3、实时数仓项目总结
Flink实时数据仓库项目总结
第一章总结
普通的实时计算和实时数仓的比较
这个题从时效性和复用性进行回答:
普通实时计算:时效性好,因为不需要io中间的计算结果,也正是没有保留中间结果,所以计算的复用性很差。
实时数仓:时效性可能不是很好,但是中间的计算结果得到保留,数据的复用性很好。
说说你对实时数仓的理解或者看法
抓住分层这个概念,从分层引出,分两个部分:
- 数据分层
- 计算分层
介绍以下数仓分层
把离线数仓和实时数仓分开来说:
实时数仓
实时数仓中,我们一般将数据分为五层:
ODS:数据原始层,存放行为数据(日志)和业务数据,那么在实时数仓中,通常将ods层的数据存储kafka的主题当中。
DWD:我们一般将业务数据的事实表数据存放在DWD层的kafka中,而将业务数据中的维度表数据存放在DIM层,通常存储在Hbase数据库中。
再dwd层对日志数据进行分流操作,按照启动页面,曝光页面和普通页面将数据发送到kafka的不同主题中。
问题:为什么没有把维度表数据存储在kafka的主题当中呢?
两个原因
- kafka中数据存放时间有限制,一般我们的维度表数据需要长期进行保存的。
- 根据id取Kafka中查询数据很困难,因为我们再后面制作宽表的时候,需要根据id去查询维度表补充宽表信息,kafka不适合根据id去查询数据。
DIM:DIM和DWD层其实是一层的,只不过存放的数据不一样,并且数据存放的位置也不一样。
DWM:DWM算是DWD层数据到DWS层数据的中间过渡数据,这一部分数据依然算是明细数据,将DWD和DIM层数据进行轻度的加工,形成一个宽表,但是本质上还是明细数据。
DWS:按照主题将事实表数据进行聚合操作,形成一个以主题为单位的宽表,为ods层的数据查询做准备。
ADS:这一层可以认为是我们的需求,直接根据需求取查询数据即可。
离线数仓
ODS(Operation Data Store):原始数据层,存放原始数据,直接加载原始日志数据,数据保持原貌不做处理,这部分数据一般存储在文件系统的HDFS中。
DWD(data warehouse detail):对ODS层数据进行清洗(去除空值,脏数据,超过极限范围的数据)、脱敏等。保存业务事实明细,一行信息代表一次业务行为,例如一次下单。
DWS(data warehouse service):以DWD为基础,按天进行轻度汇总。一行信息代表一个主题对象一天的汇总行为,例如一个用户一天下单次数。
DWT(data warehouse Topic):以DWS为基础,对数据进行累积汇总。一行信息代表一个主题对象的累积行为,例如一个用户从注册那天开始至今一共下了多少次单,这里更多存储的是历史数据。
ADS(Application Data Store):为各种统计报表提供数据。
DIM:维度层,保存维度数据,主要是对业务事实的描述信息,例如何人,何时,何地等。
离线数仓分层模型:
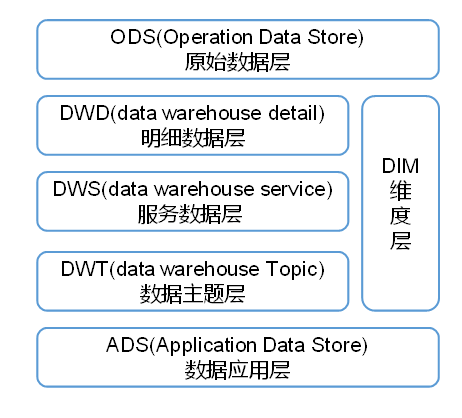
为什么实时数仓中没有DWT层?
因为实时数仓是来一条数据处理一条数据,不需要保存历史数据。
数据仓库为什么要分层?
- 复杂的问题简单化
将复杂的任务分解成多层来完成,每一层只处理简单的任务,方便定位问题。
- 减少重复开发
规范数据分层,通过的中间层数据,能够减少极大的重复计算,增加一次计算结果的复用性。
- 隔离原始数据
不论是数据的异常还是数据的敏感性,使真实数据与统计数据解耦开。
离线计算和实时计算的比较
离线计算
数据输入确定,计算数据量较大,时间长,统计的指标较多,从技术角度来说,属于批处理计算。
实时计算
输入数据不确定的,计算数据量相对小,计算时间短,更加注重用户的体验,以及用户的交互性,从技术角度来说,属于流处理。
即席查询
强调查询的临时性,需求的临时性。
presto:当场计算,基于内存速度快。
kylin:预计算,提前计算好。做多维度分析(hive with cube),数据有多种维度,那么kylin会把所有的维度组合全部计算好。需要的时候直接拿去即可。
实时架构和离线架构
离线架构
离线架构图
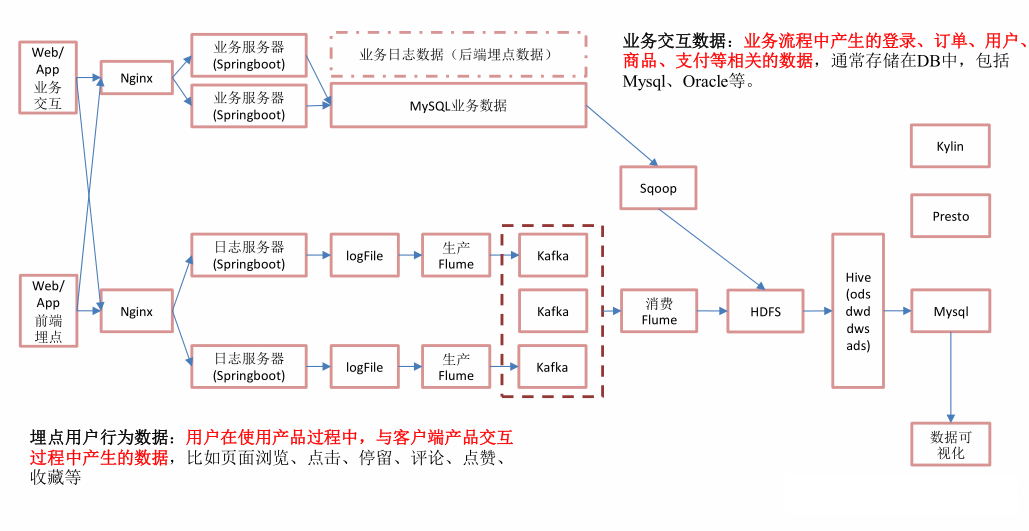
日志:使用flume+kafka+flume--->hdfs
业务数据:sqoop--->hdfs
优点:耦合性低,解耦,稳定性高。
缺点:时效性差。
说明:考虑到需求的数据量很大,所以优先的考虑系统的稳定性,耦合性方面原因,考虑未来的发展,数据零肯定变大,所以选定离线架构。
实时架构
实时架构图
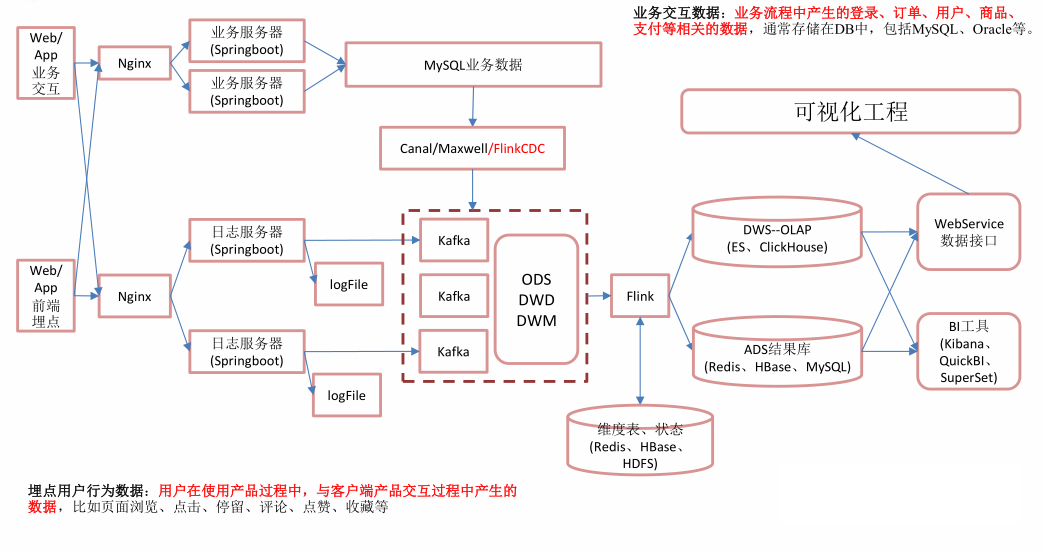
日志:日志服务器--->kafka
业务数据:mysql+Flink CDC--->kafka
优点:时效性高。
缺点:耦合高,稳定性低。
说明:kafka是高可用集群,很不容易挂掉,挂少数机器没有问题。目前数据量小,所有机器在一个机房,数据传输没有问题,挂掉可能性小。
实时架构和离线架构对比
对于日志数据
再实际工作中,公司通常采用一套日志数据采集系统,那么为什么会采用flume+kafka+flume三种组合的方式呢,可以使用flume直接将数据写入外部系统啊?
再采集日志时候,通常都使用flume采集系统,这里添加一个中间层kafka目的就是为了让两套系统公用一套采集系统,flume将数据采集后传输到kafka中,相当于kafka对外提供一个数据结果,如果离线系统需要数据,可以使用flume从kafka中采集,如果实时系统需要数据,可以直接从kafak中读取数据。
况且kafka的延迟性非常的低,所以可以满足实时系统对延时的需求。
业务数据
对于实时系统,因为需要保证低延迟,所以不能采用sqoop进行采集,因为sqoop再底层本质上是一个map任务,延迟很高,所以不适合实时系统,所以再本项目中采用的是Flink cdc组件。
对于离线系统就好说了,因为是离线分析,对时延没有要求,就可以使用sqoop将数据导入hdfs中。
讲一下CDC和Flink CDC
CDC的种类:
- 基于查询的CDC
- 基于Binlog的CDC
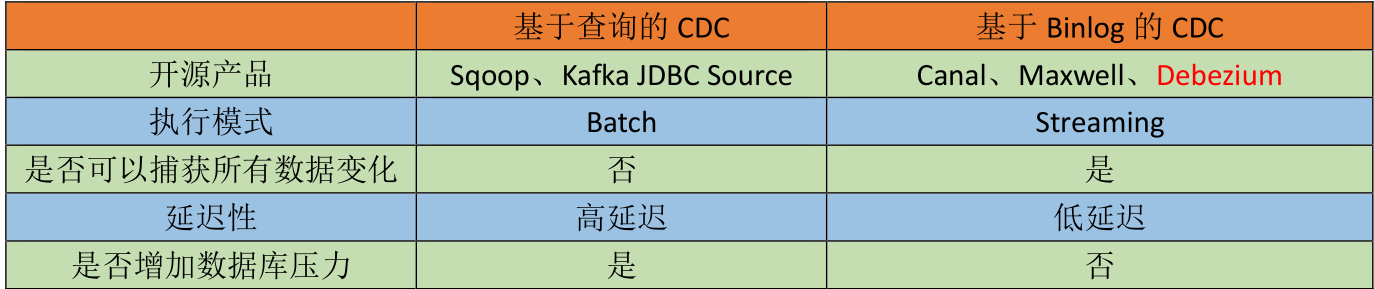
基于查询的Sqoop,我们是通过where查询语句实现不同数据的导入,比如说全量,增量,新增和变化数据的导入。
而基于BinLgog cdc是不需要读取数据,他读取的是mysql的操作日志,典型的产品如上图所示。
是否捕获所有变化
基于sqoop导入数据的时候,是每一天某个时间进行集中的数据导入,我们可以使用sql语句导入全量,增量或者是新曾和变化的数据,所以总的来说是可以捕捉到所有数据的变化的,但是有一个不能捕捉到,也就是数据的中间变化过程,这个是无论如何页无法捕捉到的。
而基于Binlog方式,是基于流的模式,每一次发生变化,都可以监控到数据的变化,并且可以监控到中间结果的变化过程,因为监控的是日志,所以只要日志发生更新,就能检测到变化的数据。
延迟性
基于查询的方式,可能会丢失数据,查询的是快照,最后的结果,也就是导入的是最终的数据,中间的过程数据是无法导入的。一条数据发生多次变化,只能拿到最后一次的数据。也就是只能检测到最终结果,保证结果一致性。
Binlog可以捕获所有数据,每变化一次,就加载一次,延迟性很低。
是否产生压力
是否增加数据库压力,基于查询使用的是select语句,所以是一次查询,会增加数据库的压力。
但是基于Binliog,读取的是一个磁盘文件,只是一次io操作,不会对服务器产生太大压力。
Flink 社区开发了 flink-cdc-connectors 组件,这是一个可以直接从 MySQL、PostgreSQL等数据库直接读取全量数据和增量和变更数据的 source 组件。
通常我们导入数据,有全量数据,新增数据,变化数据,这些Flink cdc都是可以做到的。
讲一下Flink cdc、Maxwell和Canal
Maxwell与Canal工具对比
- Maxwell 没有 Canal 那种 server+client 模式,只有一个 server 把数据发送到消息队列或 redis。
- Maxwell 有一个亮点功能,就是 Canal 只能抓取最新数据,对已存在的历史数据没有办法处理。而 Maxwell 有一个 bootstrap 功能,可以直接引导出完整的历史数据用于初始化,非常好用。
- Maxwell 不能直接支持 HA,但是它支持断点还原,即错误解决后重启继续上次点儿读取数据。
- Maxwell 只支持 json 格式,而 Canal 如果用 Server+client 模式的话,可以自定义格式。
- Maxwell 比 Canal 更加轻量级。
为什么采用Flink CDC
- 对于插入,删除和更新数据而言,他们三者返回的数据格式是有很大的区别的,相比较而言,Flink cdc返回的结果更加好处理。
- flink cdc可以做初始化,maxwell也可以做,但是canal不可以做,做初始化就是读取全量的数据。
- 断点续传:三者都可以做,flink cdc是checkpoint保存,maxwell是保存在mysql数据库,而canal是保存在本地磁盘。
- 数据封装格式,flink cdc和canal可以自定义,maxwell使用的是json格式。
- 高可用:flink cdc支持,canal支持,maxwell支持。
综上几点说明,flink cdc更适合我们。
第二章总结
在分类日志数据的时候,为什么采用测输出流,有没有其他的办法?
如果是在spark Streaming中,我们可以使用Filter进行过滤操作,但是在Flink中,我们有测输出流,所以使用测输出流代替了Filter过滤操作。
当然,再Flink中我们也可以使用filter()进行实现。
为什么把维度数据存储在Hbase?
- 在这里为什么没有选择Rides,因为维度数据数据量很大,特别是user维度,数据很大,所以选择使用HBase.也可以用户维度使用Hbase存储,其他的使用Rides,但是这样就复杂了。
- 为什么没有放在Mysql数据库,并发压力大,生产环境中,mysql是和后台打交道,用户的请求都来自mysql,mysql是相应用户的请求,如果我们这个时候去访问mysql,访问压力很大。
考虑到以上两点,我们选择使用Hbase数据库。
如何实现动态分流的功能?
什么是动态分流,Flink cdc将监控到的数据全部写入kafak中的一个topic中,但是很明显,所有的表中存在维度表和事实表,所以我们需要动态的将这些表分流到dwd层和dim层。
在实时计算中一般把维度数据写入存储容器,一般是方便通过主键查询的数据库比如HBase,Redis,MySQL 等。一般把事实数据写入流中,进行进一步处理,最终形成宽表。
这样的配置不适合写在配置文件中,因为这样的话,业务端随着需求变化每增加一张表,就要修改配置重启计算程序。所以这里需要一种动态配置方案,把这种配置长期保存起来,一旦配置有变化,实时计算可以自动感知。
这里有两种实现方案:
- 一种是用 Zookeeper 存储,通过 Watch 感知数据变化;
- 另一种是用 mysql 数据库存储,周期性的同步;
- 另一种是用 mysql 数据库存储,使用广播流。
这里选择第三种方案,主要是 MySQL 对于配置数据初始化和维护管理,使用 FlinkCDC读取配置信息表,将配置流作为广播流与主流进行连接。
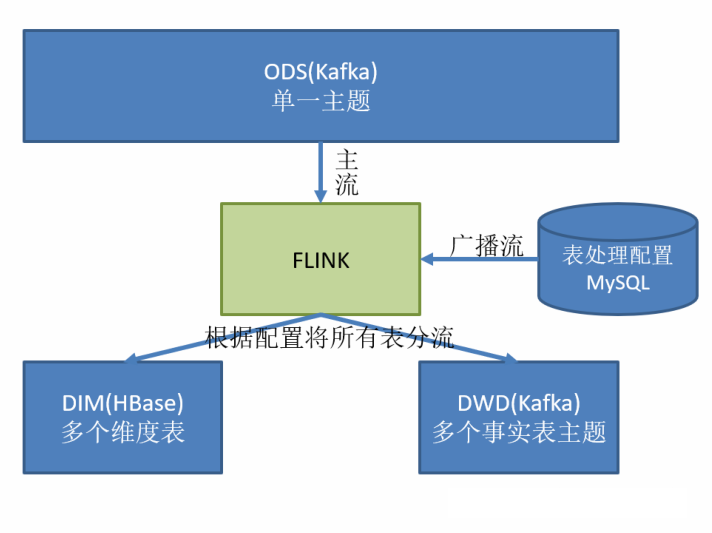
配置表如何确定
配置表的确定,需要根据我们的业务具体确定,在本项目中,比如肯定需要sourceTable字段,就是我们的源表。
第二个还需要我们监控对数据库的操作类型,比如删除,插入或者更新字段,所以就需要operator_type字段。
既然我们需要对数据进行分流,那么肯定需要直到这张表是维度表还是事实表,所以需要sink_type字段。
我们原始的数据表中一般字段是很多的,但是我们区分为维度表和事实表之后,有些字段是重复的,并不需要保留全部的字段,所以我们还可以设置一个columns,表示需要保留的属性等信息。
这些是最关键的字段,可能还有其他的字段,这些都是根据我们的具体需求进行添加。
配置流为什么使用map状态
再上面我们分析出配置表的字段之后,我们需要分析以下,再配置表中的主键是什么,配置表中,可以监控一张表中的多种操作,所以我们可以确定,表明+操作类型是主键。
而这里使用map状态,key存储的是主键,而calue存储的是配置表的实体bean对象,这样就可以根据主键唯一确定一条配置流信息,那么在配置流中,可以根据配置流中的表信息,在hbase中创建维度表,然后再将配置流广播出去。
再普通流中,首先获取配置流中的状态信息,然后根据sink_table字段将数据输出到hbase中或者kafka中进行分流操作。
写入Hbase中采用什么方法,为什么?
在这里写入Hbase中使用的是自定义sink的方法,因为写入Hbase中有很多的维度表,而我们使用自定义jdbc的方式,需要写入很多的表明,非常的不方便。
在这里我们将写入Hbase中的表明声明为字段存储再配置表中,使用sink方式的话,就可以直接在json字符串中解析出表名,然后直接写入Hbase中,很方便。
第三章
DWM层访客UV如何计算
- 我们根据日志中的last_page_id判断,如果该字段是null,那么说明是今天第一次登录该页面,否则不空,也就是说不是第一次。这个字段代表上一跳的地址,为null说明没有上一跳。
- 由于访客可以在一天中多次进入应用,所以我们要在一天的范围内进行去重,因为用户每一次访问页面,都会产生一个访问日志。
- 状态中保存的是时间,我们判断的是某一天,所以将时间戳保存为状态。
- 因为状态主要用来保存用户今天是否访问过,所以过了今天之后就没用了,要定期清除状态,所以给状态设置过期时间24h.
DWM层跳出明细层如何计算
首先说明思路:
判断用户跳出某一个页面,有两个步骤:
- 该页面是用户近期访问的第一个页面,这个可以通过该页面是否有上一个页面(last_page_id)来判断,如果这个表示为空,就说明这是这个访客这次访问的第一个页面。
- 首次访问之后很长一段时间(自己设定),用户没继续再有其他页面的访问。如果有会话id的话,我们可以使用会话id方便的解决。
计算跳出明细,针对同一个用户才有意义,所以在将模式运用到数据流上的时候,我们需要根据设备id进行分组。
思路一
使用会话id,根据会话id来判断,多次进入页面,有多个会话id。但是在现有条件下,我们没有会话id。引出思路二:
思路二
在Flink,会话窗口的应用场景是,当我们需要根据会话id取计算窗口的某一些指标的时候,但是没有会话id情况下,我们可以使用会话窗口代替,如果两个事件中间的时间间隔在一个很小的范围内,我们就认为是一次会话。
但是,这种情况也存在一些问题,就是数据丢失问题,说一说如何会发生数据的丢失,然后引出cep解决方案,复杂事件处理:
思路三
- 该页面是用户近期访问的第一个页面,这个可以通过该页面是否有上一个页面(last_page_id)来判断,如果这个表示为空,就说明这是这个访客这次访问的第一个页面。
- 首次访问之后很长一段时间(自己设定),用户没继续再有其他页面的访问。如果有会话id的话,我们可以使用会话id方便的解决。如果使用cep,那么就是下一个条件也为null即可。
flink cep可以解决从复杂的事件流中匹配出符合条件的事件,通过上面两个步骤,很明显我们只需要定义两个简单条件即可。通过定义两个条件,可以匹配出我们需要的事件。
其实本质上,用户跳出行为是一个条件事件加一个超时事件的组合,既然要超时,所以数据肯定存在延迟,所以我们需要使用watermark机制。
如何写Flink cep代码
- 首先我们需要定义模式序列,模式序列可以是简单的,组合或者复杂的模式。
- 将定义好的模式序列应用到我们的事件流中。
- 提取匹配上的超时事件。
Flink 中一共有哪几种join操作
- 带窗口的join操作。
- 不带窗口的join操作。

DWM层订单宽表如何实现
先说明关联的思路或者解决方案:
订单宽表中最基础的就是订单表和订单明细表,这两个都是实时表数据,并且是1:n关系,所以首先把订单表和订单明细表进行join操作。
如果直接把订单表和维度表进行join操作是不行的,因为订单表中没有各个维度的id,是无法进行join的,因为在join操作的时候,实际上我们是拿着id去各个维度表中查询数据。
所以说总的思路就是:
- 首先join操作订单表和订单明细表。
- 然后在去join各个维度表。
然后说明join方案
这里我们使用双流join,使用connect非常的麻烦,并且connect每一次只能关联两个数据流,需要我们自己去维护状态。
这里选用 intervalJoin,因为相比较窗口 join,intervalJoin 使用更简单,而且避免了应用匹配的数据处于不同窗口的问题。intervalJoin 目前只有一个问题,就是还不支持 left join。
引出问题
在提出初步的解决方案后,肯定存在问题,引出问题:
我们的事实表数据一般是存储在kafka中,kafka在实际中数据的延迟是非常低的,但是我们在使用关联后的id去关联维度表的时候,需要先去hbase中查询到此id的维度信息,然后再做join操作,那么再和外部系统打交道或者说是查询数据,经常的性能瓶颈是外部系统查询数据的延迟非常的高,那么在本系统中也存在这个问题。
从测试情况来看,如果我们不做任何优化操作,那么去hbase中查询一条数据大概时间是13毫秒,所以1秒钟大概处理不到80条数据,显然效率很低。
如果单考虑并发度的话,仅仅提高我们并发度,但并行度查询效率不提高也是不行的,没有从根本上解决问题,所以我们的目标是提高但并行度下,查询速率。
引出两种优化的思路
使用Rides旁路缓存优化
旁路缓存模式是一种非常常见的按需分配缓存的模式。如下图,任何请求优先访问缓存,缓存命中,直接获得数据返回请求。如果未命中则,查询数据库,同时把结果写入缓存以备后续请求使用。
缓存我们使用的是Rides,是基于内存的,速度肯定比基于hdfs的Hbase快很多。
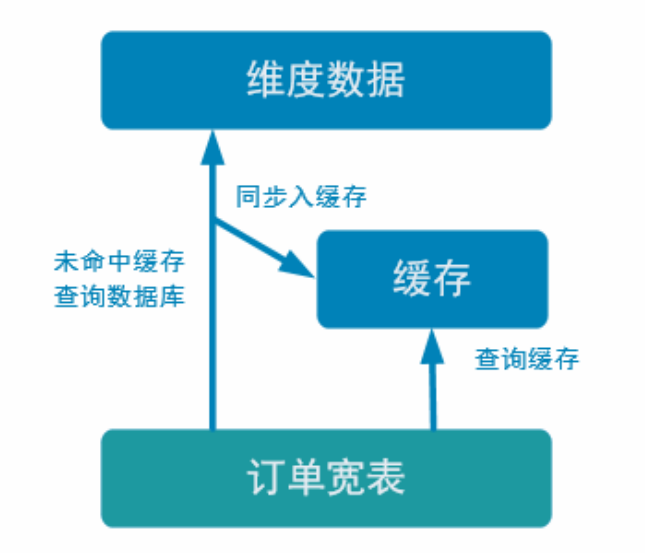
接下来说一下缓存的实现思路
缓存的选型
一般情况写有:堆缓存或者独立缓存服务(redis,memcache)
什么是堆缓存
堆缓存,从性能角度看更好,毕竟访问数据路径更短,减少过程消耗。但是管理性差,其他进程无法维护缓存中的数据,因为我们的服务都是独立的进程。相当于我们在堆内存中加入一个Map,key作为键,值就是一行数据,如果任务挂掉,缓存数据全部失效。
另外,堆缓存可能存在大量的数据冗余,因为堆缓存中,其他进程无法维护堆缓存中数据,所以其他的进程中也需要保存一份堆缓存中的数据,比如有多条业务线,订单中有用户信息,支付中有用户信息,这样还需要考虑线程的安全问题,所以提高了系统的复杂程度。
用Rides中只存在一份数据即可,但是用堆缓存服务,每一个进程中都需要存储用户信息。
但是也可以使用堆缓存和Rides结合的方式,这就相当于多级缓存模式,最热点的数据存储在堆缓存,堆缓存没有的数据去Rides中查询。堆缓存往往是LRU缓存。
独立缓存服务(redis,memcache)本事性能也不错,不过会有创建连接、网络 IO 等消耗。但是考虑到数据如果会发生变化,那还是独立缓存服务管理性更强,而且如果数据量特别大,独立缓存更容易扩展。
因为咱们的维度数据都是可变数据,所以这里还是采用 Redis 管理缓存。
那么缓存具体用来做那些工作
对于本项目的缓存,有三件事情,
- 读缓存,也就是查询数据的时候,先去缓存中查询。
- 写缓存,当缓存中数据不存在,就去HBASE中查询,查询到后首先写入缓存中,然后在返回结果。
- 最后是删除缓存,也就是数据发生不一致的时候,需要从缓存中删除数据。
那么具体在Rides中选用什么数据类型呢
首先考虑三种,String,Set,Map
如果选用String类型的键:String:tableName+id,那么主键就是表名和id,可以唯一确定一条数据吧,不同的表中可能存在相同的id,所以需要添加表名,这是一种可行的方案。
Set:tableName 使用set的话,使用的是表名主键,如果查询一张维度表,会把维度表中所有数据全部查出来,所以不适用set方式,显然不是我们需要的结果。
Hash:tableName+id 外面的key存储表名字,内部的key存储id,value存储值,也可以查询到数据,外部的map指的是hashmap存储一个表的名字,内部是rides有自己的key,可以存储id,value存储数据,也可以定位数据。
那么具体我们选用哪一种方式呢?
为什么不选Hash方式?
- 用户维度数据量大,因为Rides是扩展集群,不是我们经常说的master-slave模式,比如我们有三条数据,1,2,3,那么分别发散到Rides集群的三台机器上,但是如果用map形式,就可能把数据全部分到一台机器上面,造成某一太机器数据量非常的大,成为热点机器,所以我们使用string作为键,将数据大三到不同的机器
- 第二个是数据有过期时间,如果使用map,那么他的键是表的名字,如果过期,那么一张表中的所有数据全部过期了,同时所有查询数据全部过期,就像雪崩了一样,全部会落到Hbase的查询,但是实际上,我们希望每一条数据都有一个各自的过期时间,显然map做不到。防止同一时间,所有数据全部过期的问题。
不选set是因为查询不方便,因为每一次查询都会查询出所有的数据。
加入Rides缓存后,我们的代码思路变为:
- 如果想要根据数据流中的id去查询某一条数据,那么先去Rides缓存中查询是否存在数据,如果数据存在,那么可以直接返回即可。
- 如果数据不存在,那么就去Hbase中查询数据,查询到数据首先写入Rides中,然后在返回。
- 如果是更新数据,那么需要判断更新的数据是否存在于Rides数据库中,如果存在,需要把Rides中的数据删除,防止数据发生不一致问题。
总的来说,Rides需要做三件事:
- 读缓存,也就是查询数据的时候,先去缓存中查询。
- 写缓存,当缓存中数据不存在,就去HBASE中查询,查询到后首先写入缓存中,然后在返回结果
- 最后是删除缓存,也就是数据发生不一致的时候,需要从缓存中删除数据。
这三部每一步做完都需要重新设置我们Rides中每一条数据的过期时间,过期后自动清除。
异步IO
再做异步IO前我们还又一种方案,就是提高并行度,但是这样需要更多的资源,比如更多task,内存,数据库连接等等。所以我们使用异步IO。
如何使用异步IO
- 继承RichAsyncFunction类
- 实现asyncInvoke方法发送请求。
- 实现AsyncDataStream将产生的结果作用到流上。
- unorderedWait:是说异步产生的结果是否保持原来的顺序,因为异步发送请求,有的请求可能处理慢,所以返回时间晚,那么使用这个方法的话,就是说不保证产生结果的顺序,如果对顺序没有要求,可以使用。
- Unordered:异步结果按照顺序到达。
支付宽表实现思路
为什么需要支付宽表
支付宽表的目的,最主要的原因是支付表没有到订单明细,支付金额没有细分到商品上,没有办法统计商品级的支付状况。
两种解决方案
- 一个是把订单宽表输出到 HBase 上,在支付宽表计算时查询 HBase,这相当于把订单宽表作为一种维度进行管理。
- 一个是用流的方式接收订单宽表,然后用双流 join 方式进行合并。因为订单与支付产生有一定的时差。所以必须用 intervalJoin 来管理流的状态时间,保证当支付到达时订单宽表还保存在状态中。
选用的哪一种方案
在这里我们选用第二种方式,因为订单和支付中间不是连续的,可能下订单了,但是过了15分钟后支付,而这需要保存为一个状态,如果这个状态使用双流join,只需要将状态保存15分钟即可,但是Hbase默认是永久保存的,但是这里并不需要永久保存状态。
另一个原因是如果把订单宽表作为维度表去查询,因为这个表很大,查询延迟必然很高。
使用kafka双流Join效率高,实现起来相对容易。订单宽表本来是在kafka中,没必要再写入hbase中作为宽表处理,这样增加了难度和复杂度。
贡献者
 codingLab
codingLab版权所有
版权归属:
许可证: