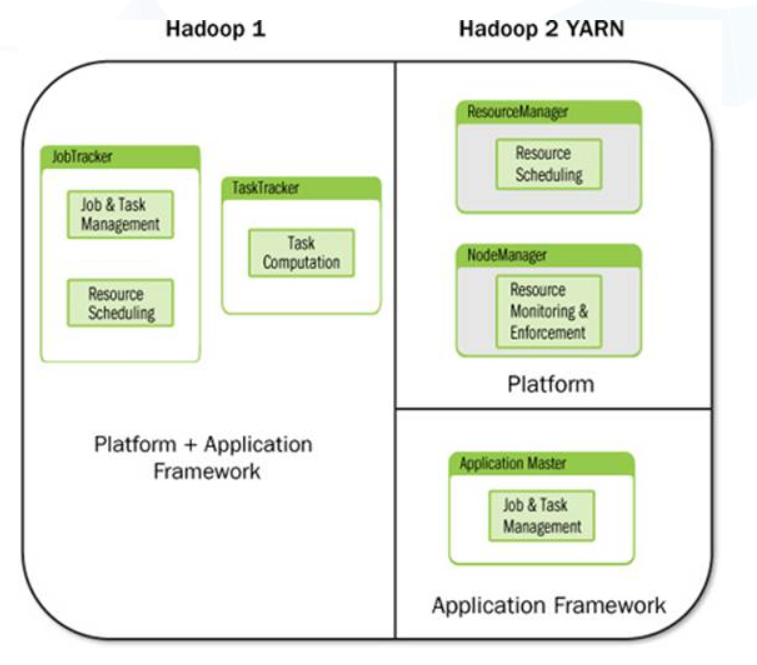
Hadoop 从 v2 开始,将资源调度与监控、任务作业的管理单独从 Hadoop 中抽取出来,即原来的 JobTracker 和TaskTracker 的功能被抽取出来。 YARN 全称为Yet Another Resource Negotiator,在于要提供一个共享的任务调度计算平台。其中将资源和作业分离开来,形成资源管理平台和应用框架,资源管理平台主要负责资源的调度和监控;应用框架主要用于负责任务或作业的管理。
从上图可以看出,YARN 不仅仅是简单地将JobTracker和TaskTracker的功能从hadoop 框架中分离出来,还将资源和任务的概念分离开来,将具体的任务和应用框架分离开来。只需要application的框架,如 mapreduce 或 spark 任务遵循 yarn的资源管理规范和任务的调度规范,任务就可以被提交到yarn上来执行。降低了模块之间的耦合性。
再来一个更加直观的来自官方文档的图来简单地说明一下 YARN的组件:
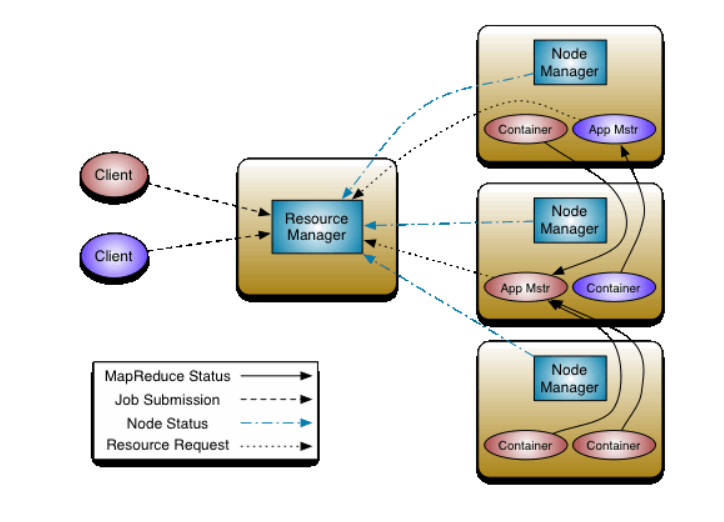
从上图可以看出,ResourceManager 和 NodeManager 组成了数据计算框架。其中ResourceManager 负责管理计算过程所需的所有的资源;NodeManager 是计算框架在每一个节点上的agent,负责container以及监控资源,并将资源使用情况汇报给 ResouceManager或 Scheduler;每个应用程序ApplicationMaster实际上是一个特定于框架的库,其任务是协调来自ResourceManager的资源,并与NodeManager一起执行和监视任务。【翻译自官方文档】
ResourceManager 包括Scheduler 和 ApplicationManager 两大组件。
调度程序负责根据容量,队列等约束将资源分配给各种正在运行的应用程序。Scheduler 是纯调度程序,因为它不执行应用程序状态的监视或跟踪。 此外,由于应用程序故障或硬件故障,它无法保证重新启动失败的任务。调度程序根据应用程序的资源需求执行其调度功能; 它是基于资源Container的抽象概念,它包含内存,CPU,磁盘,网络等元素。【翻译自官方文档】
综上所述,研究YARN,不得不研究ResourceManager 和 NodeManager的服务体系。其中,研究ResourceManager就必须要研究 Scheduler 和 ApplicationManager两大组件。
注意,Container 其实是一个基于资源的一个概念,并不是某种服务。
了解Yarn架构,先要了解两个概念。 作业。也可称为应用程序,包含一个或多个任务。任务。在运行MapReduce时,一个任务可以是一个Mapper或一个Reducer。
相关组件说明
ResourceManager
ResourceManager由两个关键组件Scheduler和ApplicationsManager组成。
Scheduler
Scheduler在容量和队列限制范围内负责为运行的容器分配资源。Scheduler是一个纯调度器(pure scheduler),只负责调度,它不会监视或跟踪应用程序的状态,也不负责重启失败任务,这些全都交给ApplicationMaster完成。Scheduler根据各个应用程序的资源需求进行资源分配。
ApplicationsManager
ApplicationManager负责接收作业的提交,然后启动一个ApplicationMaster容器负责该应用。它也会在ApplicationMaster容器失败时,重新启动ApplicationMaster容器。
NodeManager
Hadoop 2集群中的每个DataNode都会运行一个NodeManager来执行Yarn的功能。每个节点上的NodeManager执行以下功能:NodeManager可以说是一个节点的代理,负责资源管理。
- 定时向ResourceManager汇报本节点资源使用情况和各个Container的运行状况
- 监督应用程序容器的生命周期
- (监控资源)监控、管理和提供容器消耗的有关资源(CPU/内存)的信息(监控资源使用情况)
- (监控容器)监控容器的资源使用情况,杀死失去控制的程序
- (启动/停止容器)接受并处理来自ApplicationMaster的Container启动/停止等各种请求。
ApplicationMaster
提交到Yarn上的每一个应用都有一个专用的ApplicationMaster(注意,ApplicationMaster需要和ApplicationManager区分)。ApplicationMaster运行在应用程序启动时的第一个容器内。ApplicationMaster会与ResourceManager协商获取容器来执行应用中的mappers和reducers,之后会将ResourceManager分配的容器资源呈现给运行在每个DataNode上的NodeManager。ApplicationMaster请求的资源是具体的。包括:
- 处理作业需要的文件块
- 为应用程序创建的以容器为单位的资源
- 容器大小(例如,1GB内存和一个虚拟核心)
- 资源在何处分配,这个依据从NameNode获取的块存储位置信息(如机器1的节点10上分配4个容器,机器2的节点20上分配8个容器)
- 资源请求的优先级
ApplicationMaster是一个特定的框架。例如,MapReduce程序是MRAppMaster,spark是SparkAppMaster。
Container
Container是对于资源的抽象, 它封装了某个节点上的多维度资源,如内存、CPU等。
YARN工作流程
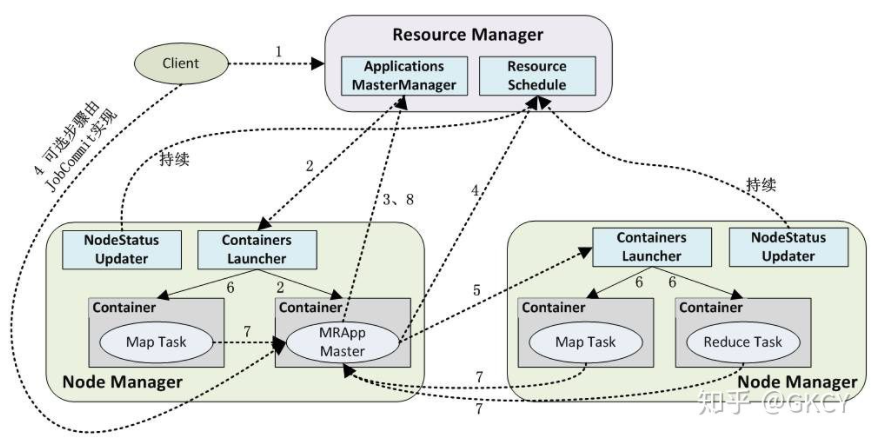
- 客户端向ResourceManager提交应用程序。
- ResourceManager的ApplicationManager组件指示NodeManager(运行在每一个工作节点的其中一个)为应用程序启动一个新的ApplicationMaster容器。
- ApplicationMaster首先向ResourceManager注册,这样用户可以直接通过NodeManager查看应用程序的运行状态。
- ApplicationMaster计算应用完成所需要的资源,然后向ResourceManager申请需要的资源(容器)。ApplicationMaster在应用程序的整个生命周期内与ResourceManager保持联系,确保其所需要资源的列表被ResourceManager严格遵守,并且发送一些必要的Kill请求杀死任务。
- 申请到资源后,ApplicationMaster指示NodeManager在对应的节点上创建容器。
- NodeManager创建容器,设置好运行环境,然后启动容器。
- 各个容器定时向ApplicationMaster发送任务的运行状态和进度,这样ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。
- 应用程序完成后,ApplicationMaster会通知ResourceManager该作业已经完成并注销关闭自己。
这里要注意几点。第一,NodeManager会将节点状态和健康状况发送到ResourceManager,ResourceManager拥有全局资源视图才能分配资源。第二,ResourceManager的Scheduler组件决定容器在哪个节点上运行。
Spark On Yarn的优势
每个Spark executor作为一个YARN容器(container)运行。Spark可以使得多个Tasks在同一个容器(container)里面运行。
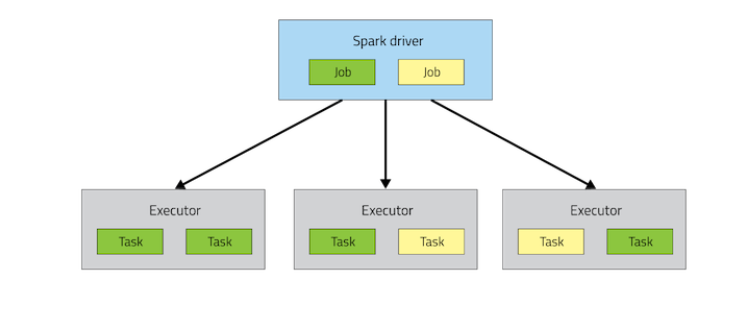
Spark支持资源动态共享,运行于Yarn的框架都共享一个集中配置好的资源池
可以很方便的利用Yarn的资源调度特性来做分类、隔离以及优先级控制负载,拥有更灵活的调度策略
Yarn可以自由地选择executor数量
Yarn是唯一支持Spark安全的集群管理器,使用Yarn,Spark可以运行于Kerberized Hadoop之上,在它们进程之间进行安全认证
我们知道Spark on yarn有两种模式:yarn-cluster和yarn-client。这两种模式作业虽然都是在yarn上面运行,但是其中的运行方式很不一样,今天就来谈谈Spark on YARN yarn-client模式作业从提交到运行的过程剖析
相关概念
Application: Appliction都是指用户编写的Spark应用程序,其中包括一个Driver功能的代码和分布在集群中多个节点上运行的Executor代码。
Driver: Spark中的Driver即运行上述Application的main函数并创建SparkContext,创建SparkContext的目的是为了准备Spark应用程序的运行环境,在Spark中有SparkContext负责与ClusterManager通信,进行资源申请、任务的分配和监控等,当Executor部分运行完毕后,Driver同时负责将SparkContext关闭,通常用SparkContext代表Driver
Executor: 某个Application运行在worker节点上的一个进程, 该进程负责运行某些Task, 并且负责将数据存到内存或磁盘上,每个Application都有各自独立的一批Executor, 在Spark on Yarn模式下,其进程名称为CoarseGrainedExecutor Backend。一个CoarseGrainedExecutor Backend有且仅有一个Executor对象, 负责将Task包装成taskRunner,并从线程池中抽取一个空闲线程运行Task, 这个每一个oarseGrainedExecutor Backend能并行运行Task的数量取决与分配给它的cpu个数
**Cluter Manager:**指的是在集群上获取资源的外部服务。目前有三种类型
- Standalon : spark原生的资源管理,由Master负责资源的分配
- Apache Mesos:与hadoop MR兼容性良好的一种资源调度框架
- Hadoop Yarn: 主要是指Yarn中的ResourceManager
Worker: 集群中任何可以运行Application代码的节点,在Standalone模式中指的是通过slave文件配置的Worker节点,在Spark on Yarn模式下就是NoteManager节点
Task: 被送到某个Executor上的工作单元,但hadoopMR中的MapTask和ReduceTask概念一样,是运行Application的基本单位,多个Task组成一个Stage,而Task的调度和管理等是由TaskScheduler负责
Job: 包含多个Task组成的并行计算,往往由Spark Action触发生成, 一个Application中往往会产生多个Job
Stage: 每个Job会被拆分成多组Task, 作为一个TaskSet, 其名称为Stage,Stage的划分和调度是有DAGScheduler来负责的,Stage有非最终的Stage(Shuffle Map Stage)和最终的Stage(Result Stage)两种,Stage的边界就是发生shuffle的地方
DAGScheduler: 根据Job构建基于Stage的DAG(Directed Acyclic Graph有向无环图),并提交Stage给TASkScheduler。 其划分Stage的依据是RDD之间的依赖的关系找出开销最小的调度方法,如下图
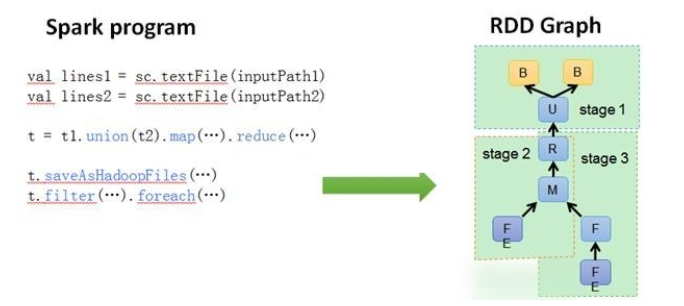
- TASKSedulter: 将TaskSET提交给worker运行,每个Executor运行什么Task就是在此处分配的. TaskScheduler维护所有TaskSet,当Executor向Driver发生心跳时,TaskScheduler会根据资源剩余情况分配相应的Task。另外TaskScheduler还维护着所有Task的运行标签,重试失败的Task。下图展示了TaskScheduler的作用
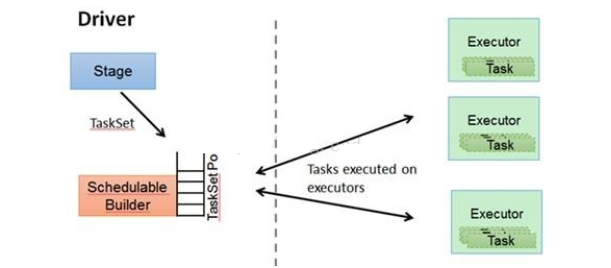
在不同运行模式中任务调度器具体为:
- Spark on Standalone模式为TaskScheduler
- YARN-Client模式为YarnClientClusterScheduler
- YARN-Cluster模式为YarnClusterScheduler
将这些术语串起来的运行层次图如下:
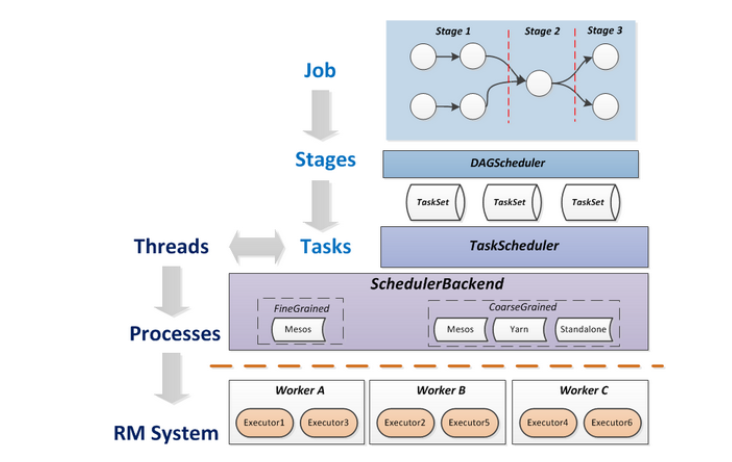
Job=多个stage,Stage=多个同种task, Task分为ShuffleMapTask和ResultTask,Dependency分为ShuffleDependency和NarrowDependency
Spark运行模式:
- Spark的运行模式多种多样,灵活多变,部署在单机上时,既可以用本地模式运行,也可以用伪分布模式运行,而当以分布式集群的方式部署时,也有众多的运行模式可供选择,这取决于集群的实际情况,底层的资源调度即可以依赖外部资源调度框架,也可以使用Spark内建的Standalone模式。
- 对于外部资源调度框架的支持,目前的实现包括相对稳定的Mesos模式,以及hadoop YARN模式
- **本地模式:**常用于本地开发测试,本地还分别 local 和 local cluster
Yarn 的 Application Master 概念:在 Yarn 中,每个 application 都有一个 Application 都有一个 Application Master 进程,它是 Application 启动的第一个容器,负责从 ResourceManager 中申请资源,分配资源,同时通知 NodeManager 来为 Application 启动 Container。也可以理解为一个作业的代理进程,负责一个作业的执行。
Spark On Yarn 有两种模式,一种是 Yarn-client 模式,一种是 Yarn-cluster 模式。一般情况下,Yarn-client 模式使用在调试模式下,Yarn-cluster 模式使用在生产环境中。
YARN-Client
在 Yarn-client 中,driver 运行在 client 上,通过 ApplicationMaster 向 RM 获取资源。本地 driver (因为client是运行在本地)负责与所有的 executor container 进行交互,并将最后的结果汇总。结束掉终端,相当于 kill 掉这个 Spark 应用。因为 driver 在客户端,所以可以通过 webUI 访问 driver 的状态,默认是 http://hadoop1:4040访问,而 Yarn 通过 http:// hadoop1:8088 访问。工作流程如下图:
YARN-client的工作流程步骤为:
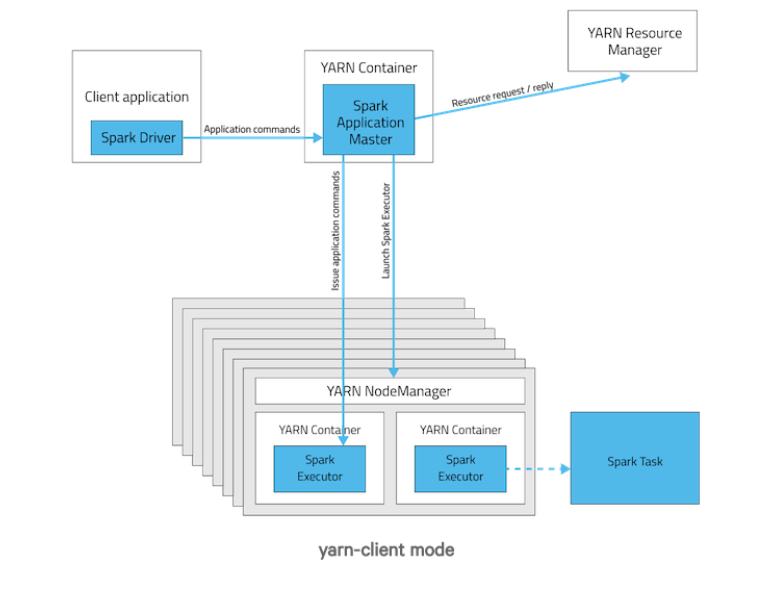
我们可以看到driver进程运行在yarn-client本地端。详细工作过程如下:
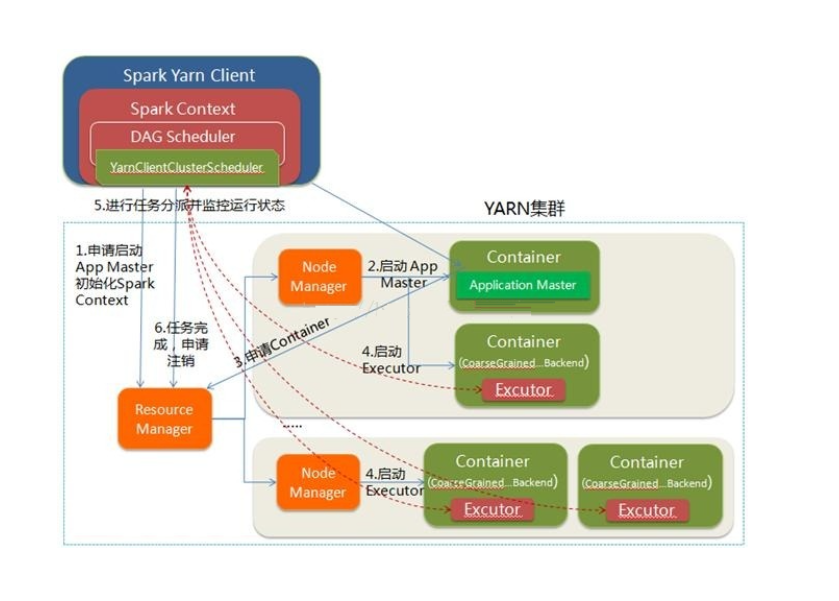
- Spark Yarn Client向YARN的ResourceManager申请启动Application Master。同时在SparkContext初始化中将创建DAGScheduler和TASKScheduler等,由于我们选择的是Yarn-Client模式,程序会选择YarnClientClusterScheduler和YarnClientSchedulerBackend
- ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,与YARN-Cluster区别的是在该ApplicationMaster不运行SparkContext,只与SparkContext进行联系进行资源的分派。
- Client中的SparkContext初始化完毕后,与ApplicationMaster建立通讯,向ResourceManager注册,根据任务信息向ResourceManager申请资源(Container)
- 一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,要求它在获得的Container中启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向Client中的SparkContext注册并申请Task
- client中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向Driver汇报运行的状态和进度,以让Client随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务
- 应用程序运行完成后,Client的SparkContext向ResourceManager申请注销并关闭自己
因为是与Client端通信,所以Client不能关闭。
客户端的Driver将应用提交给Yarn后,Yarn会先后启动ApplicationMaster和executor,另外ApplicationMaster和executor都 是装载在container里运行,container默认的内存是1G,ApplicationMaster分配的内存是driver- memory,executor分配的内存是executor-memory。同时,因为Driver在客户端,所以程序的运行结果可以在客户端显 示,Driver以进程名为SparkSubmit的形式存在。
Yarn-Cluster
在 Yarn-cluster 模式下,driver 运行在 Appliaction Master 上,Appliaction Master 进程同时负责驱动 Application 和从 Yarn 中申请资源,该进程运行在 Yarn container 内,所以启动 Application Master 的 client 可以立即关闭而不必持续到 Application 的生命周期。
在YARN-Cluster模式中,当用户向YARN中提交一个应用程序后,YARN将分两个阶段运行该应用程序:
- 第一个阶段是把Spark的Driver作为一个ApplicationMaster在YARN集群中先启动;
- 第二个阶段是由ApplicationMaster创建应用程序,然后为它向ResourceManager申请资源,并启动Executor来运行Task,同时监控它的整个运行过程,直到运行完成
应用的运行结果不能在客户端显示(可以在history server中查看),所以最好将结果保存在HDFS而非stdout输出,客户端的终端显示的是作为YARN的job的简单运行状况,下图是yarn-cluster模式
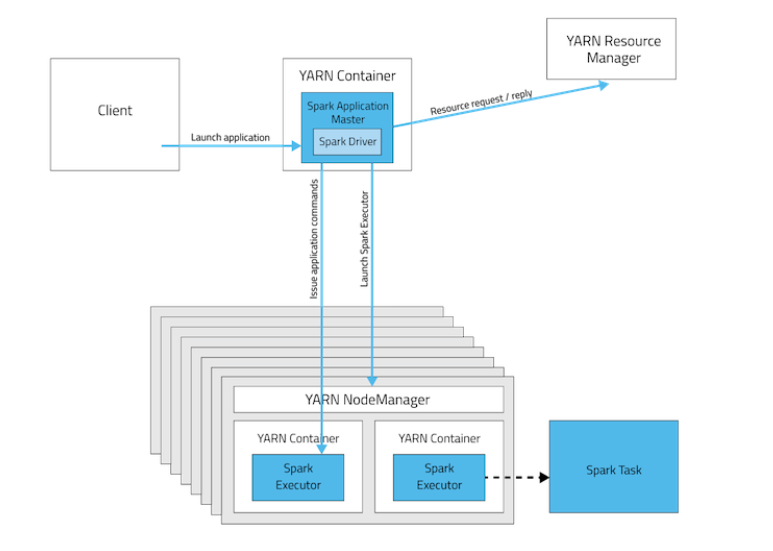
可以看到,此时的driver运行在applicationMaster上面:
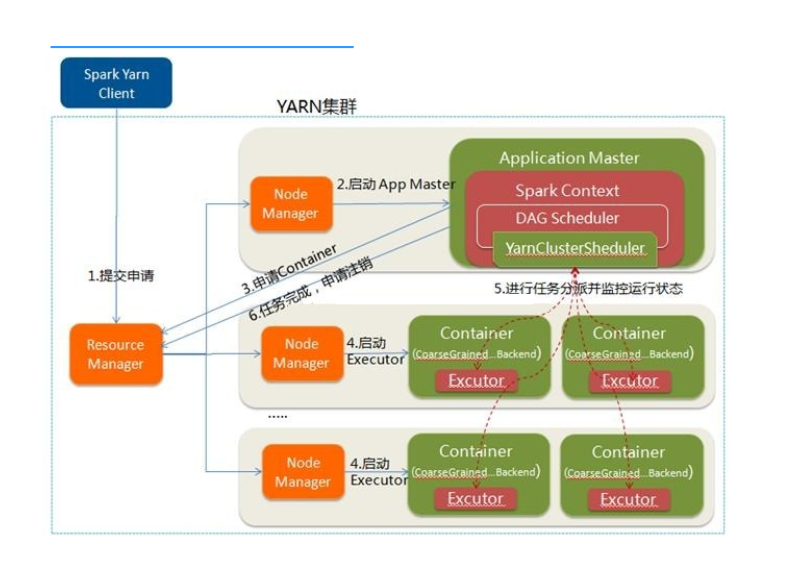
执行过程:
- Spark Yarn Client向YARN中提交应用程序,包括ApplicationMaster程序、启动ApplicationMaster的命令、需要在Executor中运行的程序等
- ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,其中ApplicationMaster进行SparkContext等的初始化
- ApplicationMaster向ResourceManager注册,这样用户可以直接通过ResourceManage查看应用程序的运行状态,然后它将采用轮询的方式通过RPC协议为各个任务申请资源,并监控它们的运行状态直到运行结束
- 一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,要求它在获得的Container中启动CoarseGrainedExecutorBackend,而Executor对象的创建及维护是由CoarseGrainedExecutorBackend负责的,CoarseGrainedExecutorBackend启动后会向ApplicationMaster中的SparkContext注册并申请Task。这一点和Standalone模式一样,只不过SparkContext在Spark Application中初始化时,使用CoarseGrainedSchedulerBackend配合YarnClusterScheduler进行任务的调度,其中YarnClusterScheduler只是对TaskSchedulerImpl的一个简单包装,增加了对Executor的等待逻辑等
- ApplicationMaster中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向ApplicationMaster汇报运行的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务
- 应用程序运行完成后,ApplicationMaster向ResourceManager申请注销并关闭自己
YARN-Cluster和YARN-Client的区别
- 理解YARN-Client和YARN-Cluster深层次的区别之前先清楚一个概念:Application Master。在YARN中,每个Application实例都有一个ApplicationMaster进程,它是Application启动的第一个容器。它负责和ResourceManager打交道并请求资源,获取资源之后告诉NodeManager为其启动Container。从深层次的含义讲YARN-Cluster和YARN-Client模式的区别其实就是ApplicationMaster进程的区别。
- YARN-Cluster模式下,Driver运行在AM(Application Master)中,它负责向YARN申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉Client,作业会继续在YARN上运行,因而YARN-Cluster模式不适合运行交互类型的作业
- YARN-Client模式下,Application Master仅仅向YARN请求Executor,Client会和请求的Container通信来调度他们工作,也就是说Client不能离开
- YarnCluster的Driver是在集群的某一台NM上,但是Yarn-Client就是在RM的机器上;
- 而Driver会和Executors进行通信,所以Yarn_cluster在提交App之后可以关闭Client,而Yarn-Client不可以;
- Yarn-Cluster适合生产环境,Yarn-Client适合交互和调试。
Yarn Client模式
运行位置:
├── 客户端机器(你的电脑/提交节点)
│ └── Driver进程 (包含SparkContext)
│ ├── 创建DAG
│ ├── 划分Stage
│ └── 调度Task
└── YARN集群
├── ApplicationMaster(轻量级)
│ └── 只负责向RM申请Executor资源
└── Executor进程
└── 执行Task
特点:
- Driver在客户端运行,SparkContext在客户端
- ApplicationMaster是一个轻量进程,只负责资源申请
- 客户端必须保持运行,直到应用结束
- 任务输出直接显示在客户端控制台
- 适合交互式开发调试(如spark-shell)yarn cluster模式
运行位置:
└── YARN集群
├── ApplicationMaster(包含Driver的所有功能)
│ └── 实际上就是Driver进程
│ ├── 包含SparkContext
│ ├── 创建DAG
│ ├── 划分Stage
│ └── 调度Task
└── Executor进程
└── 执行Task
特点:
- Driver和ApplicationMaster合二为一,运行在集群的Container中
- SparkContext运行在集群内的Driver/AM进程中
- 客户端提交后即可断开连接
- 任务输出需要通过日志查看
- 适合生产环境长时间运行的任务对比
| 方面 | YARN Client 模式 | YARN Cluster 模式 |
|---|---|---|
| Driver位置 | 客户端机器 | YARN集群的Container中 |
| ApplicationMaster | 轻量级资源代理 | 就是Driver本身 |
| SparkContext位置 | 客户端Driver中 | 集群内Driver/AM中 |
| 客户端依赖 | 必须保持连接 | 提交后即可断开 |
| 适用场景 | 交互式、调试 | 生产环境、批处理 |
| 日志查看 | 直接输出到控制台 | 通过YARN日志聚合查看 |
下表是Spark Standalone与Spark On Yarn模式下的比较

贡献者
 codingLab
codingLab版权所有
版权归属:
许可证: